
Lambda Echelon – a turn key GPU cluster for your ML team
Introducing the Lambda Echelon Lambda Echelon is a GPU cluster designed for AI. It comes with the compute, storage, network, power, and support you need to ...
Introducing the Lambda Echelon Lambda Echelon is a GPU cluster designed for AI. It comes with the compute, storage, network, power, and support you need to ...
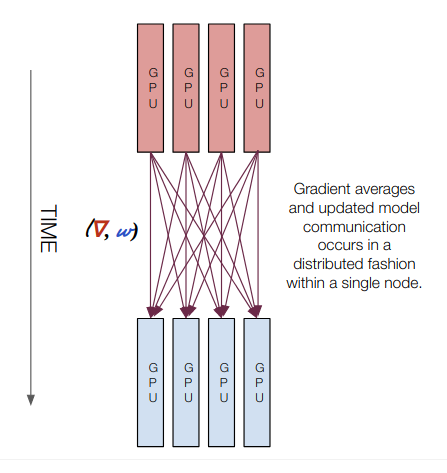
This presentation is a high-level overview of the different types of training regimes that you'll encounter as you move from single GPU to multi GPU to multi ...

BERT is Google's pre-training language representations which obtained the state-of-the-art results on a wide range of Natural Language Processing tasks. ...