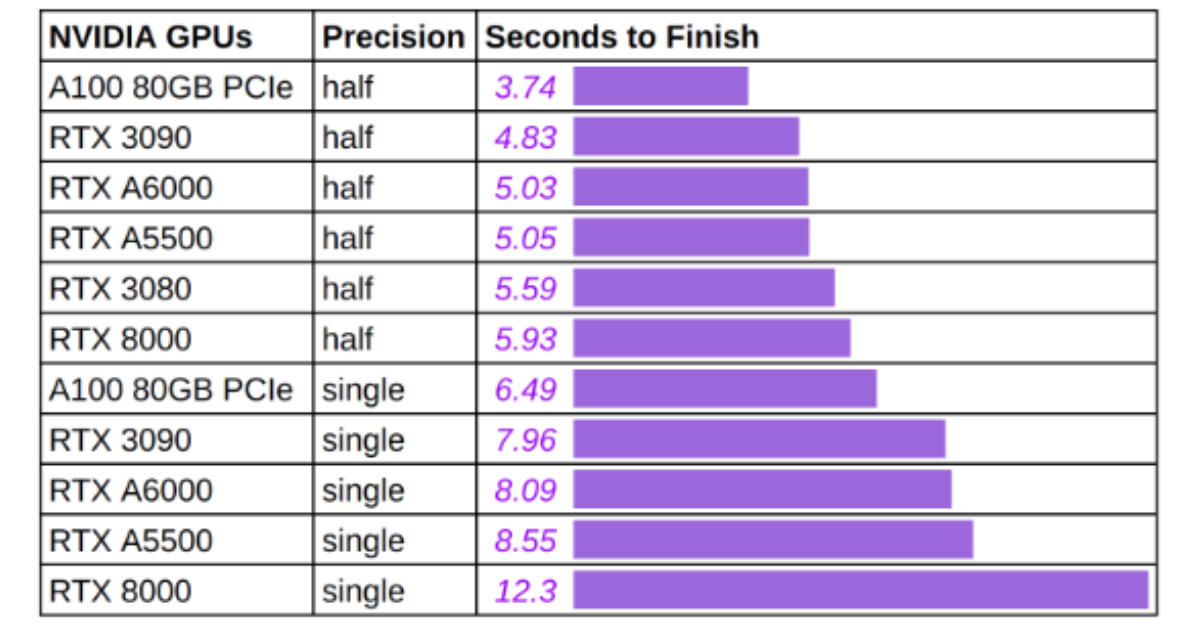
All You Need Is One GPU: Inference Benchmark for Stable Diffusion
UPDATE 2022-Oct-13 (Turning off autocast for FP16 speeding inference up by 25%) What do I need for running the state-of-the-art text to image model? Can a ...
UPDATE 2022-Oct-13 (Turning off autocast for FP16 speeding inference up by 25%) What do I need for running the state-of-the-art text to image model? Can a ...

We have seen groundbreaking progress in machine learning over the last couple of years. At the same time, massive usage of GPU infrastructure has become key to ...

NVIDIA® A40 GPUs are now available on Lambda Scalar servers. In this post, we benchmark the A40 with 48 GB of GDDR6 VRAM to assess its training performance ...