
Check out the discussion on Reddit
195 upvotes, 23 comments
Lambda is now shipping Tesla A100 servers. In this post, we benchmark the PyTorch training speed of the Tesla A100 and V100, both with NVLink. For more info, including multi-GPU training performance, see our GPU benchmark center.
For training convnets with PyTorch, the Tesla A100 is...- 2.2x faster than the V100 using 32-bit precision.*
- 1.6x faster than the V100 using mixed precision.
- 3.4x faster than the V100 using 32-bit precision.
- 2.6x faster than the V100 using mixed precision.
* In this post, for A100s, 32-bit refers to FP32 + TF32; for V100s, it refers to FP32.
View Lambda's Tesla A100 server
A100 vs V100 convnet training speed, PyTorch
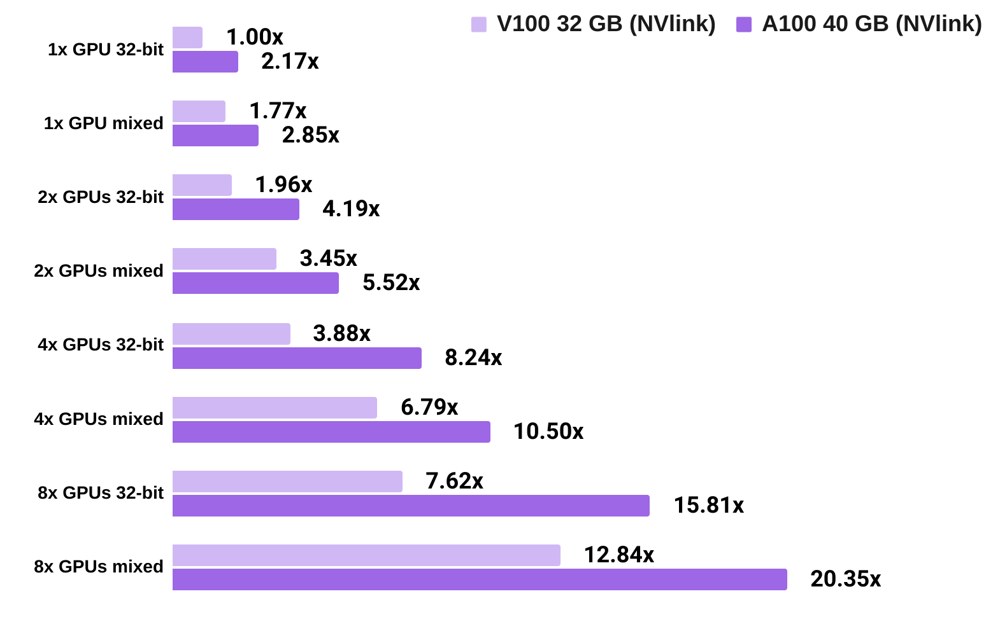
- All numbers are normalized by the 32-bit training speed of 1x Tesla V100.
- The chart shows, for example: 32-bit training with 1x A100 is 2.17x faster than 32-bit training 1x V100; 32-bit training with 4x V100s is 3.88x faster than 32-bit training with 1x V100; and mixed precision training with 8x A100 is 20.35x faster than 32-bit training with 1x V100.
- Results averaged across SSD, ResNet-50, and Mask RCNN.
- For batch size info, see the raw data at our GPU benchmarking center.
View Lambda's Tesla A100 server
A100 vs V100 language model training speed, PyTorch
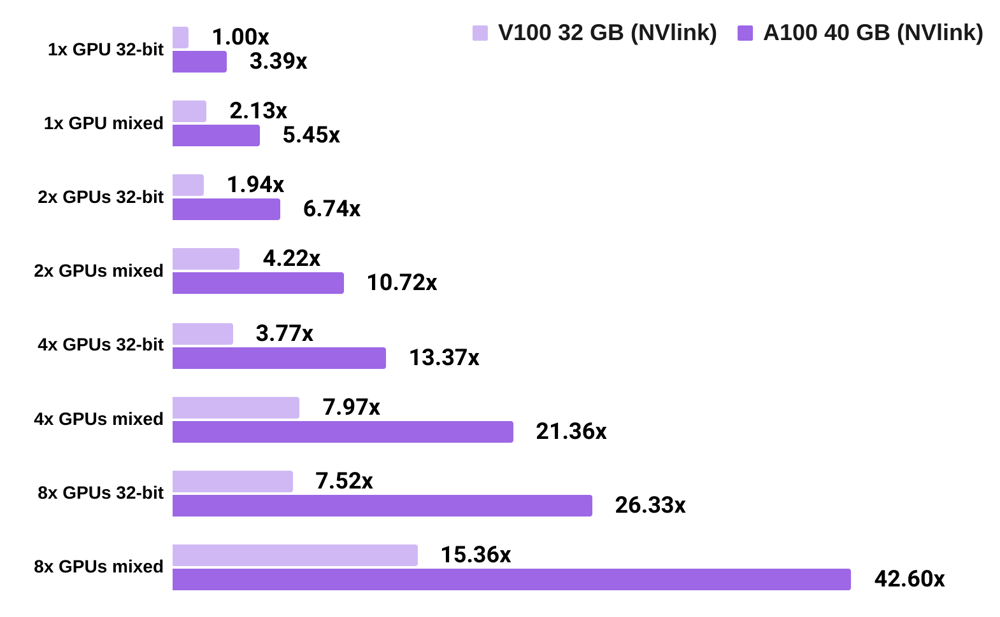
- All numbers are normalized by the 32-bit training speed of 1x Tesla V100.
- The chart shows, for example, that 32-bit training with 1x A100 is 3.39x faster than 32-bit training with a 1x V100; mixed precision training with 4x V100 is 7.97x faster than 32-bit training with 1x V100; and mixed precision training with 8x A100 is 42.60x faster than 32-bit training with 1x V100.
- Results averaged across Transformer-XL base, Transformer-XL large, Tacotron 2, and BERT-base SQuAD.
- For batch size info, see the raw data at our GPU benchmarking center.
View Lambda's Tesla A100 server
Benchmark software stack
- Lambda's benchmark code is available at the GitHub repo here.
- The Tesla A100 was benchmarked using NGC's PyTorch 20.10 docker image with Ubuntu 18.04, PyTorch 1.7.0a0+7036e91, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 460.27.04, and NVIDIA's optimized model implementations.
- The Tesla V100 was benchmarked using NGC's PyTorch 20.01 docker image with Ubuntu 18.04, PyTorch 1.4.0a0+a5b4d78, CUDA 10.2.89, cuDNN 7.6.5, NVIDIA driver 440.33, and NVIDIA's optimized model implementations.
- Benchmarks using the same software versions for the A100 and V100 coming soon!


