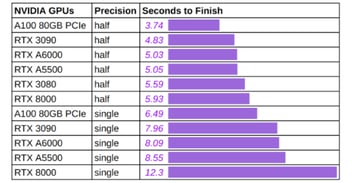
UPDATE 2022-Oct-13 (Turning off autocast for FP16 speeding inference up by 25%)
What do I need...

Lambda is now shipping RTX A6000 workstations & servers. In this post, we benchmark the RTX A6000's PyTorch and TensorFlow training performance. We compare it with the Tesla A100, V100, RTX 2080 Ti, RTX 3090, RTX 3080, RTX 2080 Ti, Titan RTX, RTX 6000, RTX 8000, RTX 6000, etc. For more GPU performance tests, including multi-GPU deep learning training benchmarks, see Lambda Deep Learning GPU Benchmark Center.
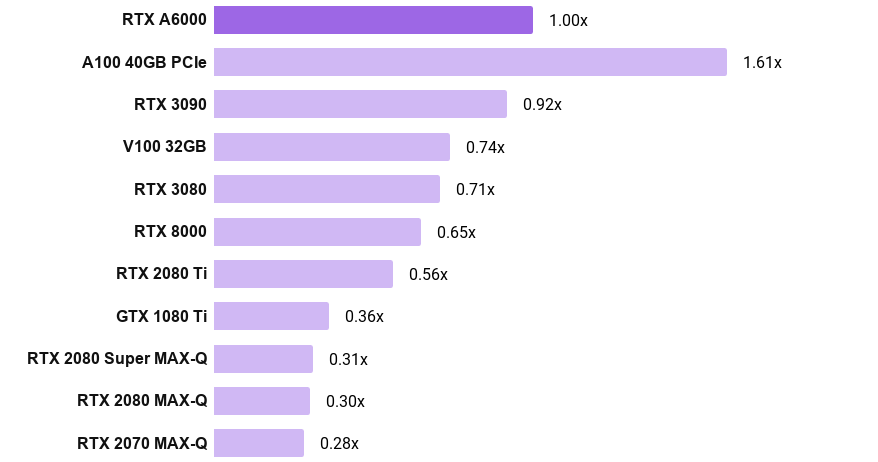
Note: We are working on new benchmarks using the same software version across all GPUs.
Lambda's PyTorch benchmark code is available in the GitHub repo here.
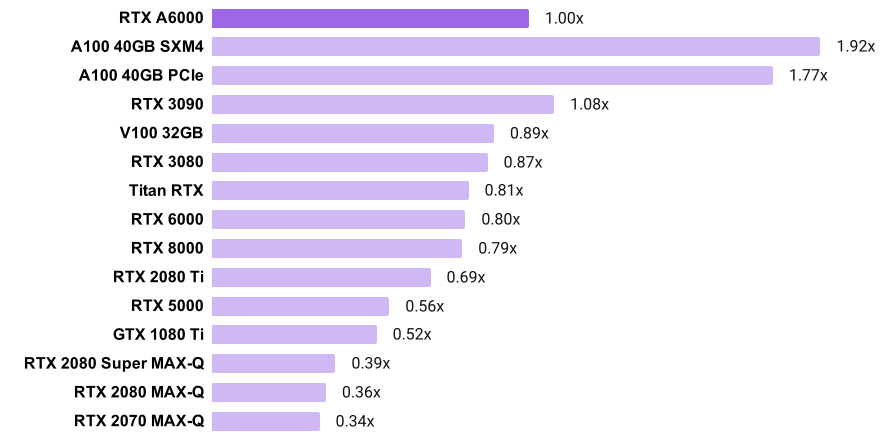
The RTX A6000, Tesla A100s, RTX 3090, and RTX 3080 were benchmarked using
NGC's PyTorch 20.10 docker image with Ubuntu 18.04, PyTorch 1.7.0a0+7036e91, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 460.27.04, and NVIDIA's optimized model implementations.
Pre-ampere GPUs were benchmarked using NGC's PyTorch 20.01 docker image with Ubuntu 18.04, PyTorch 1.4.0a0+a5b4d78, CUDA 10.2.89, cuDNN 7.6.5, NVIDIA driver 440.33, and NVIDIA's optimized model implementations.
Note: We are working on new benchmarks using the same software version across all GPUs.
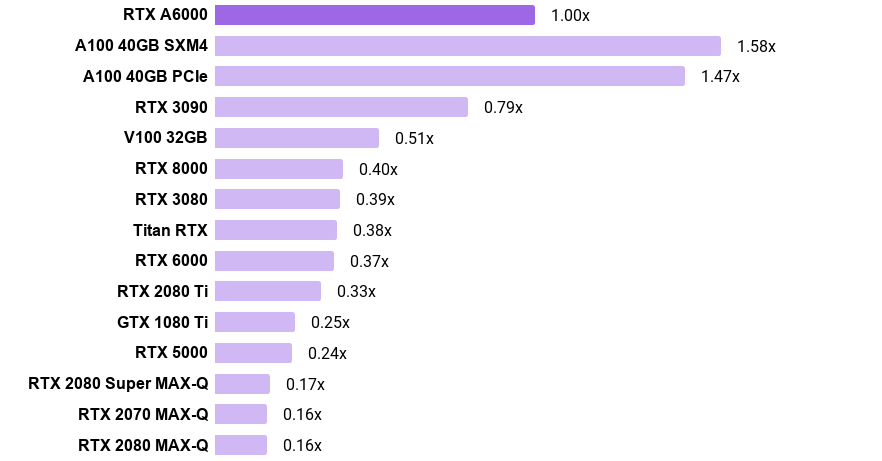
Lambda's TensorFlow benchmark code is available in the GitHub repo here.
The RTX A6000 was benchmarked using NGC's TensorFlow 20.10 docker image using Ubuntu 18.04, TensorFlow 1.15.4, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 455.32, and Google's official model implementations.
The Tesla A100s, RTX 3090, and RTX 3080 were benchmarked using Ubuntu 18.04, TensorFlow 1.15.4, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 455.45.01, and Google's official model implementations.
Pre-ampere GPUs were benchmarked using TensorFlow 1.15.3, CUDA 10.0, cuDNN 7.6.5, NVIDIA driver 440.33, and Google's official model implementations.