
NVIDIA® A40 GPUs are now available on Lambda Scalar servers. In this post, we benchmark the A40 with 48 GB of GDDR6 VRAM to assess its training performance using PyTorch and TensorFlow. We then compare it against the NVIDIA V100, RTX 8000, RTX 6000, and RTX 5000.
For more GPU performance analyses, including multi-GPU deep learning training benchmarks, please visit our Lambda Deep Learning GPU Benchmark Center.
NVIDIA A40* Highlights
- 48 GB GDDR6 memory
- ConvNet performance (averaged across ResNet50, SSD, Mask R-CNN) matches NVIDIA's previous generation flagship V100 GPU.
- Language model performance (averaged across BERT and TransformerXL) is ~1.5x faster than the previous generation flagship V100.
- Multi-GPU training scales near perfectly from 1x to 8x GPUs.
PyTorch ConvNet training speed
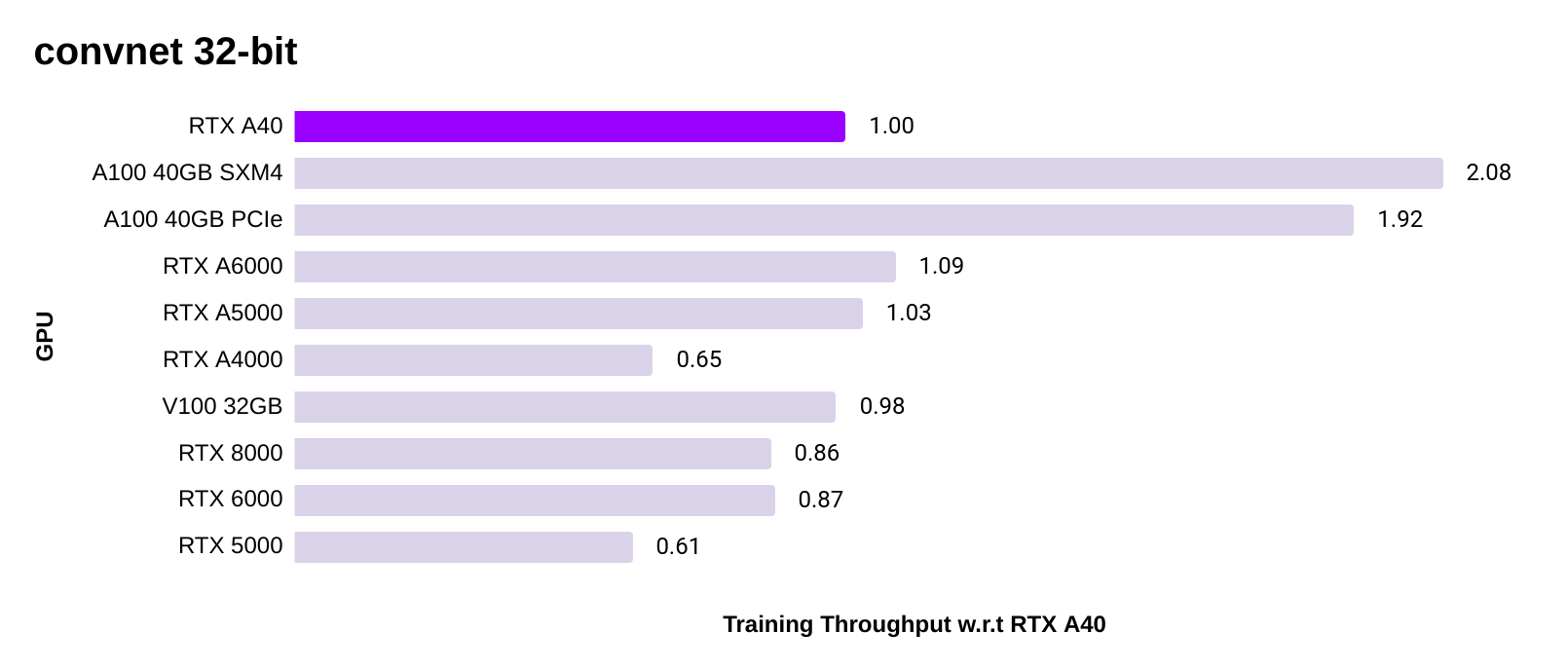
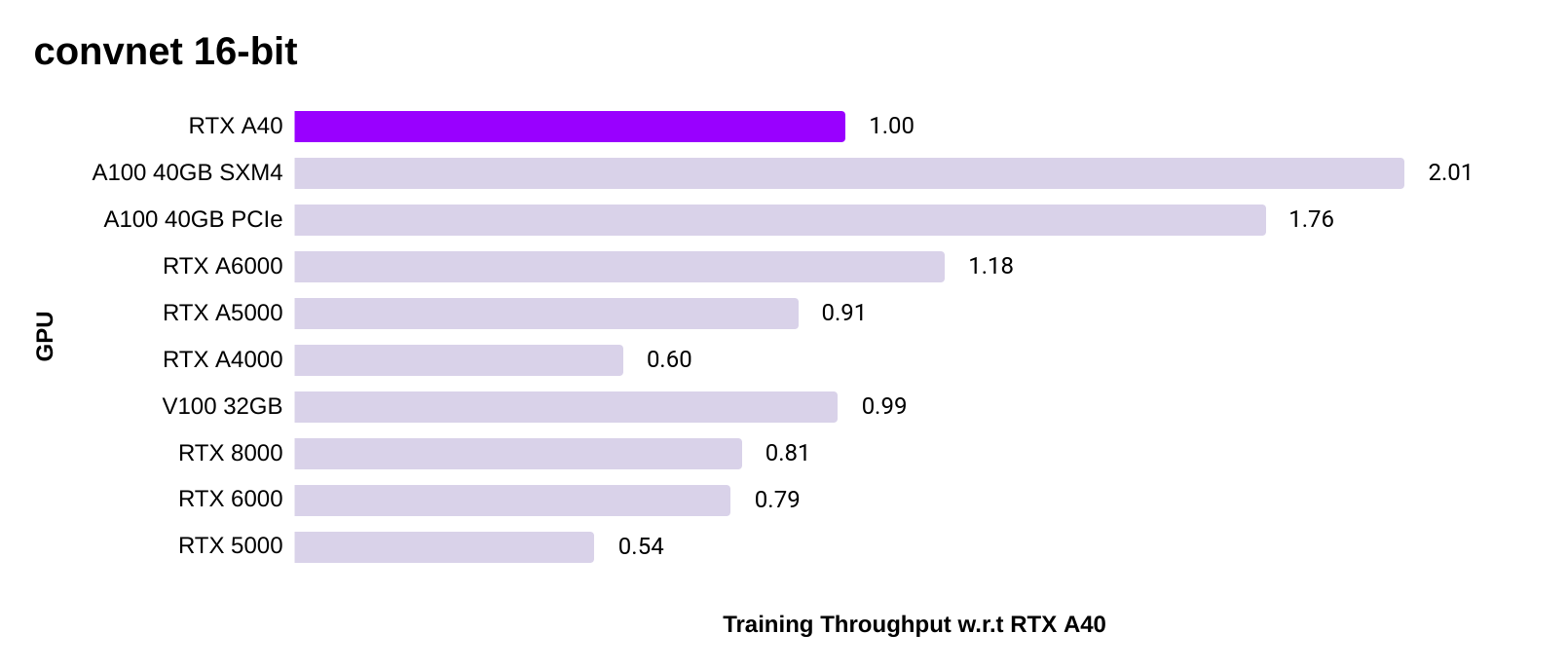
- In terms of training image models (ConvNet), these two charts show consistent performance improvement of the A40 GPU over last generation GPUs such as the V100, RTX 8000, RTX 6000, and RTX 5000.
- The A40 GPU's performance is close to its workstation peer, the A6000 which is about 10% faster due to a slightly higher clock speed and memory bandwidth. However, the A40 is better suited for use in servers since it is passively cooled.
- Performance is averaged across ResNet50, SSD and Mask R-CNN using implementations provided in NVIDIA's PyTorch container.
- 32-bit: All Ampere GPUs (A100, A40, RTX 6000, RTX 5000, RTX 4000) use TF32. Turing GPUs (RTX 8000, RTX 6000, RTX 5000) use FP32.
PyTorch language model training speed
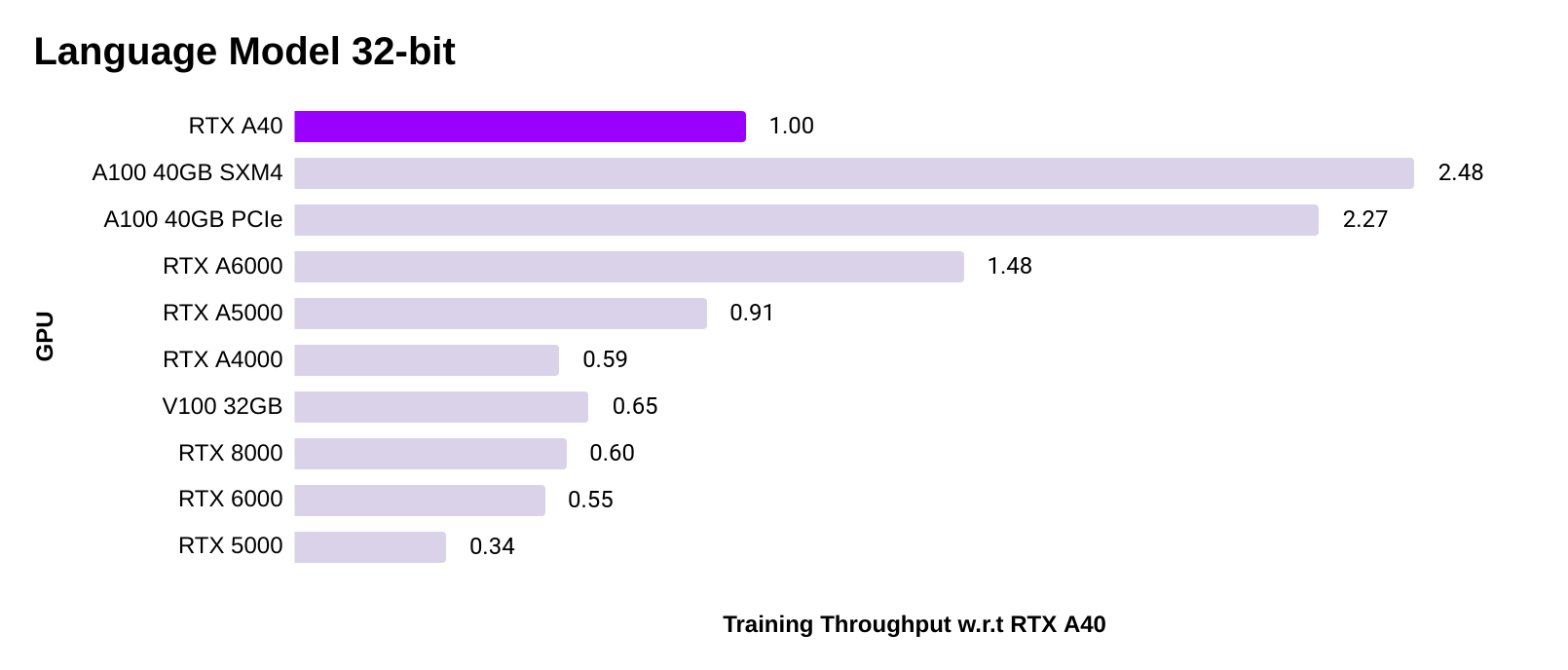
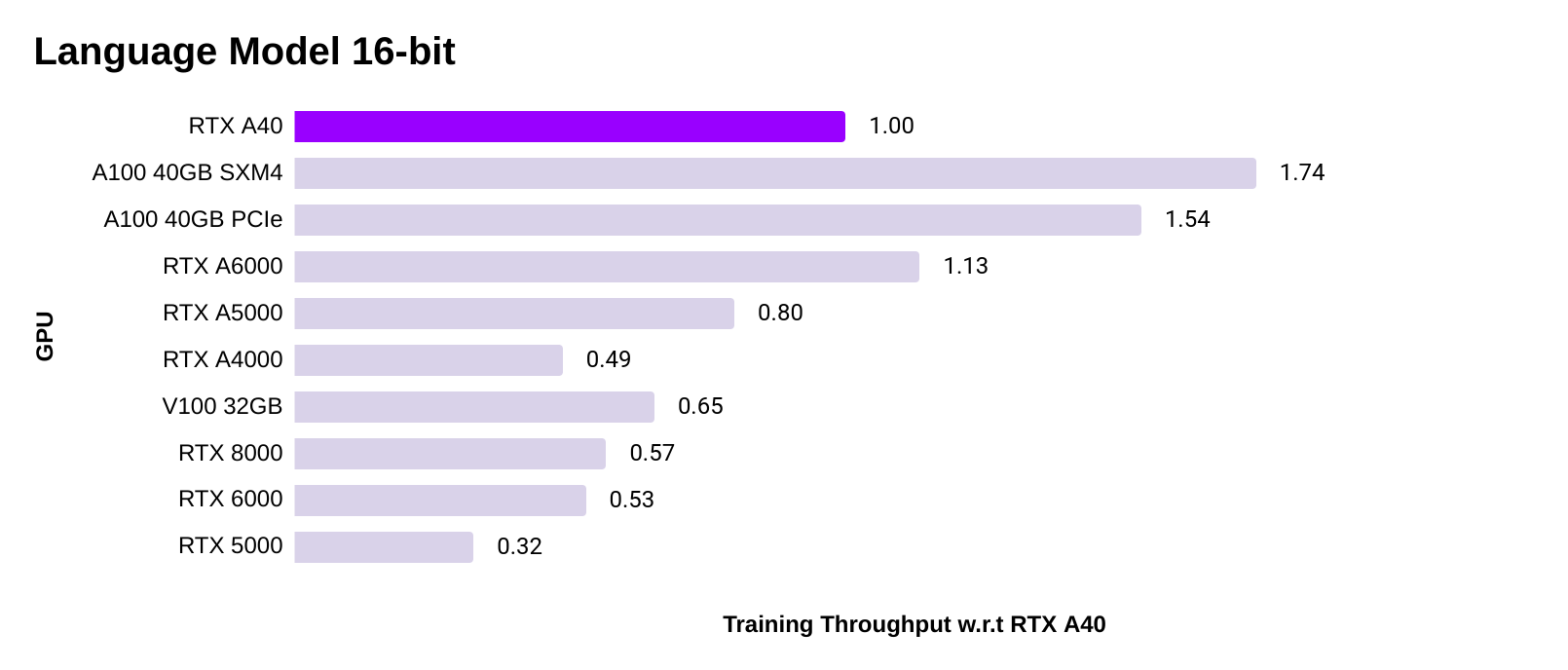
- The improvement of the A40 over previous generation GPUs is even bigger for language models. For example, the A40 is 1.5x faster than the V100.
- Performance is averaged across the task of training transformerXL (base and large), and fine-tuning BERT (base and large).
- 32-bit: All Ampere GPUs (A100, A40, RTX 6000, RTX 5000, RTX 4000) use TF32. Turing GPUs (RTX 8000, RTX 6000, RTX 5000) use FP32.
PyTorch "32-bit" multi-GPU training scalability
We also tested the scalability of the A40 for multi-GPU training. To minimize system bottlenecks, our test server was equipped with two AMD EPYC 7763 64-Core Processors, 512 GB of system memory, and an NVME SSD.
The charts below show that the A40 achieved near perfect scaling from one to eight GPUs.
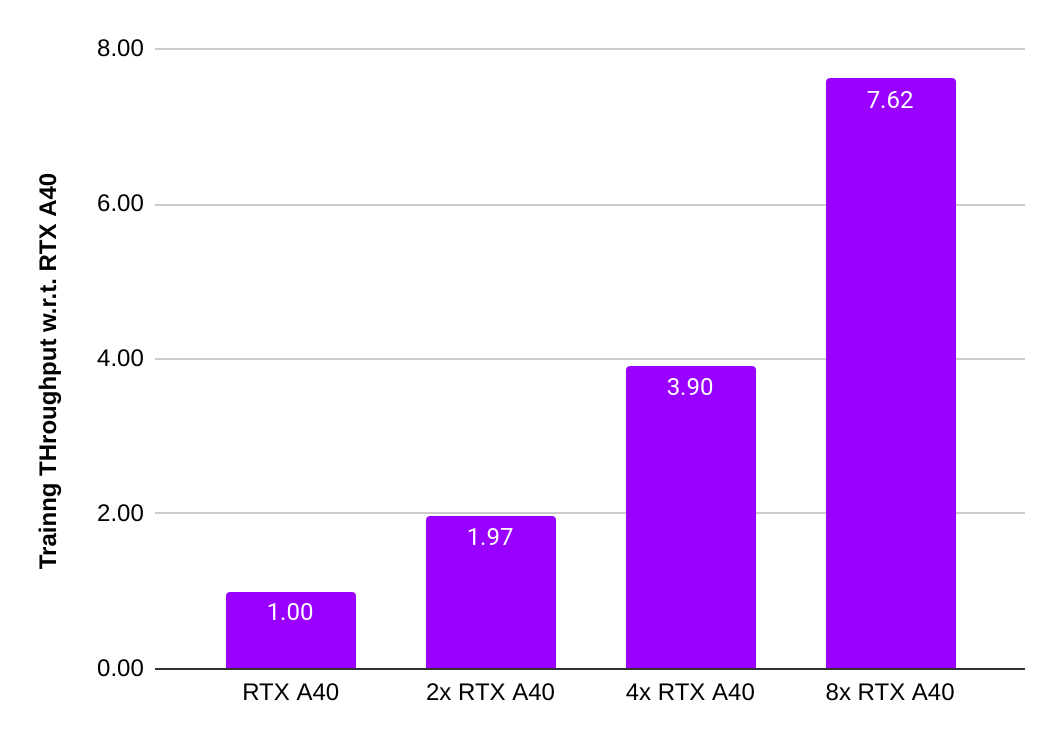
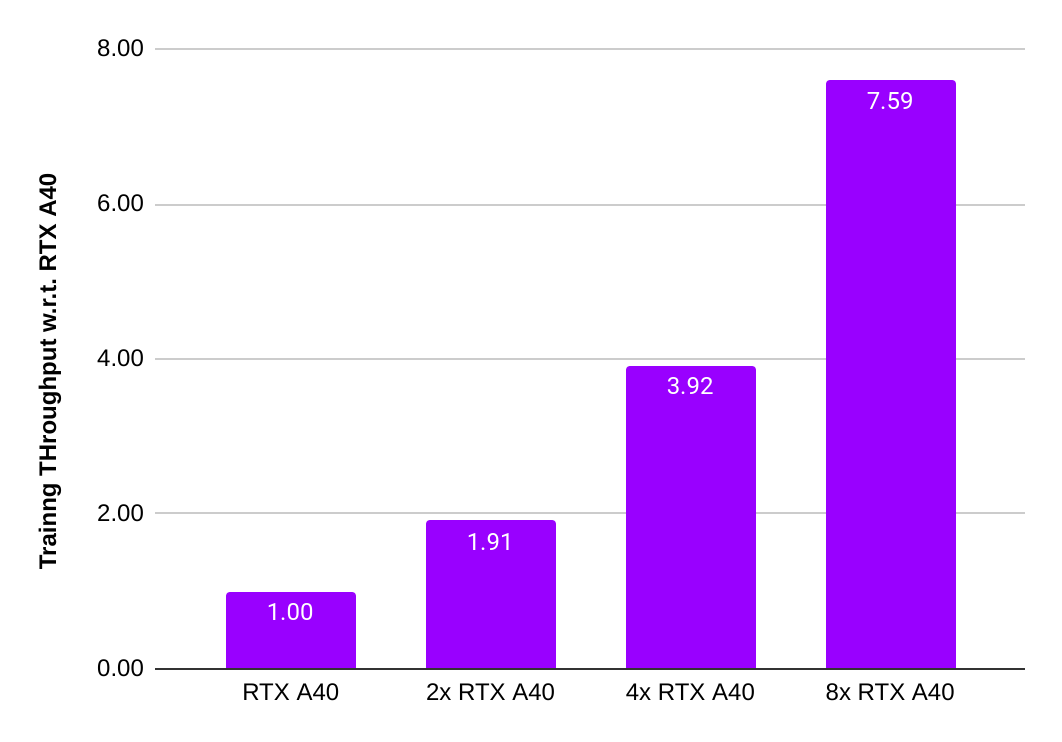
PyTorch "16-bit" multi-GPU training scalability
PyTorch benchmark software stack
Note: The GPUs were tested using NVIDIA PyTorch containers. The NVIDIA V100, RTX 8000, RTX 6000, RTX 5000, and RTX 4000 were tested with pytorch:20.01-py3. All other GPUs were benchmarked using pytorch:20.10-py3. While the performance impact of testing with different container versions is likely minimal, for completeness we are working on re-testing a wider range of GPUs using the latest containers and software. Stay tuned for an update.
Lambda's PyTorch benchmark code is available at the GitHub repo here.