

Deep Learning requires GPUs, which are very expensive to rent in the cloud. In this post, we compare the cost of buying vs. renting a cloud GPU server. We use AWS's p3dn.24xlarge as the cloud point of comparison. Here's what we'll do:
- Select a server with similar hardware to AWS's p3dn.24xlarge
- Compare Deep Learning performance of the selected server vs. the p3dn.24xlarge
- Compare the cost of the selected server vs. the p3dn.24xlarge
Selecting a server similar to a p3dn.24xlarge
We use the Lambda Hyperplane - Tesla V100 Server, which is similar to the NVIDIA's DGX-1. Here's a side-by-side hardware comparison with the p3dn.25xlarge:
| p3dn.24xlarge | Lambda Hyperplane | |
|---|---|---|
| GPU | 8x NVIDIA Tesla V100 (32 GB) | 8x NVIDIA Tesla V100 (32 GB) |
| NVLink | Hybrid Cube Mesh Topology | Hybrid Cube Mesh Topology |
| CPU | Intel Xeon P-8175M (24 cores) | Intel Xeon Platinum 8168 (24 cores) |
| Storage | NVMe SSD | NVMe SSD |
| Software | Deep Learning AMI (Ubuntu) Version 20.0 | Lambda Stack |
TL;DR
The purchased Tesla V100 Server...
- Is 2.6% faster than AWS's p3dn.24xlarge for FP32 training
- Is 3.2% faster than AWS's p3dn.24xlarge for FP16 training
- Has a Total Cost of Ownership (TCO) that's $69,441 less than a p3dn.24xlarge 3-year contract with partial upfront payment. Our TCO includes energy, hiring a part-time system administrator, and co-location costs. In addition, you still get value from the system after three years, unlike the AWS instance.
Cost Comparison: Total Cost of Ownership (TCO)
Let's break out the comparison based on the three choices you have from AWS for a 3-year contract: 0% upfront, partial upfront, and 100% upfront. The Hyperplane is 100% upfront because you're purchasing the hardware.
| AWS (0%) | AWS (Partial) | AWS (100%) | Hyperplane | |
|---|---|---|---|---|
| Upfront | $0 | $126,729 | $238,250 | $109,008 |
| Annual rental | $91,244 | $42,241 | $0 | $0 |
| Annual Co-Location Cost | $0 | $0 | $0 | $15,000 |
| Annual Admin Cost | $0 | $0 | $0 | $10,000 |
| Total Cost Over 3-years | $273,732 | $253,444 | $238,250 | $184,008 |
In all cases, including co-lo and admin costs, the Hyperplane on-prem server beats AWS. Our co-location cost was based on quotation averages from Equinix and Hurricane Electric. Our annual administration cost was based on quotes for data center co-location administration from IT service providers. We encourage you to calculate your own co-location and administration costs and input your own numbers into this model.
But isn't cloud easier?
For real-time applications, Cloud has substantial benefits over on-prem. For example, an Ad server should be low latency, highly redundant, fault tolerance, geographically proximate to clients, etc. Cloud providers offer the lego blocks that facilitate building such a system. However, these benefits are mostly lost on Deep Learning workloads. You're subsidizing all the bells and whistles of a spacecraft, but all you need is a wooden raft.
But what about managing software?
If you purchase your own hardware, you can use the Lambda Stack Deep Learning environment to manage your system's drivers, libraries, and frameworks.
- Pre-installed GPU-enabled TensorFlow, Keras, PyTorch, Caffe, Caffe 2, Theano, CUDA, cuDNN, and NVIDIA GPU drivers.
- If a new version of any framework is released, Lambda Stack manages the upgrade. Using Lambda Stack greatly reduces package management & Linux system administration overhead.
- Dockerfiles available for creating a Lambda Stack container.
The equivalent software is the AWS Deep Learning AMI with Ubuntu. For the DGX-1 you'll need to purchase a license to the NVIDIA GPU Cloud container registry.
Benchmark I: Synthetic Data
To confirm that you're getting your money's worth in terms of compute, let's do some benchmarks. We first use the official Tensorflow benchmark suite to compare the raw training throughput of these two servers. Synthetic data is used to isolate GPU performance from CPU pre-processing performance and reduce spurious I/O bottlenecks. We use replicated training with NCCL to maximize the benefit of NVlink in both machines. Similarly, batch sizes are set to maximize the utilization of V100's 32GB memory.
Our benchmark results showed that Lambda Hyperplane (red) outperformed p3dn.24xlarge (blue) in ALL tasks:
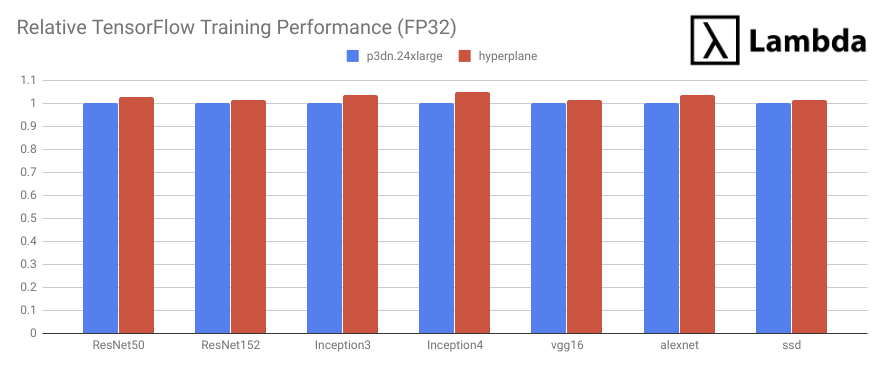
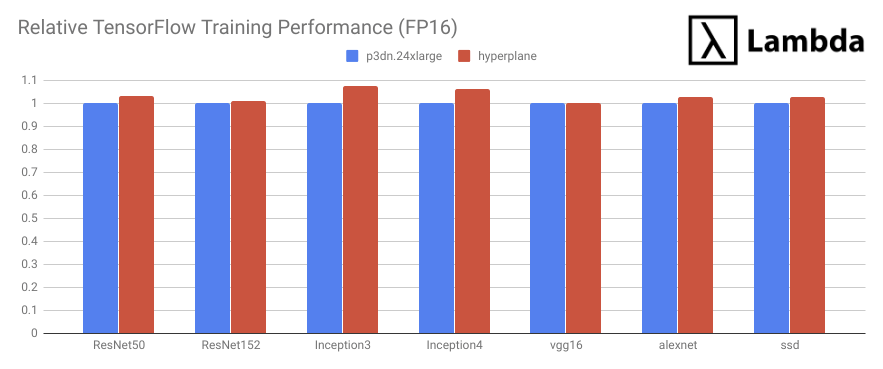
Training with synthetic data reveals GPU horsepower in terms of throughput and device-to-device bandwidth. However, real-world performance can be impacted by other factors such as I/O bottleneck, CPU speed, etc. At the end of the day, what matters is how the entire system, including hardware and software, works together. Next, we will compare these two servers using a real-world training task.
Benchmark II: Real Data Convergence Speed (ResNet50 on ImageNet)
For our real data benchmark, we use Stanford DAWNBench -- the de-facto benchmark suite for end-to-end deep learning training and inference. The task is to finish the 26 training epochs as described here: Now anyone can train Imagenet in 18 minutes. At the time of writing, this represents the fastest way to train a state of the art image classification network on ImageNet. The original blog post reported 18 minutes for a cluster of 16 AWS p3.16xlarge instances to finish the task ($117.5 on demand cost, or $76.37 with a one-year subscription plan). We are interested to know how costly it is to finish the same task with a single beefy server. This training task completes when it reaches 93% in Top-5 classification accuracy.
We first reproduced the training procedure on an AWS p3dn.24xlarge instance. It took 1.63 hours to finish. This translates to $50.98 with on-demand instance pricing or $15.75 with a 3-year partially reserved instance contract.
We then reproduced the same training procedure on a Lambda Hyperplane, it took 1.45 hours. That time cost translates to just $10.15 based on our 3-year TCO.
| AWS p3dn.24xlarge | Lambda Hyperplane | |
|---|---|---|
| Epochs | 26 | 26 |
| Training Duration | 1 hour, 38 minutes | 1 hour, 27 minutes |
| Training Cost | $15.75 | $10.15 |
Conclusion
In this blog, we benchmarked the Lambda Hyperplane and compared it with the performance of the AWS p3dn.24xlarge – the fastest AWS instance for training deep neural networks. We observed that Lambda Hyperplane is not only faster but also significantly more cost-effective. With larger on-prem or co-located cluster deployments, there are even further costs savings and performance benefits. System administration costs don't rise as quickly as the number of machines in the cluster and the machines can benefit from 100Gbps InfiniBand connections under the same rack. However, actual multi-node performance is outside of the scope of this TCO analysis.
Reproducing these results
You can use our Github repos to reproduce these benchmarks.
Benchmark I: Synthetic Data
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
Benchmark II: Real Data (ResNet50 on ImageNet)
git clone https://github.com/lambdal/imagenet18.git
If you have any questions, please comment below and we'll happily answer them for you. If you have any direct questions you can always email enterprise@lambdalabs.com.


