Check out the discussion on Reddit
160 upvotes, 41 comments
Lambda is currently shipping servers and workstations with RTX 3090 and RTX A6000 GPUs. In this post, we benchmark the PyTorch training speed of these top-of-the-line GPUs. For more info, including multi-GPU training performance, see our GPU benchmarks for PyTorch & TensorFlow.
View our RTX A6000 GPU workstation
For training image models (convnets) with PyTorch, a single RTX A6000 is...- 0.92x as fast as an RTX 3090 using 32-bit precision.*
- 1.01x faster than an RTX 3090 using mixed precision.
For training language models (transformers) with PyTorch, a single RTX A6000 is...
- 1.34x faster than an RTX 3090 using 32-bit precision.
- 1.34x faster than an RTX 3090 using mixed precision.
For training image models (convnets) with PyTorch, 8x RTX A6000 are...
- 1.13x faster than 8x RTX 3090 using 32-bit precision.**
- 1.14x faster than 8x RTX 3090 using mixed precision.
For training language models (transformers) with PyTorch, 8x RTX A6000 are...
- 1.36x faster than 8x RTX 3090 using 32-bit precision.
- 1.33x faster than 8x RTX 3090 using mixed precision.
* In this post, 32-bit refers to TF32; Mixed precision refers to Automatic Mixed Precision (AMP).
** GPUDirect peer-to-peer (via PCIe) is enabled for RTX A6000s, but does not work for RTX 3090s.
3090 vs A6000 convnet training speed with PyTorch
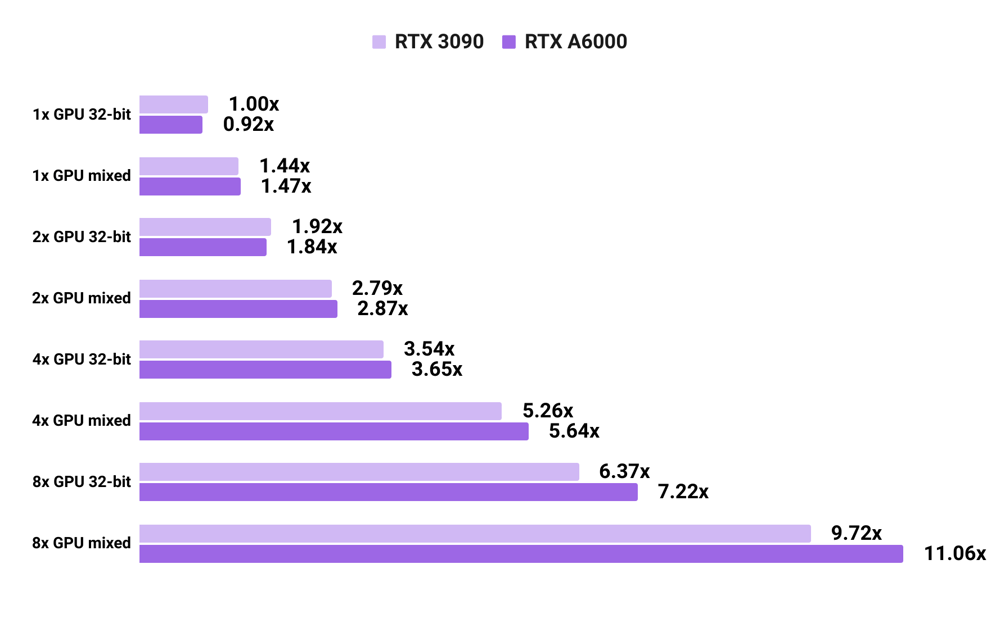
- All numbers are normalized by the 32-bit training speed of 1x RTX 3090.
- 32-bit training of image models with a single RTX A6000 is slightly slower (
0.92x) than with a single RTX 3090. However, due to faster GPU-to-GPU communication, 32-bit training with 4x/8x RTX A6000s is faster than 32-bit training is 4x/8x RTX 3090. Similar patterns apply to training image models with mixed-precision. - Results are averaged across SSD, ResNet-50, and Mask RCNN.
- We use the maximum batch sizes that fit in these GPUs' memories. For detailed info about batch sizes, see the raw data at our TensorFlow & PyTorch GPU benchmarking page.
3090 vs A6000 language model training speed with PyTorch
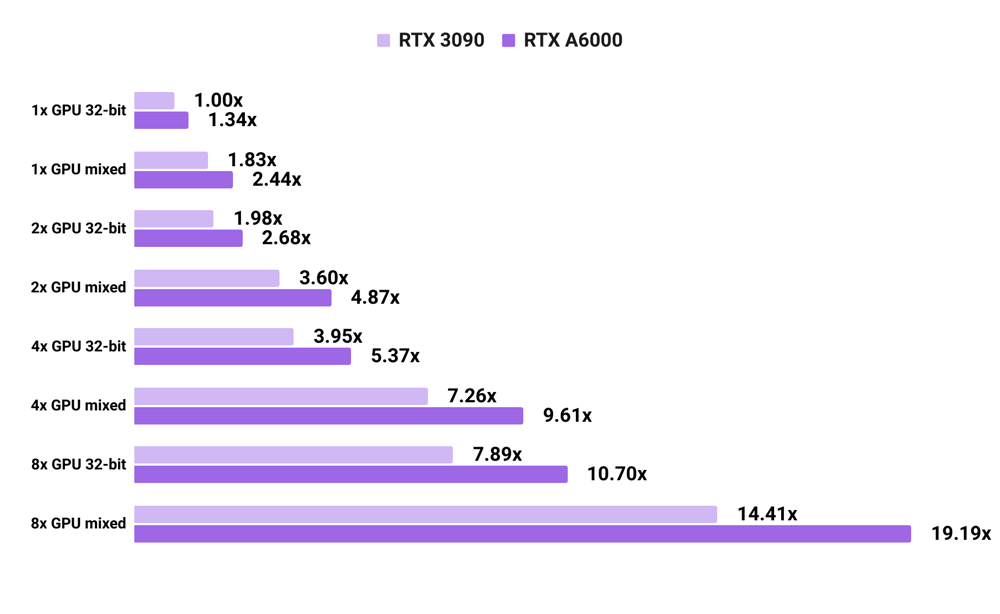
- All numbers are normalized by the 32-bit training speed of 1x RTX 3090.
- Unlike with image models, for the tested language models, the RTX A6000 is always at least
1.3xfaster than the RTX 3090. This is likely due to language models being bottlenecked on memory; the RTX A6000 benefits from the extra 24 GB of GPU memory compared to RTX 3090. - Results are averaged across Transformer-XL base and Transformer-XL large.
- We use the maximum batch sizes that fit in these GPUs' memories. For detailed info about batch sizes, see the raw data at our TensorFlow & PyTorch GPU benchmarking page.
View our RTX A6000 GPU workstation
Benchmark software stack
Lambda's benchmark code is available at the GitHub repo here.
- The benchmarks use NGC's PyTorch 20.10 docker image with Ubuntu 18.04, PyTorch 1.7.0a0+7036e91, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 460.27.04, and NVIDIA's optimized model implementations.