Multi-GPU enabled BERT using Horovod

BERT is Google's pre-training language representations which obtained the state-of-the-art results on a wide range of Natural Language Processing tasks. However, the official TPU-friendly implementation has very limited support for GPU: the code only runs on a single GPU at the current stage.
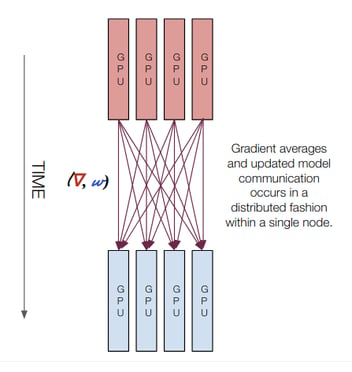
This blog is about making BERT work with multiple GPUs. Specifically, we will use Uber's Horovod framework to parallelize the tasks. We will list all the changes to the original BERT implementation and highlight a few places that will make or break the performance.
You can jump to our multi-GPU-ready fork from here. Here is some sampled performance:
| Task | Single GPU Throughput |
2 GPUs Throughput |
4 GPUs Throughput |
|---|---|---|---|
| Sentence classification (3 epochs) |
70.78 | 126.92 | 231.26 |
| SQuAD 1.1 (2 epochs) |
30.20 | 53.53 | 90.07 |
| Task | Single GPU Accuracy |
2 GPUS Accuracy |
4 GPUs Accuracy |
|---|---|---|---|
| Sentence classification (3 epochs) |
0.850 | 0.855 | 0.852 |
| SQuAD 1.1 (2 epochs) |
"e_m": 79.85, "f1": 86.62 |
"e_m": 79.97, "f1": 87.67 |
"e_m": 79.32, "f1": 86.54 |
- GPU is 1080Ti (11GB VRAM)
- Throughput is measured as examples/sec.
- We didn't tune hyper-parameters (learning rate) for different numbers of GPUs. To avoid out-of-memory errors, we used BERT-base and a smaller max_seq_length (256) to train SQuAD 1.1. As a consequence, the resulting accuracies are slightly lower than the reference performance produced on TPUs.
Make it Work
This section will walk you through all the necessary steps to adapt BERT for multiple GPUs. In particular, we will leverage Horovod for parallelization. If this is your first ever encounter with Horovod, we also recommend this excellent tutorial as a starting point to learn Horovod's high-level concepts.
The main scripts for BERT are run_classifier.py, run_squad.py and run_pretraining. Most of the changes will be made into these scripts, and the changes are similar among them.
Let's use run_classifier.py as an example. Here are all the changes for making it multi-GPU-ready:
# Changes in run_classifier_hvd.py
// Change 1
import horovod.tensorflow as hvd
def main(_):
// Change 2
hvd.init()
// Change 3
FLAGS.output_dir = FLAGS.output_dir if hvd.rank() == 0 else os.path.join(FLAGS.output_dir, str(hvd.rank()))
...
// Change 4
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
run_config = tf.contrib.tpu.RunConfig(
...,
session_config=config)
...
// Change 5
if FLAGS.do_train:
...
num_train_steps = num_train_steps // hvd.size()
num_warmup_steps = num_warmup_steps // hvd.size()
// Change 6
if FLAGS.do_train:
...
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps, hooks=hooks)
There are also some changes to be made to optimization.py, which is used by the main scripts:
# Changes in optimization_hvd.py
// Change 7
import horovod.tensorflow as hvd
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
...
// Change 8 (optional)
optimizer = AdamWeightDecayOptimizer(
learning_rate=learning_rate * hvd.size(),
...)
// Change 9
optimizer = hvd.DistributedOptimizer(optimizer)
// Change 10
grads_and_vars=optimizer.compute_gradients(loss, tvars)
// Change 11
grads = [grad for grad,var in grads_and_vars]
tvars = [var for grad,var in grads_and_vars]
(grads, _) = tf.clip_by_global_norm(grads, clip_norm=1.0)
// Change 12
train_op = optimizer.apply_gradients(zip(grads, tvars), global_step=global_step)
Let's explain the changes one by one:
- Change 1: Import Horovod's Tensorflow backend.
- Change 2: Initialize the library: basic bookkeeping, sets up communication between workers, allocates buffers etc.
- Change 3: Use different output directories for different workers.
- Change 4: Pin each worker to a GPU (make sure one worker uses only one GPU).
- Change 5: The training steps for each worker is the total steps divided by the number of workers.
- Change 6: Ensure all workers start with the same weights.
- Change 7: Same as Change 1, import Horovod's Tensorflow backend.
- Change 8: Optionally, scale learning rate by the number of GPUs.
- Change 9: Wrap the original optimizer by Horovod's distributed optimizer, which handles all the under the hood
allreducecalls. Notice Horovod only does synchronized parameter update. - Change 10: Using the distributed optimizer to compute gradient.
- Change 11: Adapt gradient clipping to the output of the distributed optimizer.
- Change 12: Apply the clipped gradient.
To use the modified main script with Horovod, one needs to add a few things before calling the main python script. For example, to run on a machine with 4 GPUs:
$ mpirun -np 4 \
-H localhost:4 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
python run_classifier_hvd.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=4.0 \
--output_dir=/tmp/mrpc_output/
Notes
We'd like to detail some of the above changes because there are not obvious to first time Horovod users.
Change 10: Using the distributed optimizer to compute gradient
This can be a pitfall that completely breaks the training. The original BERT implementation uses tf.gradients to compute the gradient, which is not wrapped by the Horovod optimizer. Keep using it will cause asynchronized models across different workers – each worker will train its own version of the networks. To avoid this we use optimizer.compute_gradients to ensure gradient aggregation.
Notice we also adapt gradient clipping accordingly (Change 11).
Change 3: Use different output directories for different workers
By default, all workers will write data (checkpoint etc) to the same directory. This will cause a corrupted record during training. Here we use a simple trick to let different workers write to different directories.
In fact, since Horovod uses synchronized parameter update, all workers will have exactly the same parameters. So one can further modify the BERT code to only save the output model from a single worker. However, we do not do this here for keeping the change minimal.
Change 8: Scaling learning rate by number of devices
This is a trick suggested by Facebook research for scaling up training across many workers. However, in practice, one should be cautious about applying it to specific problems. It caused significant performance drop in several tasks we tested. For this reason, we do not apply such learning rate scaling in all tests in this blog.
Demo
You can reproduce the results using our multi-GPU-ready fork of BERT:
git clone https://github.com/lambdal/bert.git