
Lambda is now shipping RTX A6000 workstations & servers. In this post, we benchmark the RTX A6000's PyTorch and TensorFlow training performance. We compare it with the Tesla A100, V100, RTX 2080 Ti, RTX 3090, RTX 3080, RTX 2080 Ti, Titan RTX, RTX 6000, RTX 8000, RTX 6000, etc. For more GPU performance tests, including multi-GPU deep learning training benchmarks, see Lambda Deep Learning GPU Benchmark Center.
RTX A6000 highlights
- Memory: 48 GB GDDR6
- PyTorch convnet "FP32" performance: ~1.5x faster than the RTX 2080 Ti
- PyTorch NLP "FP32" performance: ~3.0x faster than the RTX 2080 Ti
- TensorFlow convnet "FP32" performance: ~1.8x faster than the RTX 2080 Ti
- Availability: Shipping now in Lambda's deep learning workstations and servers
- Retail price: $4,650
PyTorch "32-bit" convnet training speed
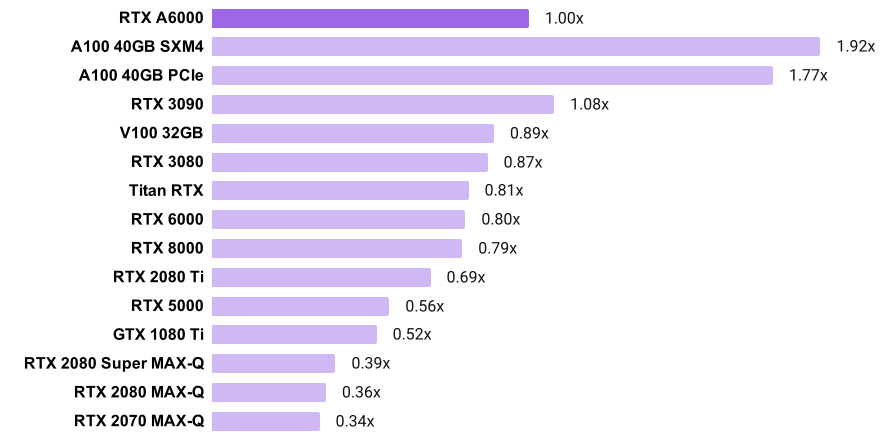
- The chart shows, for example, that the A100 SXM4 is 92% faster than the RTX A6000
- Note that the A100 and A6000 use TensorFloat-32 while the other GPUs use FP32
- Training speed for each GPU was calculated by averaging its normalized training throughput (images/second) across SSD, ResNet-50, and Mask RCNN.
PyTorch "32-bit" language model training speed
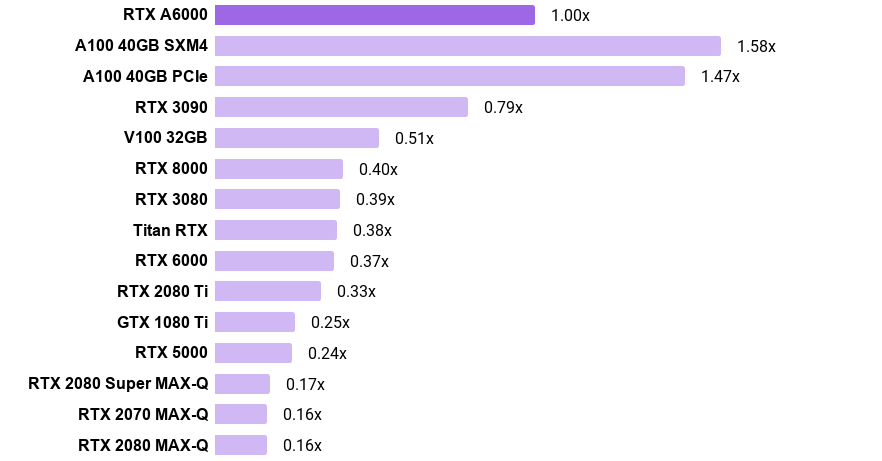
- The chart shows, for example, that the A100 SXM4 is 58% faster than the RTX A6000
- Note that the A100 and A6000 use TensorFloat-32 while the other GPUs use FP32
- Training speed for each GPU was calculated by averaging its normalized training throughput across Transformer-XL base, Transformer-XL large, Tacotron 2, and BERT-base SQuAD.
TensorFlow "32-bit" convnet training speed
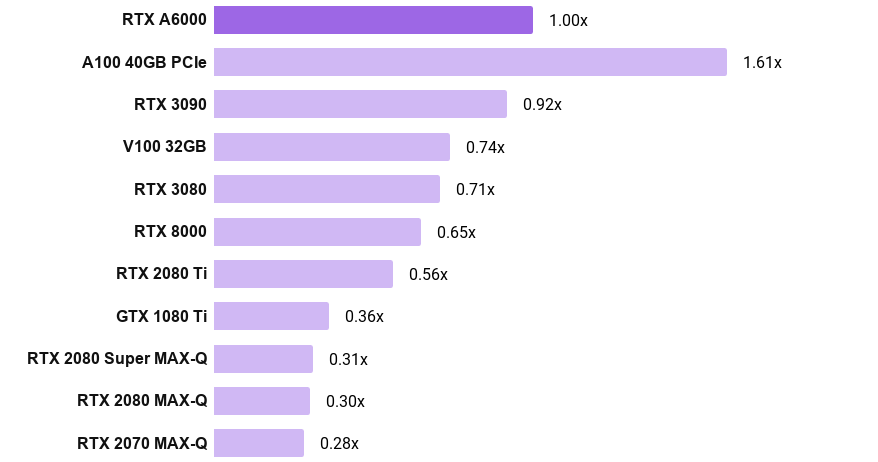
- The chart shows, for example, that the A100 PCIe is 61% faster than the RTX A6000
- Note that the A100 and A6000 use TensorFloat-32 while the other GPUs use FP32
- Training speed for each GPU was calculated by averaging its normalized training throughput (images/second) across ResNet-152, ResNet-50, Inception v3, Inception v4, AlexNet, and VGG-16.
PyTorch benchmark software stack
Note: We are working on new benchmarks using the same software version across all GPUs.
Lambda's PyTorch benchmark code is available in the GitHub repo here.
The RTX A6000, Tesla A100s, RTX 3090, and RTX 3080 were benchmarked using
NGC's PyTorch 20.10 docker image with Ubuntu 18.04, PyTorch 1.7.0a0+7036e91, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 460.27.04, and NVIDIA's optimized model implementations.
Pre-ampere GPUs were benchmarked using NGC's PyTorch 20.01 docker image with Ubuntu 18.04, PyTorch 1.4.0a0+a5b4d78, CUDA 10.2.89, cuDNN 7.6.5, NVIDIA driver 440.33, and NVIDIA's optimized model implementations.
TensorFlow benchmark software stack
Note: We are working on new benchmarks using the same software version across all GPUs.
Lambda's TensorFlow benchmark code is available in the GitHub repo here.
The RTX A6000 was benchmarked using NGC's TensorFlow 20.10 docker image using Ubuntu 18.04, TensorFlow 1.15.4, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 455.32, and Google's official model implementations.
The Tesla A100s, RTX 3090, and RTX 3080 were benchmarked using Ubuntu 18.04, TensorFlow 1.15.4, CUDA 11.1.0, cuDNN 8.0.4, NVIDIA driver 455.45.01, and Google's official model implementations.
Pre-ampere GPUs were benchmarked using TensorFlow 1.15.3, CUDA 10.0, cuDNN 7.6.5, NVIDIA driver 440.33, and Google's official model implementations.