This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi node distributed training. It briefly describes where the computation happens, how the gradients are communicated, and how the models are updated and communicated. In addition, a visualization of the system is provided. You can download the full PDF presentation here.
Deep Learning Training Regimes
Single GPU
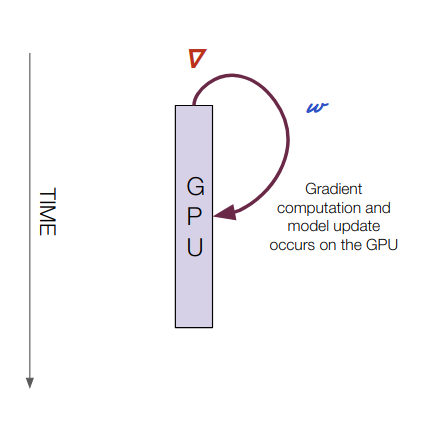
Computation Happens: On one GPU
Gradient transfers: N/A
Model transfers: N/A
Multi GPU Training (CPU Parameter Server)
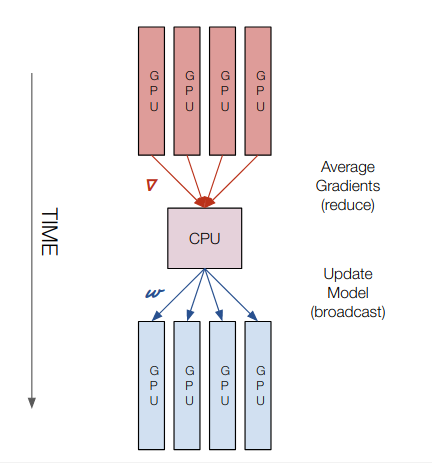
Computation Happens: On all GPUs and CPU
Gradient transfers: From GPU to CPU (reduce)
Model transfers: From CPU to GPU (broadcast)
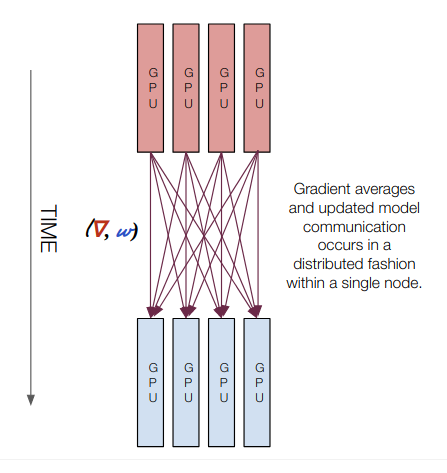
Multi GPU Training (Multi GPU all-reduce)
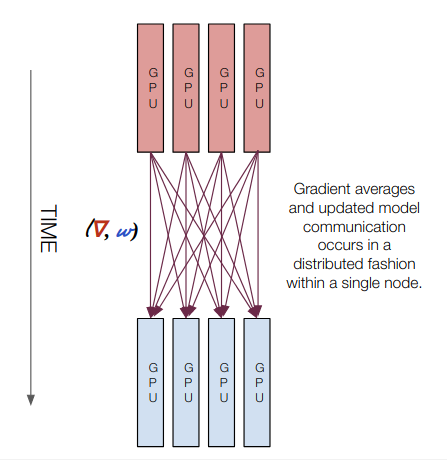
Computation Happens: On all GPUs
Gradient transfers: GPU to GPU during NCCL all-reduce
Model transfers: GPU to GPU during NCCL all-reduce
Asynchronous Distributed SGD
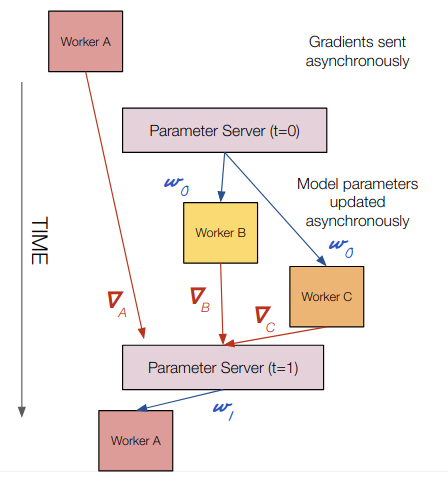
Computation Happens: On all workers and parameter servers
Gradient transfers: Worker to parameter server (asynchronously)
Model transfers: Parameter server to worker (asynchronously)
Synchronous Distributed SGD
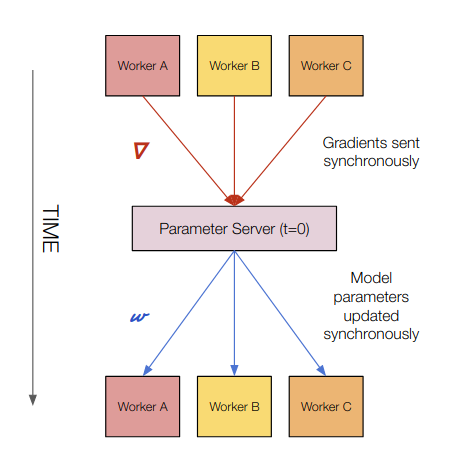
Computation Happens: On all workers and parameter servers
Gradient transfers: Worker to parameter server
Model transfers: Parameter server to worker
Multiple Parameter Servers
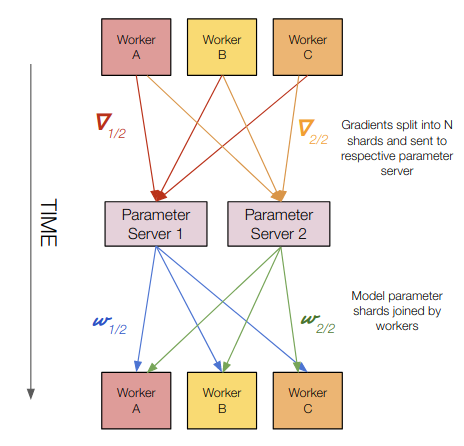
Computation Happens: On all workers and parameter servers
Gradient transfers: Worker gradient shards to parameter servers
Model transfers: Parameter server model shards to workers
Ring all-reduce Distributed Training
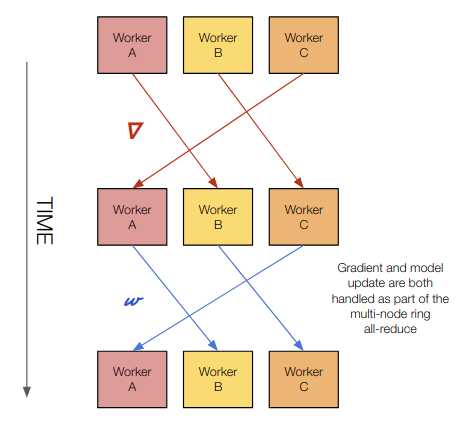
Computation Happens: On all workers
Gradient transfers: Worker transfers gradient to peers during all-reduce
Model transfers: Model “update” happens at the end of multi-node all-reduce operation
Hardware Considerations
When scaling up from a single GPU to a multi-node distributed training cluster, in order to achieve full performance, you'll need to take into consideration HPC-style hardware such as NVLink, InfiniBand networking, and GPUs that support features like GPU Direct RDMA.
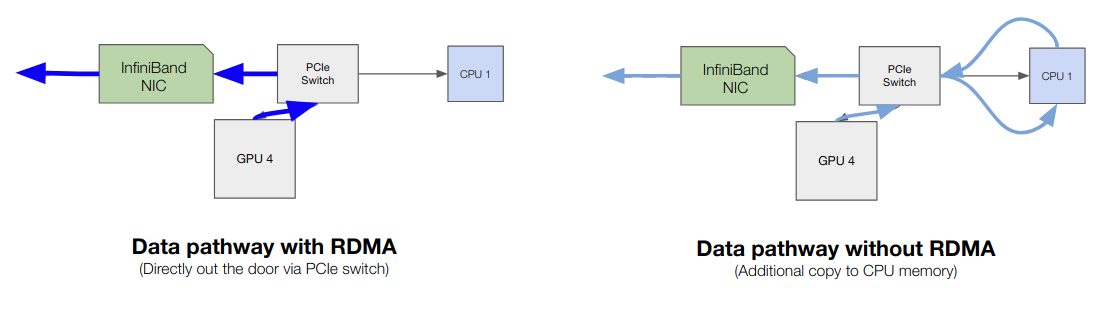
Traditionally, transferring memory from a GPU on node 1 to a GPU on node N would involve a memory copy from the GPU to the CPU on node 1, a copy from the CPU on node 1 to the NIC on node 1 and then out the door. GPU Direct RDMA (Remote Direct Memory Access), a feature only available on the TESLA line of cards, you can skip the "double copy" and go directly from GPU memory out the door using an InfiniBand card.
GPU RDMA over InfiniBand
The two data pathways for GPU memory transfer (with and without RDMA) are visualized below:
Hardware Configuration for Multi-node all-reduce
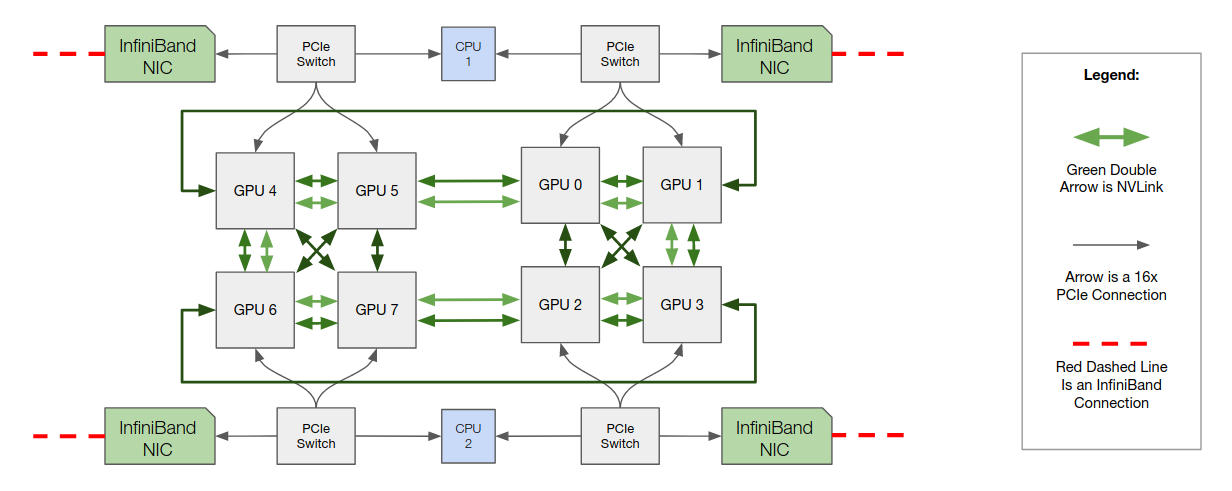
The Lambda Hyperplane V100 server is designed to enable GPU Direct RDMA and node-to-node communication bandwidth of ~42GB/s. (4 Adapters per Node * 100 Gb/s per Adapter / 8 bits per byte = 50 GB/s theoretical peak.)
Inter-node Bandwidth with GPU Direct RDMA
The board design above combined with the GPU Direct RDMA capabilities of the InfiniBand adapters and the NVIDIA V100 GPUs allows for the measured bandwidth between nodes to reach 42GB/s, 84% of theoretical peak.

This type of distributed training is useful for large scale image, language, and speech models such as NasNet, BERT, and GPT-2.
Citations
- Sergeev, Alexander and Mike Del Balso. Horovod: fast and easy distributed deep learning in TensorFlow. https://arxiv.org/pdf/1802.05799.pdf
- Pitch Patarasuk and Xin Yuan. Bandwidth optimal all-reduce algorithms for clusters of workstations. J. Parallel Distrib. Comput., 69:117–124, 2009. https://www.cs.fsu.edu/~xyuan/paper/09jpdc.pdf
- Jeaugey, Sylvain. NCCL 2.0. (2017). http://on-demand.gputechconf.com/gtc/2017/presentation/s7155-jeaugey-nccl.pdf
- WikiChip NVLink. https://fuse.wikichip.org/news/1224/a-look-at-nvidias-nvlink-interconnect-and-the-nvswitch/
Additional thanks to Chuan Li and Steve Clarkson.