
In this blog, Lambda showcases the capabilities of NVIDIA’s Transformer Engine, a cutting-edge library that accelerates the performance of transformer models on NVIDIA GPUs during both training and inference phases. Transformer Engine leverages the prowess of 8-bit floating point (FP8) precision on the latest NVIDIA Hopper and Ada Lovelace architecture GPUs, which significantly accelerates performance while reducing memory consumption. The below provides an overview of the Transformer Engine’s FP8 capabilities on NVIDIA H100 Tensor Core GPUs, as well as the Transformer Engine’s software library capabilities with legacy bfloat (BF16) support on NVIDIA A100 Tensor Core GPUs.
TL;DR
- The Transformer Engine supports FP8 precision on NVIDIA Hopper and Ada Lovelace architecture GPUs, and the Transformer Engine’s software library supports other precisions (e.g., FP16, BF16) on legacy NVIDIA Ampere architecture GPUs.
- Our testing with GPT3-style models on the NVIDIA H100 GPU reveals that the Transformer Engine alone boosts FP8 performance by an impressive 60%.
- With the Transformer Engine, the H100 GPU achieves 3x the speed of the A100 GPU, which leverages the Transformer Engine’s software library support for BF16.
Background
Introduced with the NVIDIA Hopper architecture and extended to the NVIDIA Ada Lovelace architecture, the Transformer Engine boasts several key features that drive optimal performance:
- Fourth-generation Tensor Cores capable of FP8 operations, offering double the computational throughput of 16-bit operations.
- Custom heuristics for intelligent precision selection between FP8 and FP16, with automatic re-casting and scaling across neural network layers.
- A framework-agnostic C++ API compatible with major deep learning libraries such as PyTorch, JAX, and TensorFlow.
Benchmarks with NVIDIA H100 and A100 GPUs
Using BF16 as the baseline precision, we first evaluated the speedup from the Transformer Engine’s software library, which supports BF16 precision on NVIDIA H100 and A100 GPUs, and then evaluated the speed up from the Transformer Engine’s FP8 precision on H100 GPUs. Our hardware setup included 8 NVIDIA H100 SXM GPUs, with GPT implementations sourced from the NVIDIA NeMo framework.
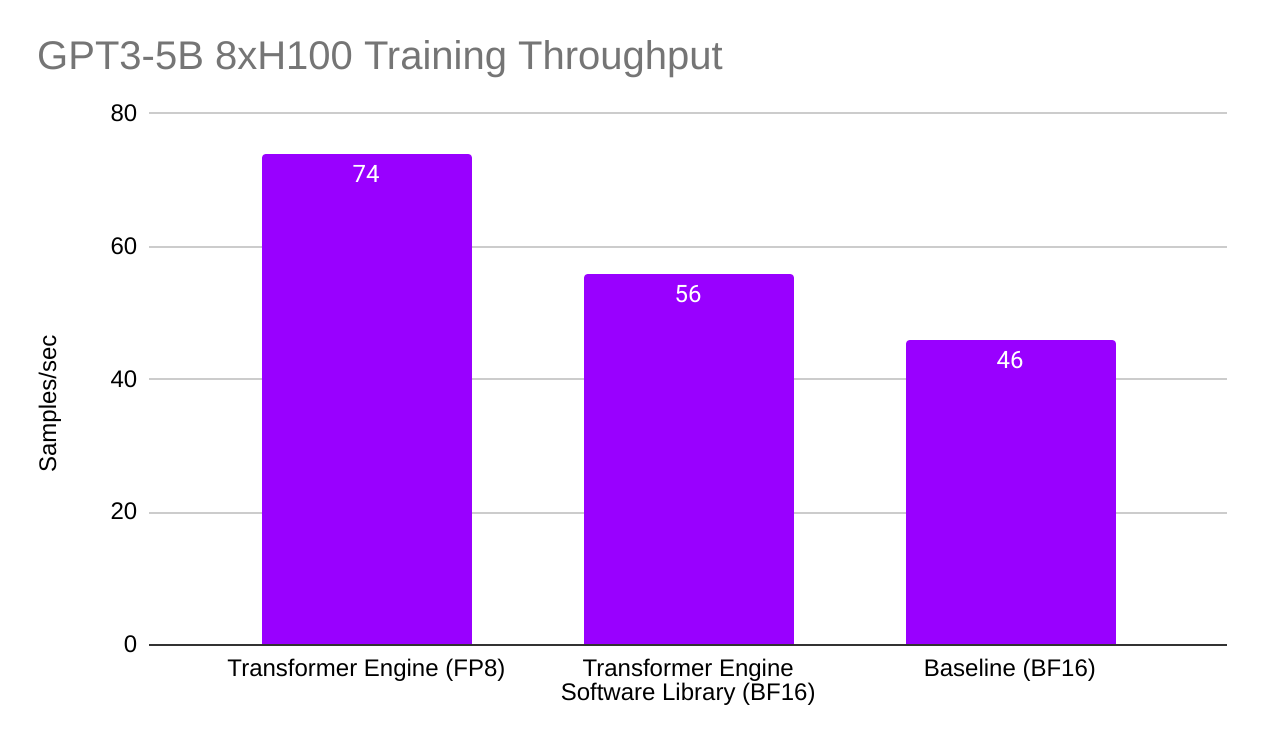
Results indicated a 22% speedup over the BF16 baseline when training a 5B-parameter GPT3-style model using the Transformer Engine’s software library. This improvement jumped to 61% when using the Transformer Engine’s FP8 capabilities, unlocking a significant reduction in memory footprint, allowing for a quadrupled micro batch size during training.
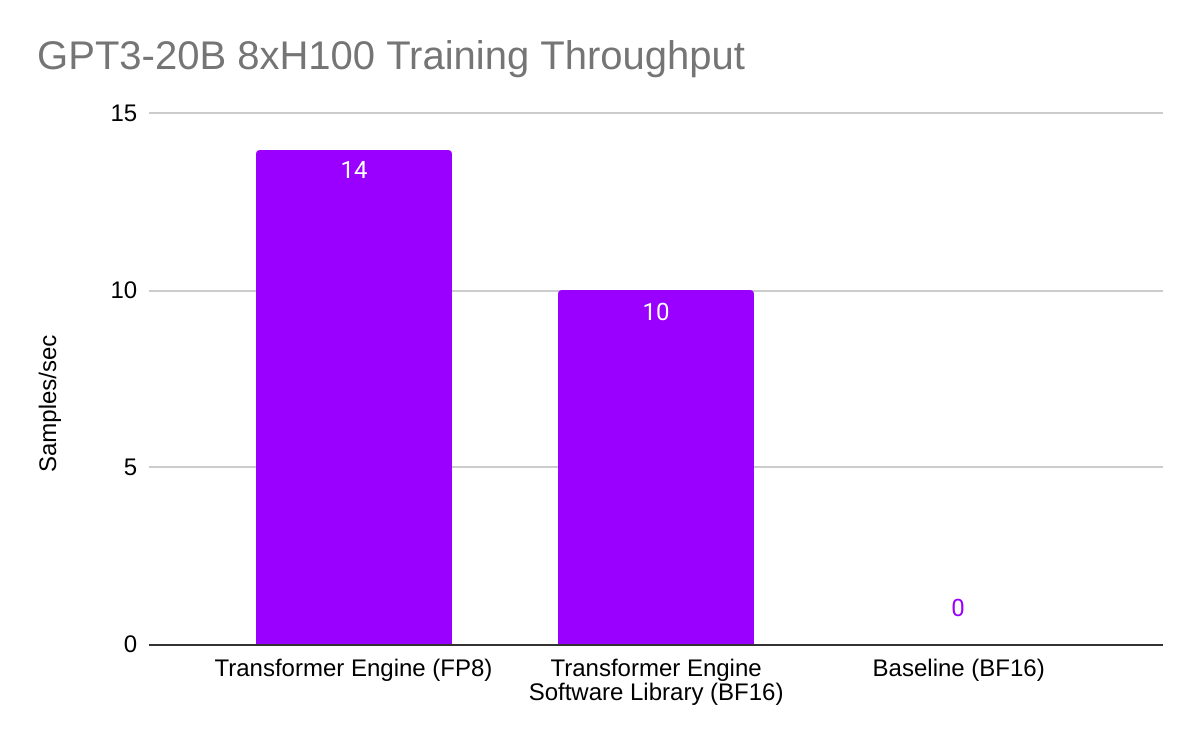
For larger 20B-parameter models, the Transformer Engine's memory footprint reduction was even more pronounced, as the baseline BF16 configuration could not support the model due to memory limitations.
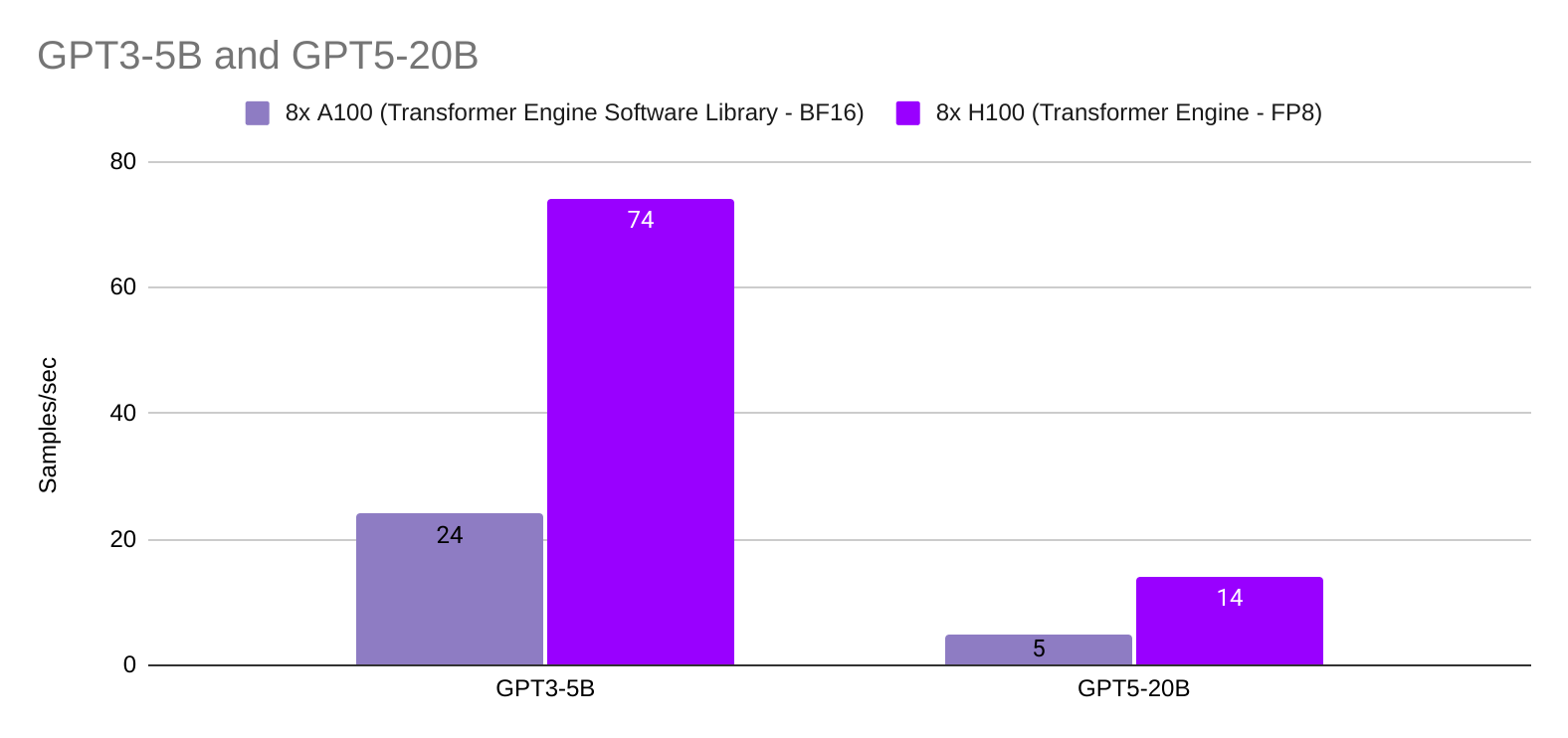
Lastly, when comparing the performance of the NVIDIA H100 to that of the A100 GPU, we observed approximately a 3x speedup for both 5B and 20B models using the H100 with the Transformer Engine (FP8) versus the A100 with the Transformer Engine’s software library (BF16).
Conclusion
NVIDIA’s Transformer Engine is a game-changer for running transformer models, particularly in the realm of large language models. The support for FP8 precision on the latest NVIDIA GPUs translates into remarkable performance gains and memory savings. The engine not only facilitates a substantial speedup in training times but also enables the use of significantly larger models that were previously constrained by memory limitations.