














This tutorial will walk you through how to setup a working environment for multi-GPU training with Horovod and Keras.
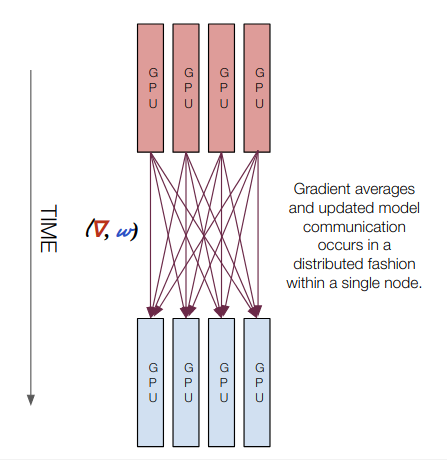
This presentation is a high-level overview of the different types of training regimes you'll encounter as you move from single GPU to multi GPU to multi node distributed training. It describes where the computation happens, how the gradients are communicated, and how the models are updated and communicated.

BERT is Google's SOTA pre-training language representations. This blog is about running BERT with multiple GPUs. Specifically, we will use the Horovod framework to parrallelize the tasks. We ill list all the changes to the original BERT implementation and highlight a few places that will make or break the performance.
...