A Gentle Introduction to Multi GPU and Multi Node Distributed Training
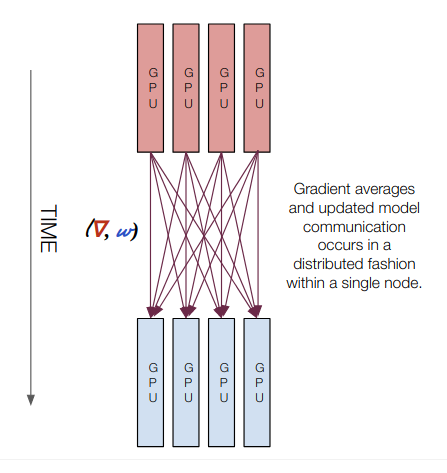
This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi ...
This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi ...