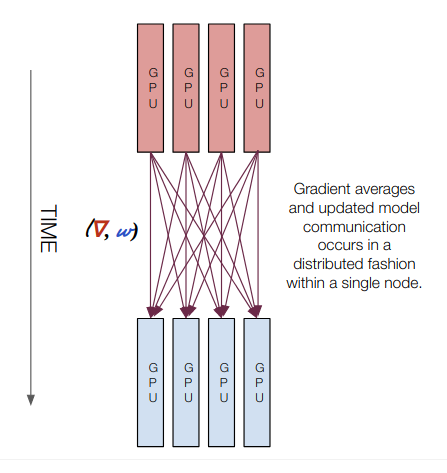
A Gentle Introduction to Multi GPU and Multi Node Distributed Training
This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi ...
This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi ...
Update June 5th 2020: OpenAI has announced a successor to GPT-2 in a newly published paper. Checkout our GPT-3 model overview.

Deep Learning requires GPUs, which are very expensive to rent in the cloud. In this post, we compare the cost of buying vs. renting a cloud GPU server. We use ...