
In this post, Lambda discusses the RTX 2080 Ti's Deep Learning performance compared with other GPUs. We use the RTX 2080 Ti to train ResNet-50, ResNet-152, Inception v3, Inception v4, VGG-16, AlexNet, and SSD300. We measure # of images processed per second while training each network.
A few notes:
- We use TensorFlow 1.12 / CUDA 10.0.130 / cuDNN 7.4.1
- Single-GPU benchmarks were run on the Lambda's deep learning workstation
- Multi-GPU benchmarks were run on the Lambda's PCIe GPU server
- V100 Benchmarks were run on Lambda's SXM3 Tesla V100 server
- Tensor Cores were utilized on all GPUs that have them
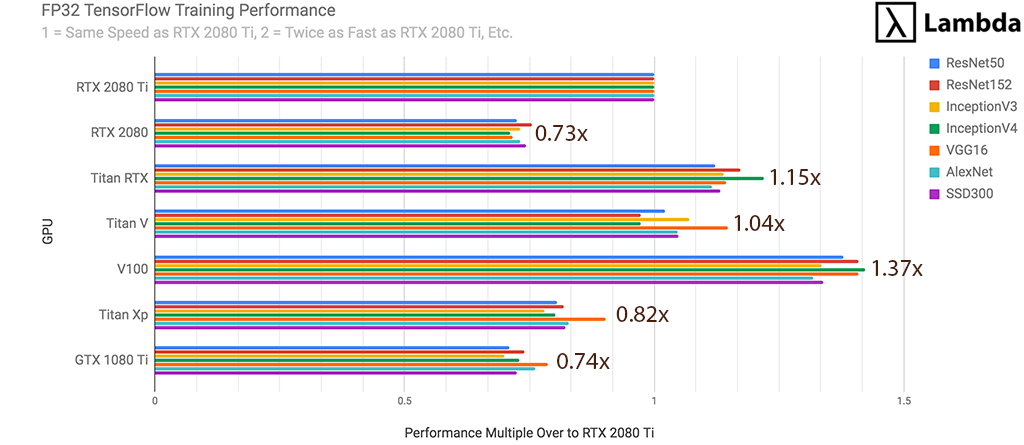
RTX 2080 Ti - FP32 TensorFlow Performance (1 GPU)
For FP32 training of neural networks, the RTX 2080 Ti is...
- 37% faster than RTX 2080
- 35% faster than GTX 1080 Ti
- 22% faster than Titan XP
- 96% as fast as Titan V
- 87% as fast as Titan RTX
- 73% as fast as Tesla V100 (32 GB)
as measured by the # images processed per second during training.
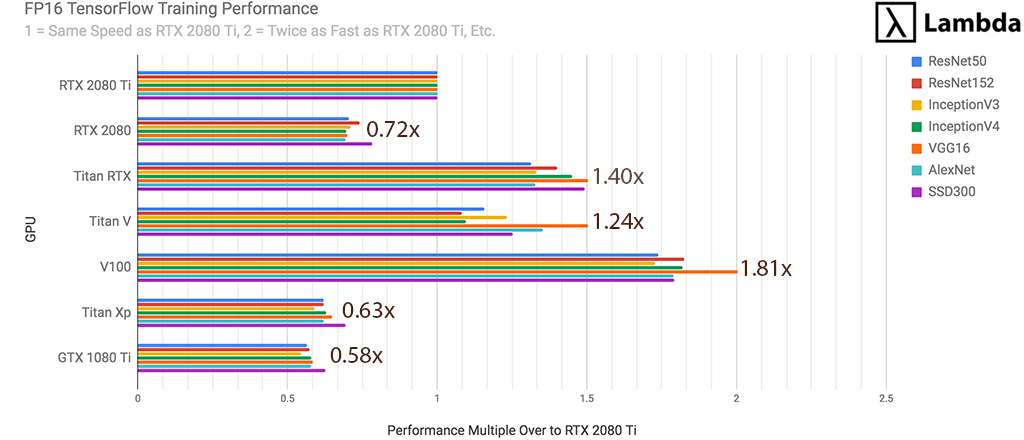
RTX 2080 Ti - FP16 TensorFlow Performance (1 GPU)
For FP16 training of neural networks, the RTX 2080 Ti is..
- 72% faster than GTX 1080 Ti
- 59% faster than Titan XP
- 32% faster than RTX 2080
- 81% as fast as Titan V
- 71% as fast as Titan RTX
- 55% as fast as Tesla V100 (32 GB)
as measured by the # images processed per second during training.
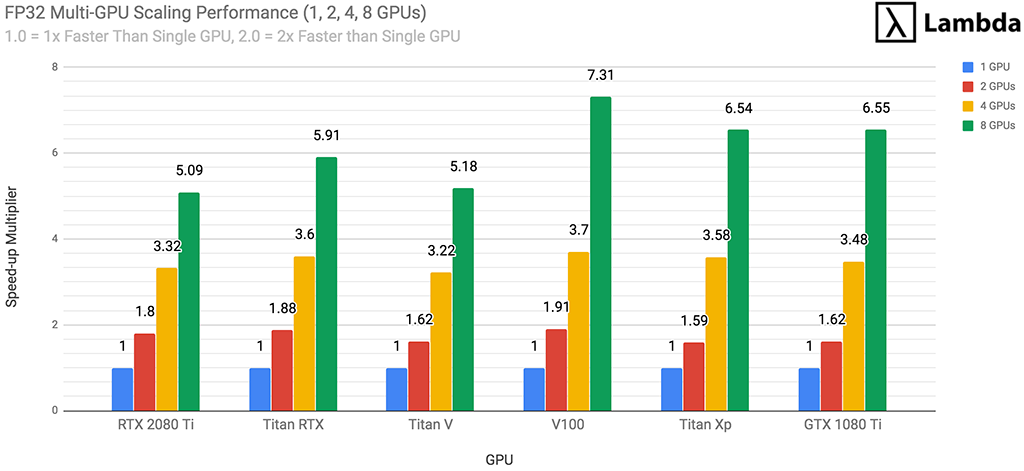
FP32 Multi-GPU Scaling Performance (1, 2, 4, 8 GPUs)
For each GPU type (RTX 2080 Ti, RTX 2080, etc.) we measured performance while training with 1, 2, 4, and 8 GPUs on each neural networks and then averaged the results. The chart below provides guidance as to how each GPU scales during multi-GPU training of neural networks in FP32. The RTX 2080 Ti scales as follows:
- 2x RTX 2080 Ti GPUs will train ~1.8x faster than 1x RTX 2080 Ti
- 4x RTX 2080 Ti GPUs will train ~3.3x faster than 1x RTX 2080 Ti
- 8x RTX 2080 Ti GPUs will train ~5.1x faster than 1x RTX 2080 Ti
RTX 2080 Ti - FP16 vs. FP32
Using FP16 can reduce training times and enable larger batch sizes/models without significantly impacting the accuracy of the trained model. Compared with FP32, FP16 training on the RTX 2080 Ti is...
- 59% faster on ResNet-50
- 52% faster on ResNet-152
- 47% faster on Inception v3
- 34% faster on Inception v4
- 50% faster on VGG-16
- 38% faster on AlexNet
- 31% faster on SSD300
as measured by the # of images processed per second during training. This gives an average speed-up of +44.6%.
Caveat emptor: If you're new to machine learning or simply testing code, we recommend using FP32. Lowering precision to FP16 may interfere with convergence.
GPU Prices
- RTX 2080 Ti: $1,199.00
- RTX 2080: $799.00
- Titan RTX: $2,499.00
- Titan V: $2,999.00
- Tesla V100 (32 GB): ~$8,200.00
- GTX 1080 Ti: $699.00
- Titan Xp: $1,200.00
Methods
- For each model we ran 10 training experiments and measured # of images processed per second; we then averaged the results of the 10 experiments.
- For each GPU / neural network combination, we used the largest batch size that fit into memory. For example, on ResNet-50, the V100 used a batch size of 192; the RTX 2080 Ti use a batch size of 64.
- We used synthetic data, as opposed to real data, to minimize non-GPU related bottlenecks
- Multi-GPU training was performed using model-level parallelism
Hardware
- Single-GPU training: Lambda Quad - Deep Learning Workstation. CPU: i9-7920X / RAM: 64 GB DDR4 2400 MHz.
- Multi-GPU training: Lambda Blade - Deep Learning Server. CPU: Xeon E5-2650 v4 / RAM: 128 GB DDR4 2400 MHz ECC
- V100 Benchmarks: Lambda Hyperplane - V100 Server. CPU: Xeon Gold 6148 / RAM: 256 GB DDR4 2400 MHz ECC
Software
- Ubuntu 18.04 (Bionic)
- TensorFlow 1.12
- CUDA 10.0.130
- cuDNN 7.4.1
Run Our Benchmarks On Your Own Machine
Our benchmarking code is on github. We'd love it if you shared the results with us by emailing s@lambdalabs.com or tweeting @LambdaAPI.
Step #1: Clone Benchmark Repository
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
Step #2: Run Benchmark
- Input a proper gpu_index (default 0) and num_iterations (default 10)
cd lambda-tensorflow-benchmark
./benchmark.sh gpu_index num_iterations
Step #3: Report Results
- Check the repo directory for folder <cpu>-<gpu>.logs (generated by benchmark.sh)
- Use the same num_iterations in benchmarking and reporting.
./report.sh <cpu>-<gpu>.logs num_iterations
Raw Benchmark Data
FP32: # Images Processed Per Sec During TensorFlow Training (1 GPU)
| Model / GPU | RTX 2080 Ti | RTX 2080 | Titan RTX | Titan V | V100 | Titan Xp | 1080 Ti |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 294 | 213 | 330 | 300 | 405 | 236 | 209 |
| ResNet-152 | 110 | 83 | 129 | 107 | 155 | 90 | 81 |
| Inception v3 | 194 | 142 | 221 | 208 | 259 | 151 | 136 |
| Inception v4 | 79 | 56 | 96 | 77 | 112 | 63 | 58 |
| VGG16 | 170 | 122 | 195 | 195 | 240 | 154 | 134 |
| AlexNet | 3627 | 2650 | 4046 | 3796 | 4782 | 3004 | 2762 |
| SSD300 | 149 | 111 | 169 | 156 | 200 | 123 | 108 |
FP16: # Images Processed Per Sec During TensorFlow Training (1 GPU)
| Model / GPU | RTX 2080 Ti | RTX 2080 | Titan RTX | Titan V | V100 | Titan Xp | 1080 Ti |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 466 | 329 | 612 | 539 | 811 | 289 | 263 |
| ResNet-152 | 167 | 124 | 234 | 181 | 305 | 104 | 96 |
| Inception v3 | 286 | 203 | 381 | 353 | 494 | 169 | 156 |
| Inception v4 | 106 | 74 | 154 | 116 | 193 | 67 | 62 |
| VGG16 | 255 | 178 | 383 | 383 | 511 | 166 | 149 |
| AlexNet | 4988 | 3458 | 6627 | 6746 | 8922 | 3104 | 2891 |
| SSD300 | 195 | 153 | 292 | 245 | 350 | 136 | 123 |