
This blog explores the synergy of DeepSpeed’s ZeRO-Inference, a technology designed to make large AI model inference more accessible and cost-effective, with the NVIDIA GH200 Grace Hopper Superchip, which transforms AI inference.
TL;DR
- A single NVIDIA GH200, enhanced by ZeRO-Inference, effectively handles LLMs up to 176 billion parameters.
- It significantly improves inference throughput compared to a single NVIDIA H100 or A100 Tensor Core GPU.
- The superchip’s GPU-CPU 900GB/s bidirectional NVLink Chip-to-Chip (C2C) bandwidth is key to its superior performance.
NVIDIA GH200 Grace Hopper Superchip
NVIDIA GH200 combines the NVIDIA Grace CPU and Hopper architecture GPU, connected by a high-bandwidth NVIDIA NVLink-C2C interconnect running at a 900 GB/s bidirectional bandwidth. Additionally, Address Translation Services (ATS) allow CPU and GPU to share a single per-process page table, facilitating seamless memory access for both.
ZeRO-Inference
ZeRO-Inference reduces GPU costs of large AI models. It allows single GPU inference of massive models by offloading model weights to CPU memory or NVMe, reducing costs and making advanced AI models more accessible.
NVIDIA GH200 Benchmark
Our hypothesis is that ZeRO-Inference can leverage the NVIDIA GH200’s remarkably high bandwidth NVLink-C2C for CPU-offload, hence improving the overall performance of inference on large language models.
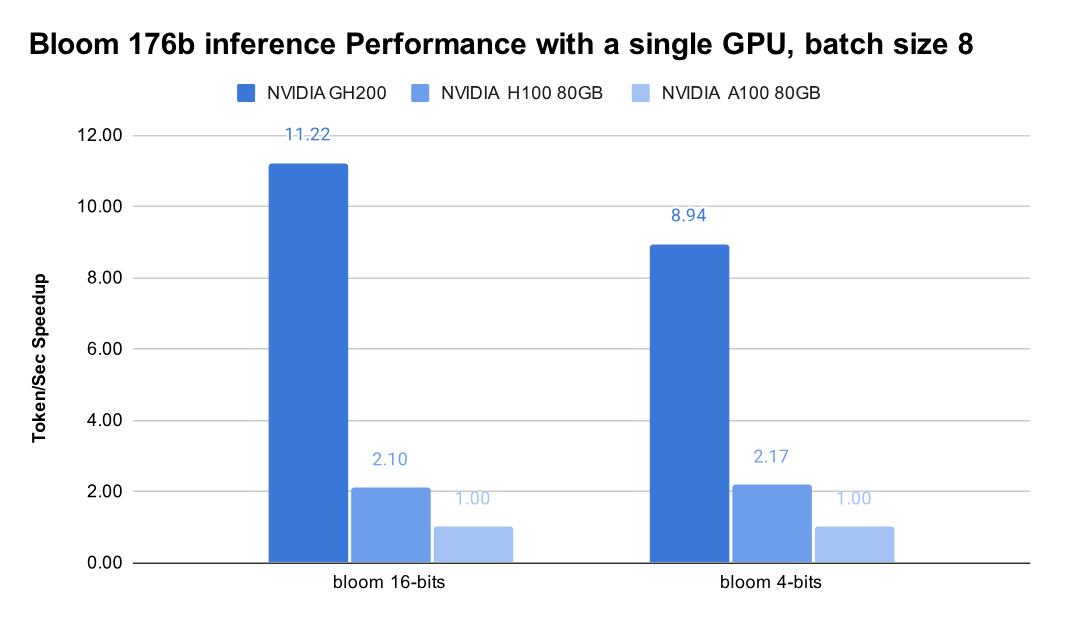
We first tested the Bloom 176b model with CPU-offload, where the NVIDIA GH200 Grace Hopper Superchip achieved significantly higher throughput compared to H100 and A100 GPUs, showcasing the benefits of its high bandwidth. Specifically, the GH200 produces 4-5x inference throughput of H100, and 9-11x inference throughput of A100, thanks to its significantly higher chip-to-chip bandwidth that removed the communication bottleneck for CPU-offload.
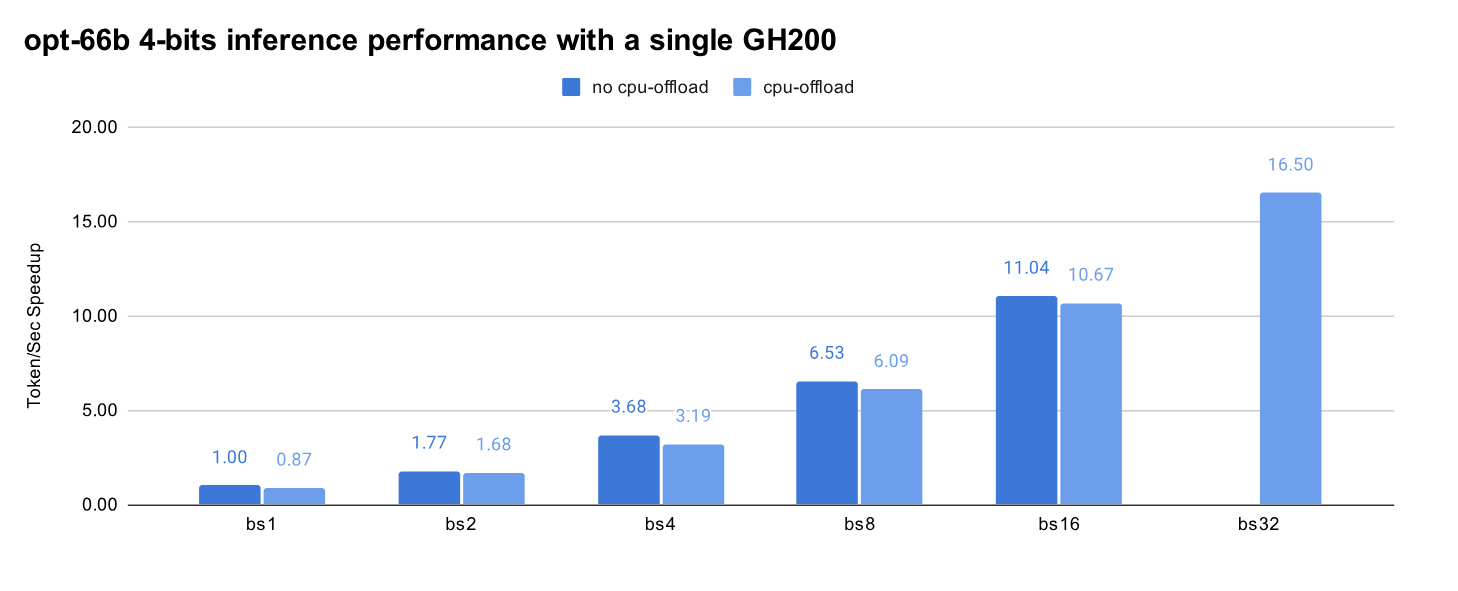
Our second benchmark tested the throughput with/without CPU-offload on the GH200, and saw if CPU-offload can produce overall higher throughput. The figure below shows that when the same batch size is used, CPU-offload inference indeed slightly reduces the throughputs. Nonetheless, CPU-offload also enables running inference with larger batch size (in this case, 32) and produces overall the highest throughput, 1.5x the highest throughput of inference without CPU-offload (using batch size 32, compared to batch size 16, the max without offload).
Conclusion
Our benchmark showed that efficient memory management is crucial for high throughput serving of large language models as it allows for batching of requests and reduces wasted memory. ZeRO-Inference, powered by the NVIDIA GH200 Grace Hopper Superchip, marks a major leap in AI inference technology. As AI models grow in size, this combination is increasingly essential, democratizing access to advanced AI models and opening new possibilities for computational efficiency and scalability.