
GPU benchmarks on Lambda’s offering of the NVIDIA H100 SXM5 vs the NVIDIA A100 SXM4 using DeepChat’s 3-step training example.
Table of Contents
Goals
We’ve run an exciting benchmark test on Lambda’s offering of the NVIDIA H100 SXM5 instance, powered by NVIDIA H100 Tensor Core GPUs, using DeepChat’s 3-step training example. We compare the performance with a reference NVIDIA A100 SXM4 Tensor Core system and stress-test its scalability on a whopping 1,024 GPUs across 128 servers.
Specs
- Each server has 8x NVIDIA H100 SXM5 GPUs and 8x 400Gb/s NDR InfiniBand links. That’s 640GB of GPU memory and a 3200Gb/s inter-node bandwidth.
- Leveraging a fully non-blocking rail-optimized network topology, we’ve maxed out all-reduce performance and reduced network clashes, ensuring greater than 750Gbit/s InfiniBand performance between servers, measured by the bidirectional ib_write_bw test between a pair of InfiniBand ports.
- All servers have Lambda Stack, InfiniBand drivers, and deepspeed 0.10.0 pre-installed and are synced to shared storage for training data and pre-trained weights.
Key Results
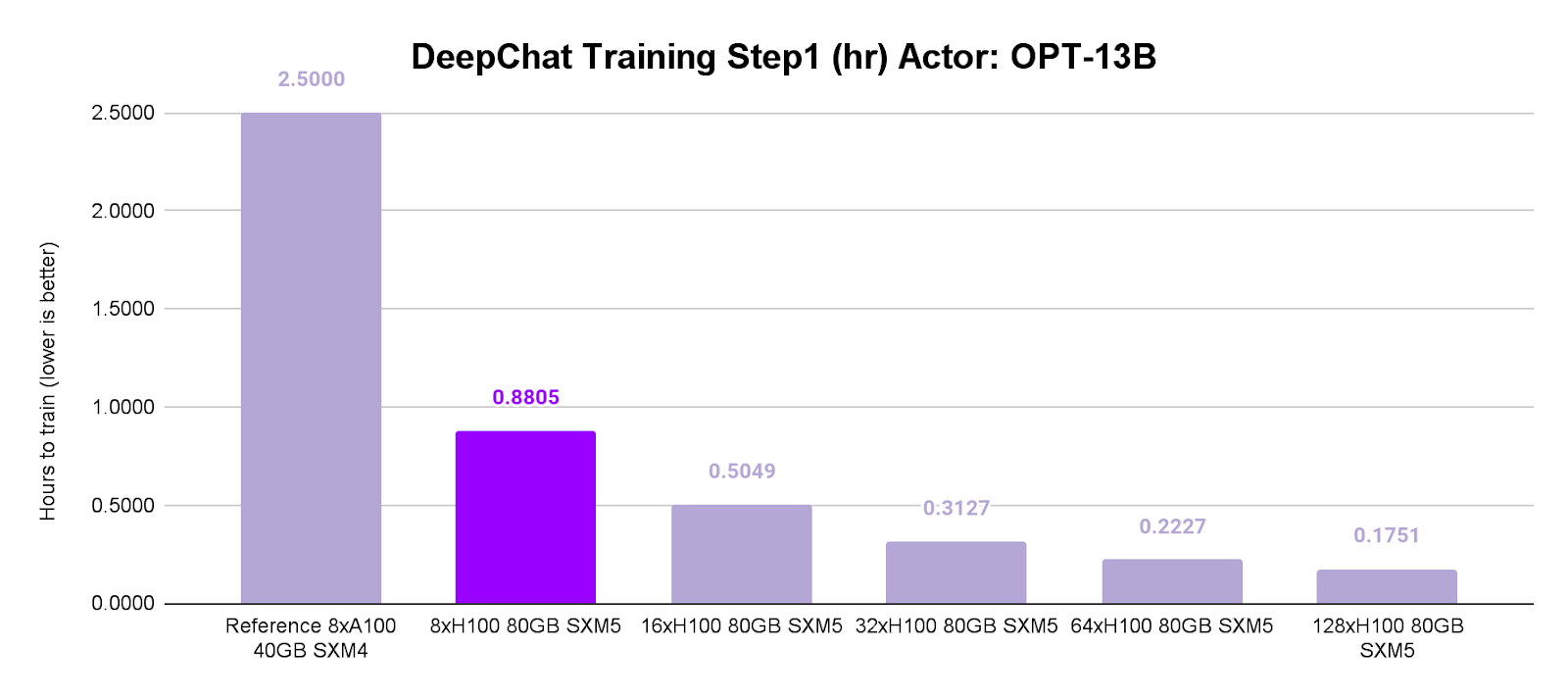
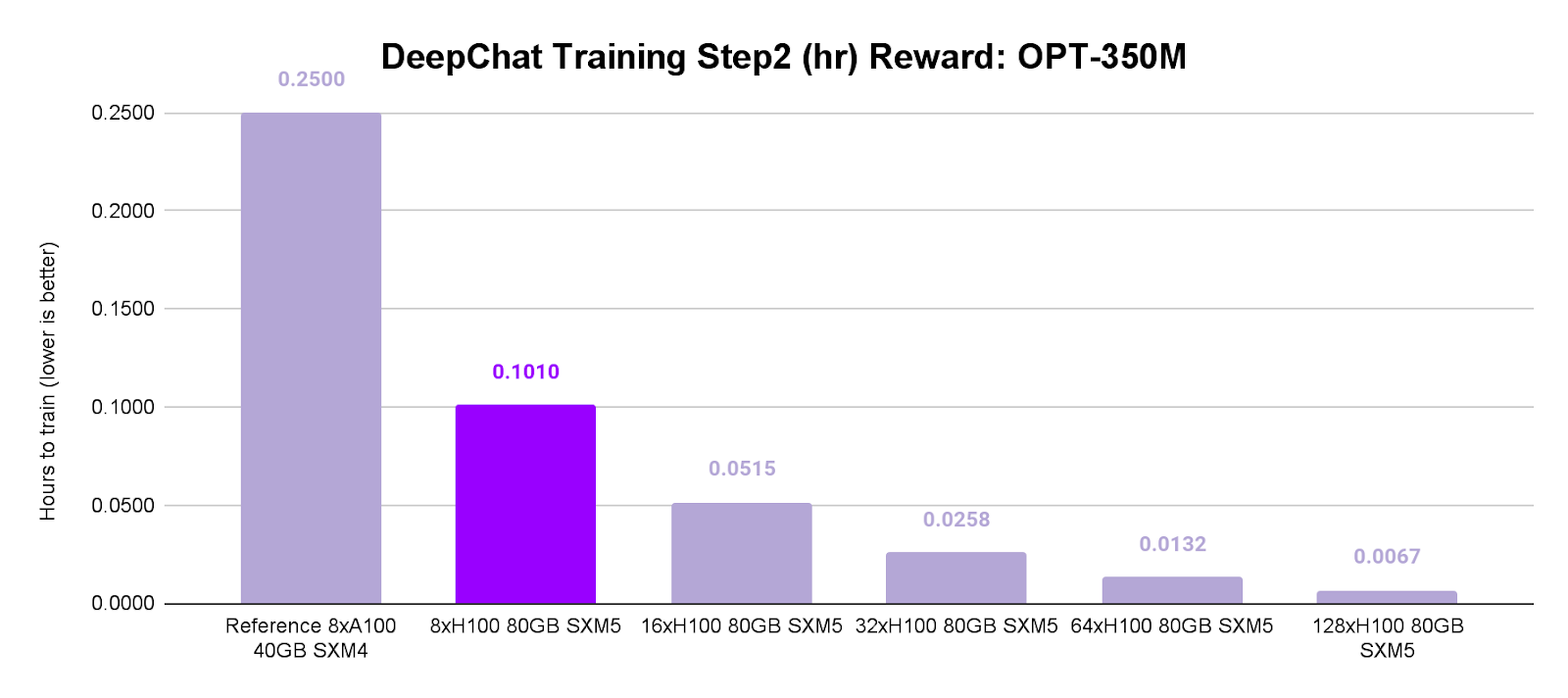
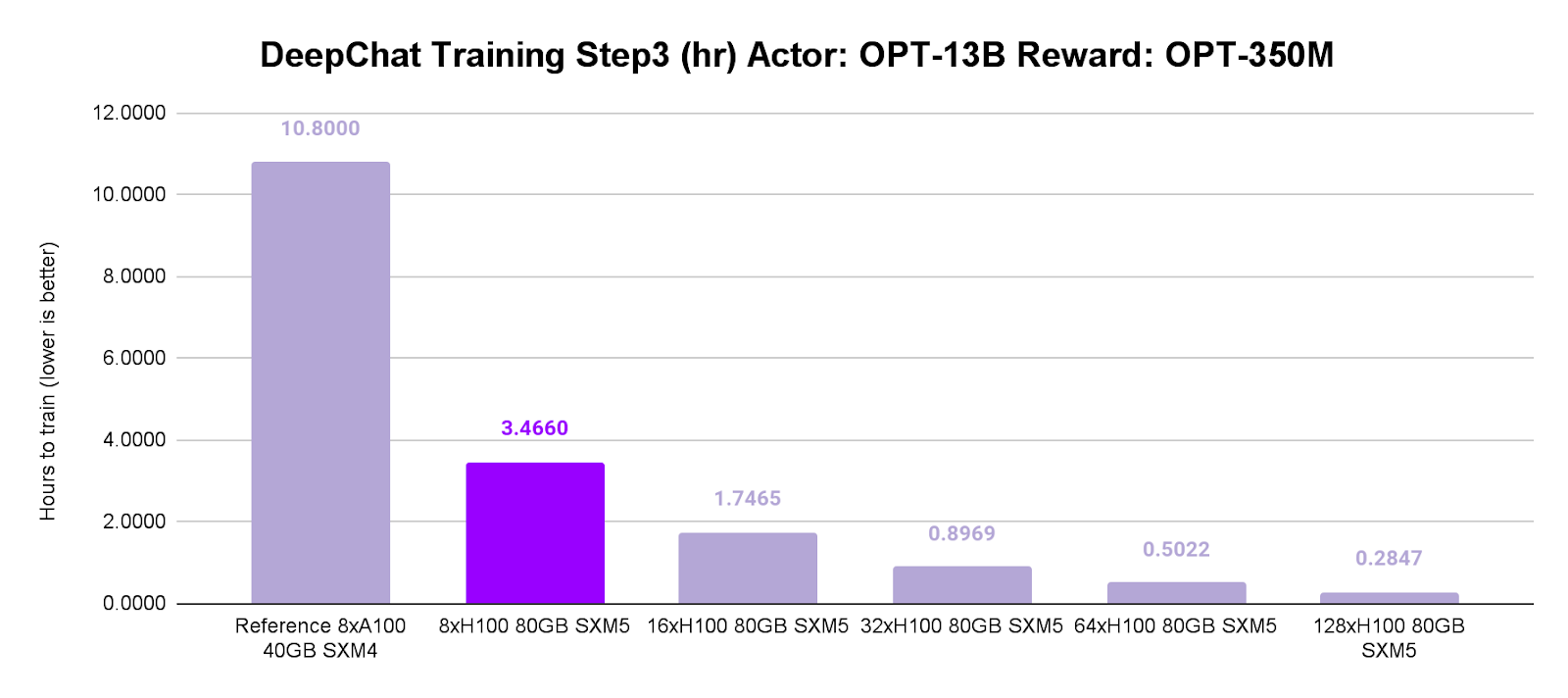
The head-to-head comparison between Lambda’s NVIDIA H100 SXM5 and NVIDIA A100 SXM4 instances across the 3-step Reinforcement Learning from Human Feedback (RLHF) Pipeline in FP16 shows:
-
Step 1 (OPT-13B Zero3): NVIDIA H100 was 2.8x faster.
-
Step 2 (OPT-350M Zero0): NVIDIA H100 clinched a 2.5x speed advantage.
-
Step 3 (OPT-13B Zero3 plus OPT-350M Zero0): NVIDIA H100 raced ahead with a 3.1x speed boost.
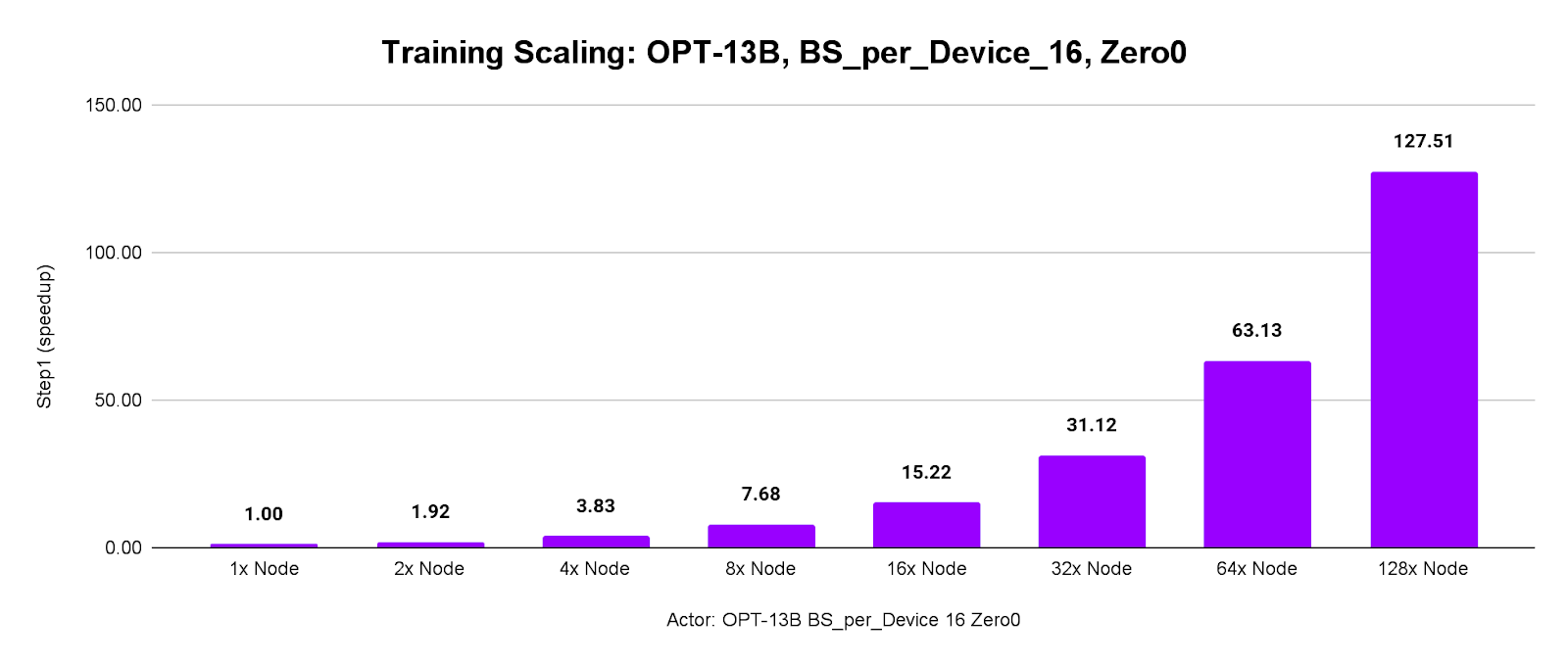
Testing distributed training scalability:
-
Large model (OPT-13B) and bigger batches (16 samples/GPU) resulted in a 127.51x throughput from 128 servers.
-
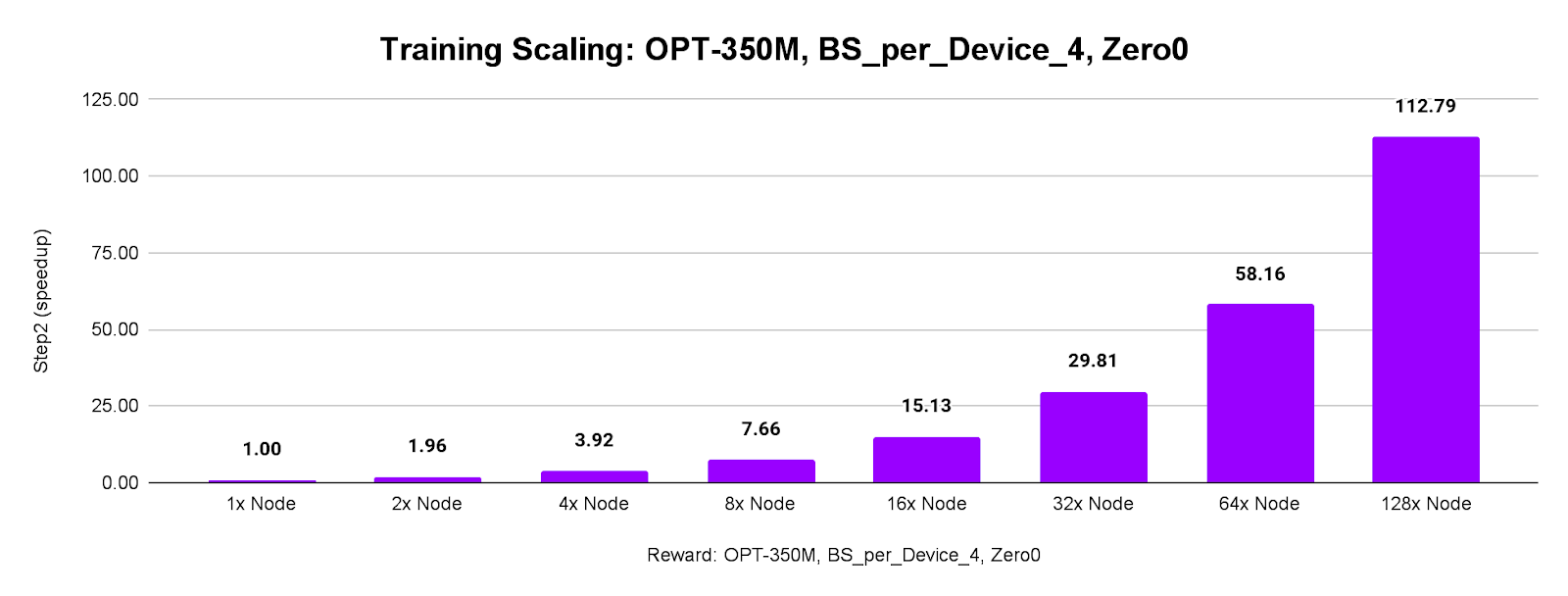
Smaller model (OPT-350M) and smaller batches (4 samples/GPU) still impressed with a 112.79x throughput from 128 servers.
Takeaway
DeepSpeed training on the NVIDIA H100 SXM5 system shows a speedup of between 2.5x-3.1x compared to on the NVIDIA A100 SXM4 system. Lambda Cloud Clusters feature 80GB NVIDIA H100 SXM5 GPUs, InfiniBand connection with 1:1 NIC-to-GPU ratio, and rail-optimized networking. They can deliver unprecedented performance and scalability on thousands of GPUs.
Learn more and reach out to the Lambda team to reserve your allocation.