














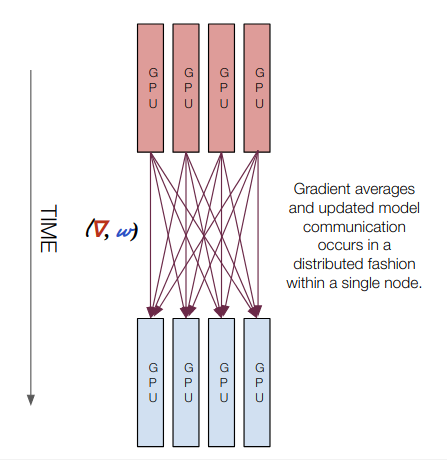
This presentation is a high-level overview of the different types of training regimes you'll encounter as you move from single GPU to multi GPU to multi node distributed training. It describes where the computation happens, how the gradients are communicated, and how the models are updated and communicated.