One of the biggest trends in machine learning is the development of large transformer models like BERT and diffusion models like stable diffusion. These large models can have billions of parameters and require significant compute power. Training large models like this is not possible with a single node and requires multi-node distributed training.
To meet the growing needs of machine learning teams that are training large models or datasets, we are launching Lambda Reserved Cloud Clusters.
What are Lambda Reserved Cloud Clusters?
Lambda Reserved Cloud Clusters are made with 8x NVIDIA A100 (40GB) bare metal GPUs that are connected with 1600 Gbps of RDMA networking. This is the fastest node-to-node bandwidth possible and is 4x faster than AWS’s equivalent EC2 offering. Reserved Cloud Clusters start at 32 GPUs with an option to add CPU VM instances with 64 vCPUs and block storage.
Our Reserved Cloud Cluster allows machine learning teams to take large models or datasets and distribute them among multiple nodes so they can train faster.
One of our core partners in developing our cloud cluster solution is Voltron Data, a data company that develops standard solutions for the Apache Arrow ecosystem. Nate Rock, a senior member of their DevOps team explains how working with large datasets triggered their need for a cluster solution.
"When one has reached the limitations that even the largest set of hardware can provide, the natural evolution is to distribute the storage and data processing across a collection of resources,” said Nate.
Explore Reserved Cloud Cluster here.
In this blog, we will outline the benefits of our new Reserved Cloud Cluster and an example of how Voltron Data is using it to work with large datasets.
- Save 25-57% on compute costs and 90% on egress
- Dedicated GPUs with contract lengths starting at 6 months
- 1600 Gbps of RDMA networking for distributed training
- Fast to get started and configured for ML
- Deep learning expertise with options for premium support
Save 25-57% on compute costs and 90% on egress
Voltron Data knew they needed a GPU compute cluster, but setting up an on-prem solution would take more time than they wanted to spare. To get around this, they adopted a Lambda Reserved Cloud Cluster while they waited for their Lambda Echelon Cluster to get up and running.
Two of the major factors in their evaluation of a cloud cluster were availability and cost. Bare metal cluster systems from big cloud providers can often run into the millions of dollars or have limited availability.
Nate from Voltron Data told us these were the key reasons they chose to go with Lambda. “Our leadership has intimate knowledge of the industry and after doing an extensive evaluation on the cost-benefit analysis across all major cloud providers and various on-prem solutions, part of the decision to partner with Lambda was due to the ability to deliver on availability and pricing.”
To make cloud clusters more accessible to AI Startups and companies working on the cutting edge of technology, we are offering prices up to 57% less than AWS for NVIDIA A100 bare metal hosted servers that have faster networking and more vCPUs. Our egress fee is $0.009/GB which is 90% less than AWS.
Cost comparison of AWS vs Lambda per bare metal 8x A100 server
|
GPU memory |
GPU |
Network Bandwidth (Gbps) |
vCPU |
1-Year Price |
Savings on GPU |
|
|
AWS EC2 |
40GB |
NVIDIA 8x A100 |
400 |
96 |
$19.22 |
- |
|
Lambda Reserved Cloud Cluster |
40GB |
NVIDIA 8x A100 |
1600 |
128 |
$8.36 |
57% |
1-Year Cost of a 32 GPU Cluster with Lambda vs AWS
To give you a sense of total cost of a Reserved Cloud Cluster, below is a side-by-side comparison of the cost of a 32 GPU cluster for 1 year with AWS vs Lambda:
|
GPUs |
Lambda |
AWS |
|
8x NVIDIA A100 (40GB) |
$292,934 |
$673,468 |
|
8x NVIDIA A100 (80 GB) - Coming Soon |
$380,482 |
$841,310 |
Note: All prices do not include egress or storage fees. Lambda egress is $0.009/GB and additional block storage is $0.04/GB/month sold in 10TB blocks.
Dedicated GPUs with contract lengths starting at 6 months
While most other cloud companies offer contracts starting at one year, you can reserve a Lambda Reserved Cloud Cluster starting at six months. If you want to lock in the best prices over the long term, you can opt to reserve for one to three years. Our cloud clusters also use dedicated, bare metal GPUs so you get all the performance benefits of bare metal, without having to share it or maintain it.
Voltron took advantage of the flexible contract lengths and opted to start with a six month contract while they waited for their on-prem solution to get up and running.
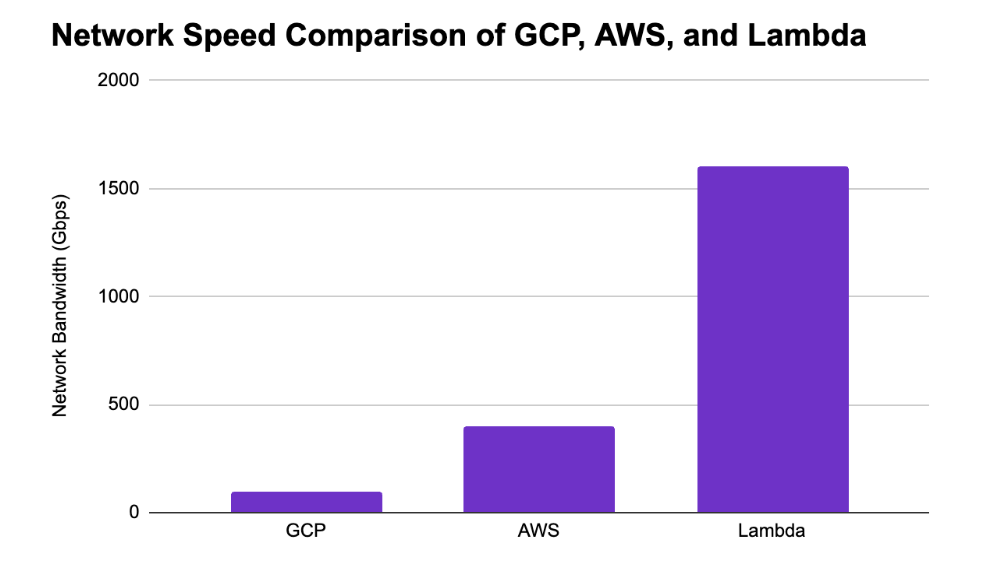
1600 Gbps of RDMA networking for distributed training
High speed networking is what allows ML teams to distribute their large models or datasets among multiple nodes to train faster. This process is called multi-node distributed training.
Multi-node distributed training is most commonly used in creating large transformer or diffusion models that could have billions of parameters. Natural Language Processing models like Google’s BERT or diffusion models like Stable Diffusion are both good examples that required distributed training. When it comes to networking for distributed training, the faster the networking speed, the faster these models will train.
Lambda’s Reserved Cloud Cluster solution has the fastest networking on the market at 1600 Gbps. This is 16x faster than GCP’s networking (100 Gbps) and 4x faster than AWS (400 Gbps). We are working on benchmarking this with a few models to put this into real time savings, so stay tuned for that in another post.
Fast to get started. Configured for ML
One of the huge benefits of working in the cloud is that you can get access to your machines in a fraction of the time it would take to set them up on-premises and they are all managed by Lambda. We can deploy your cluster in 12 days or less from signing a contract so you can start training your models right away.
For Voltron Data, speed was key to their success. Nate told us, “our ability to make use of the Lambda Cloud resources with a relatively short lead-time while the customized configuration running in the Lambda Data Center was being procured and assembled turned out to be instrumental in our ability to charge forward without skipping a beat. Rather than sitting dormant while the longer term solution was being completed, we were able to vet our internal operations and engineering efforts in a clustered environment fairly close to our desired end state.”
All of our cloud products are designed to work out of the box for deep learning, which is why our Reserved Cloud Clusters are pre-configured with Lambda Stack. Lambda Stack includes updated versions of PyTorch, TensorFlow, CUDA, CuDNN, and NVIDIA Drivers so everything is up to date and easily accessible. If you want to install other custom software that’s not included in Lambda Stack, we can do that too.
When you have a Reserved Cloud Cluster, Lambda manages all of the setup, hardware, software, networking, and storage in your cluster. All you have to do is choose the number of GPUs and CPUs to get started.
Deep learning expertise
Setting up a cluster is no easy feat and involves knowledge of hardware, software, networking, and storage for deep learning.
Our support team worked closely with Voltron Data to get their cloud cluster solution up and running as quickly and smoothly as possible.
Nate told us, “Working with Lambda has been extremely smooth. From the initial planning phase through final implementation and delivery the overall experience has been fantastic.”
While our basic support package includes dedicated email support from a linux engineer, our premium support for Reserved Cloud Clusters includes a technical account manager, onboarding, and support for the software included in Lambda Stack.
Interested in seeing if a Reserved Cloud Cluster solution is the right choice for your application? Contact our cloud sales team at cloudsales@lambdal.com to learn more and get a custom quote.