
Lambda Echelon is a GPU cluster designed for AI. It comes with the compute, storage, network, power, and support you need to tackle large scale deep learning tasks. Echelon offers a turn-key solution to faster training, faster hyperparameter search, and faster inference.
A four rack Echelon cluster is able to train BERT on Wikipedia in minutes instead of days.
Echelon is a rack architecture that supports a wide range of scales: from a single rack 40 GPU cluster to a data center scale thousand GPU cluster.
A quick introduction
Compute
If you’re a Lambda customer, you’ll already be familiar with the compute nodes in an Echelon. They’re our Lambda Hyperplane and Lambda Blade GPU servers. Echelon compute nodes have been designed to leverage a high speed communication fabric (InfiniBand HDR 200 Gb/s or 100 Gb/s Ethernet). Nodes are able to communicate at blazing fast speeds to tackle large scale training of language models and convnets.

Network
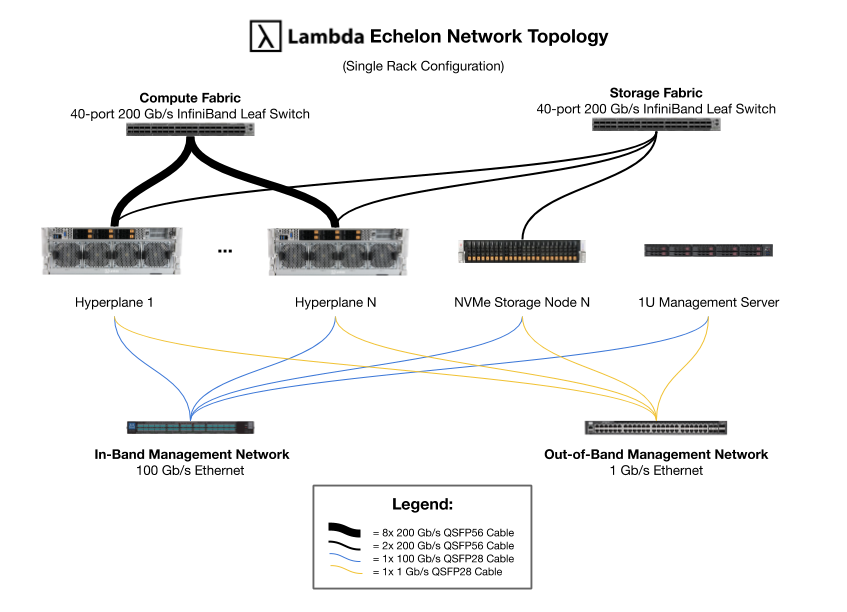
An Echelon cluster designed for large scale distributed training offers four distinct networks. While in the diagram below you’ll see three networks for compute, storage, and in-band management, a simplified architecture includes a single 100 Gb/s ethernet fabric instead. An Echelon cluster can have up to four distinct networks:
- 200 Gb/s HDR InfiniBand Compute Fabric
- 200 Gb/s HDR InfiniBand Storage Fabric
- 100 Gb/s In-Band Management Network
- 1 Gb/s Out-of-Band Management Network
The InfiniBand compute fabric enables rapid node-to-node data transfers via GPU/InfiniBand RDMA while the storage fabric enables rapid access to your data sets. Seen below is a network topology for a single rack cluster with 40 NVIDIA A100 GPUs.
Storage
Lambda has pre-existing OEM relationships with practically every storage appliance provider in the world. Echelon has been designed to support both proprietary and open source storage solutions. Because they can all be purchased through Lambda, your procurement process is greatly simplified.
Proprietary Storage Options

Open Source Storage Options

Support

Having successfully deployed thousands of nodes, Lambda’s team consists of seasoned HPC experts. When you get an Echelon with Premium support, you get phone support directly from an AI infrastructure engineer. Lambda Echelon support doesn’t just stop at the hardware. With Premium or Max support tiers, whether you have a hardware, software, or Linux system administration question, we’ll be there to help.
Learn more by reading our white paper

To learn more about the Echelon and building your own GPU cluster, read our white paper.