
We're going to cover both how Lambda Cloud can save a Machine Learning Engineer time and money and also demonstrate training YoloV5 with that same Lambda infrastructure.
Lambda Cloud has the cheapest A100 GPUs available. Here's what it will cost you to follow this blog post:
Cost of training YoloV5-Large for 100 epochs on Lambda Cloud: $4.03
Dataset used: WiderFace (26GB)
Training time for 100 epochs on 4xA100: 55 mins
Table of Contents

In this post, we’re going to cover:
- Spinning up a new 4xA100 GPU instance on Lambda Cloud
- How to train the highly effective YoloV5 object detection and classification model on a dataset of your choice
- Evaluation of results on the WiderFace dataset
All of the code used in this tutorial (and more) can be found in this GitHub repository. The repo also contains the code in Jupyter notebook format, which can be launched and run directly in Lambda Cloud.
Spinning up a 4xA100 GPU server
On Lambda Cloud, this task is trivial. After account creation and adding your SSH key, it's as simple as a few clicks.
- Launch the instance
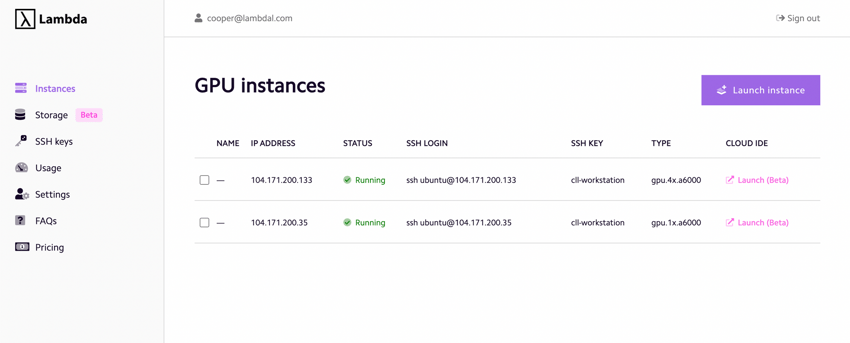
Before launching an instance, you can optionally add a persistent storage unit to your server, in case you have data that should persist after shutdown.
2. Select 4xA100 as your GPU server type, select your SSH key, and hit "Launch"
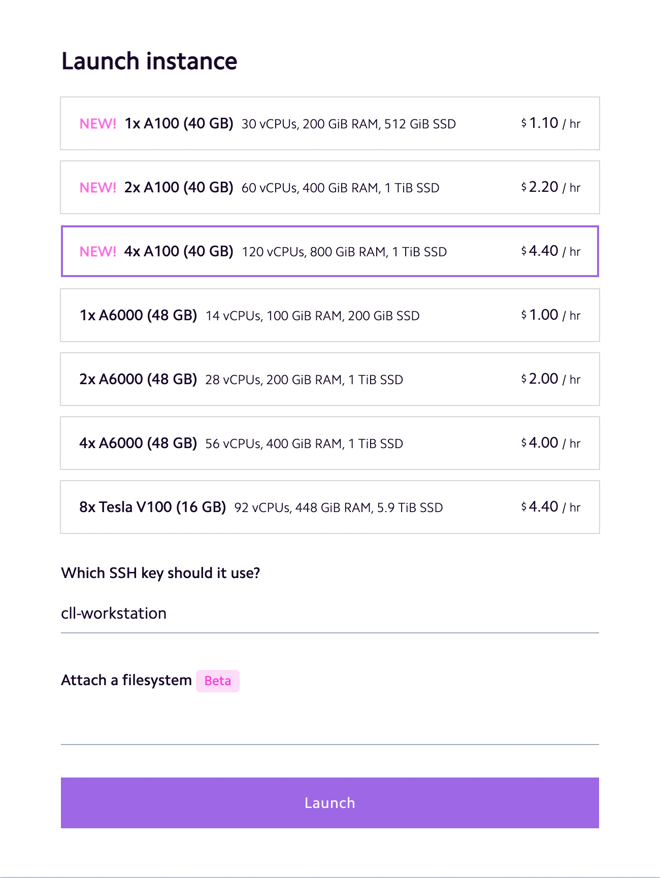
At first, you'll see the new instance with a status of "Booting", as Lambda Cloud provisions your new server. Note that provisioning can take several minutes:

After the status changes to "Running", you can use the ubuntu@<ip_address> field on the homepage to access your newly provisioned 4xA100 server via ssh.
It's also possible to launch a Jupyter notebook directly in the new instance. All that you need to do is click the "Launch (Beta)" link under the "Cloud IDE" field, and Lambda Cloud will launch a Jupyter Hub session in your browser that is connected to your new instance. The Jupyter Hub launch button is highlighted in a red rectangle below:

Preparing the data
To begin, run the following shell script to clone the demo repository, clone YoloV5, install its requirements, and install some packages that we'll be using as well.
git clone https://github.com/LambdaLabsML/examples
cd examples/yolov5
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements.txt
cd -
pip install tqdm datasets wandb joblibFor training YoloV5 (and for new object detection models in general), much of the work is converting your particular dataset into a format understandable by the library you're using. In this case, we need to produce two directories:
1.<yolov5_root>/data/images
2. <yolov5_root>/data/labels
The locations of the data folders and the .yaml file are communicated to YoloV5 via arguments to the train.py command, but we'll assume you're placing the images and labels in <yolov5_root>/data for simplicity.
YoloV5 also requires a .yaml file with some metadata about your particular dataset. The file should look like this:
train: <path_to_train_dir>/images
val: <path_to_val_dir>/images
test: <path_to_test_dir>/images
nc: 1 # number of distinct classes
names: ['class_1', 'class_2', ...]Note that the images folder and the labels folder need to exist in the same parent directory. YoloV5 assumes this is the case.
For managing the dataset, we've opted to use HuggingFace Datasets to download and iterate over the WiderFace dataset, which is a face detection dataset with 12,880 training images and 12,880 test images. This dataset provides images of human faces in realistic contexts (not solely portrait shots, like FFHQ or CelebA), making it an interesting face detection dataset on which to demo YoloV5.
Why YoloV5?
YoloV5 offers excellent ease of use, configurability, and transparency. Whereas HuggingFace Models/Transformers don't always offer source code, YoloV5 does, on top of excellent integrations with experiment tracking. Aside from a practicality standpoint, YoloV5 is also a known quantity in terms of performance - it's fast, accurate, and quick to train (which means cheap). For a team's first stab at any object detection task, YoloV5 makes a lot of sense as a solution.
Why HuggingFace Datasets?
The ease of use of HuggingFace Datasets is compelling. For downloading and iterating over WiderFace, we only need two lines of code. That said, we do need to convert the data from HuggingFace Datasets format (.arrow table files, under the hood) into the directory structure used by YoloV5, as YoloV5 doesn't have an easy route (yet) to subclassing a Dataset class and implementing a function like __getitem__. We have provided helper functions in the repository that will perform the necessary conversions.
If you were to use a local dataset or download a dataset from a source other than HuggingFace, the rest of the conversion code still applies: just place images in <data_dir>/images, labels in <data_dir>/labels, create a configuration .yaml and tell YoloV5 at train-time where it can find those files (as seen at the end of this section).
At a high level, our code for downloading and converting the dataset, creating the YoloV5 metadata .yaml, and downloading pretrained YoloV5 weights looks like this:
import os
import sys
from joblib import Parallel, delayed
from pathlib import Path
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import numpy as np
from datasets import load_dataset
from datasets import IterableDataset
from tqdm import tqdm
from yolov5.utils.downloads import attempt_download
...
if __name__ == "__main__":
wider_face = download_dataset()
yolo_train_dir = "./data/yolo/train"
convert_to_yolov5_format(wider_face, yolo_train_dir)
yolo_test_dir = "./data/yolo/test"
convert_to_yolov5_format(wider_face, yolo_test_dir)
create_yolov5_dataset_yaml(yolo_train_dir, yolo_test_dir)
attempt_download('yolov5/weights/yolov5s.pt')
attempt_download('yolov5/weights/yolov5m.pt')
attempt_download('yolov5/weights/yolov5l.pt')You can run this script with python prepare_dataset.py, located in the examples/yolov5 directory.
Training YoloV5
At this point, you're ready to kick off training using the following commands:
cd yolov5
python -m torch.distributed.launch --nproc_per_node 4 \
train.py --data data/wider_face.yaml --batch-size 128 \
--epochs 10 --img-size 768 --project runs/train \
--name wider_face --weights weights/yolov5s.pt \
--cache --workers 16A couple of things to note: first, you need to cd inside the YoloV5 repo, so your path should be examples/yolov5/yolov5. Second, you can easily change the weights to specify one of the larger model files, though these will take longer to train.
Other useful args to note include:
--nproc_per_node allows you to specify how many GPUs (in case you want to use a smaller instance than a 4xA100).
--data specify the .yaml file containing the required metadata about your dataset
--batch-size total batch size. Divide by --nproc_per_node to get the per-GPU batch-size
--epochs number of epochs to train
--img-size YoloV5 will resize images to this size (height=width=img-size) before training on them. For WiderFaces, 512 is too small and causes poor performance due to smaller faces being reduced to an unrecognizable few pixels. 1024 yields slightly higher AP, but is slower to train than 768.
--projects where to store data from your runs
--name saves output to project/<name>
--weights pretrained weights to use for training
Some useful tips:
--cachecan be used to cache images in RAM, rather than reading from storage each time.--workersused to specify number of CPU workers to use for dataloading. Manually setting this may result in performance increases, depending on your hardware.--novalis a useful option whose presence prevents testing validation sets until after all training epochs, which can be useful if you know you want a run to go to completion before testing. On WiderFace, the 12,880 validation images add considerable overhead to training.- Running
pip install wandbbefore training will ensure that YoloV5 logs to Weights and Biases (and W&B will prompt you for your API key, if YoloV5 detectswandbamong your installed packages).
When you launch a training run, you should see output similar to this:
YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected.
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 270 layers, 7022326 parameters, 7022326 gradients, 15.9 GFLOPs
Transferred 343/349 items from weights/yolov5s.pt
AMP: checks passed ✅
Scaled weight_decay = 0.001
optimizer: SGD with parameter groups 57 weight (no decay), 60 weight, 60 bias
train: Scanning '/home/ubuntu/yolov5_blog_post/yolov5/data/train/labels.cache' images and labels... 12880 found, 0 missing, 4 empty, 1 corrupt: 100%|██████████| 12880/12880 [00:00<?, ?it/s]
train: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/train/images/10969.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.0254]
train: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/train/images/12381.png: 1 duplicate labels removed
train: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/train/images/3232.png: 1 duplicate labels removed
train: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/train/images/7207.png: 1 duplicate labels removed
val: Scanning '/home/ubuntu/yolov5_blog_post/yolov5/data/test/labels.cache' images and labels... 12880 found, 0 missing, 4 empty, 1 corrupt: 100%|██████████| 12880/12880 [00:00<?, ?it/s]
val: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/test/images/10969.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.0254]
val: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/test/images/12381.png: 1 duplicate labels removed
val: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/test/images/3232.png: 1 duplicate labels removed
val: WARNING: /home/ubuntu/yolov5_blog_post/yolov5/data/test/images/7207.png: 1 duplicate labels removed
Plotting labels to runs/train/wider_face15/labels.jpg...
AutoAnchor: 3.55 anchors/target, 0.984 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Image sizes 768 train, 768 val
Using 32 dataloader workers
Logging results to runs/train/wider_face15
Starting training for 100 epochs...
Epoch gpu_mem box obj cls labels img_size
0/99 9.54G 0.09993 0.05752 0 449 768: 57%|█████▋ | 58/101 [00:33<00:19, 2.19it/s] Evaluating results
Typical output of a trained YoloV5 model will look like this, with bounding boxes drawn around detected objects (in our case, just faces), and an output probability on a scale of 0 to 1 that bounding box does indeed belong to the indicated class.
WiderFace Evaluation
WiderFace evaluation is split into three "levels" based on difficulty - Easy, Medium, and Hard - where Easy is a subset of Medium is a subset of Hard. You can explore current state-of-the-art performance on each of these WiderFace levels on PapersWithCode here.
Our validation set results (in mAP @ IoU 0.5 on the entire 3,226 validation images of WiderFace) from training YoloV5 small, medium, and large variants are for 100 epochs and 300 epochs are as follows:
| YoloV5-small | YoloV5-medium | YoloV5-large | |
|---|---|---|---|
| 100 epochs @ img_size 768 | 67.5 | 77.8 | 78.6 |
| 300 epochs @ img_size 768 | 75.6 | 78.5 | 79.8 |
| 100 epochs @ img_size 1024 | 78.9 | 80.8 | 81.5 |
| 300 epochs @ img_size 1024 | 79.1 | 80.9 | 81.5 |
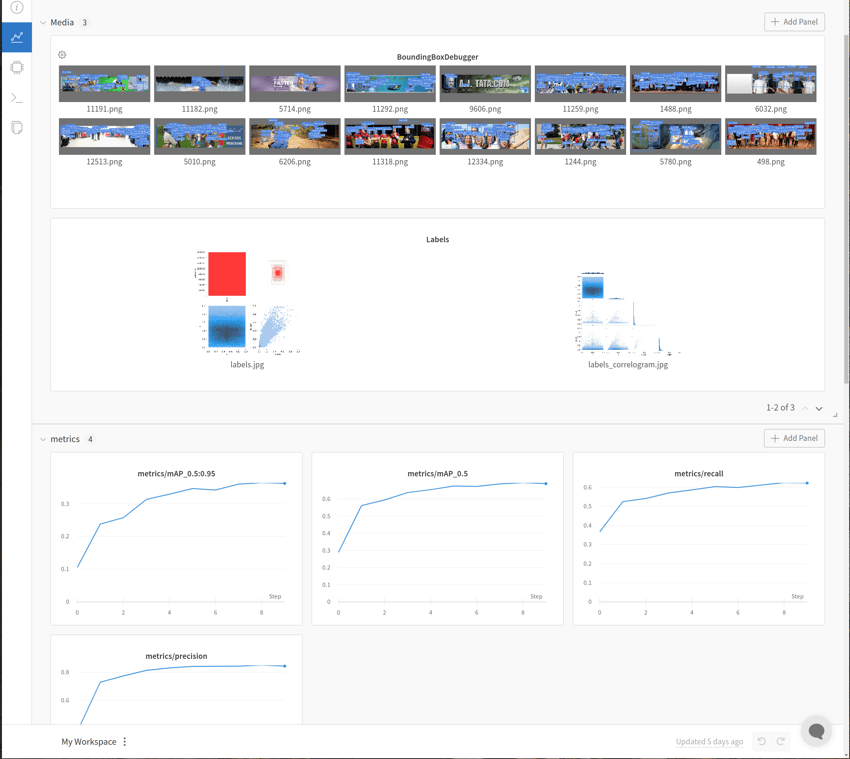
In trying to optimize performance of any model, it is helpful to have robust experiment tracking software. YoloV5 comes with Weights and Biases (W&B) support built-in and by default logs mean average precision, precision, recall, and all of the loss components for both train and val sets to the W&B experiment dashboard.
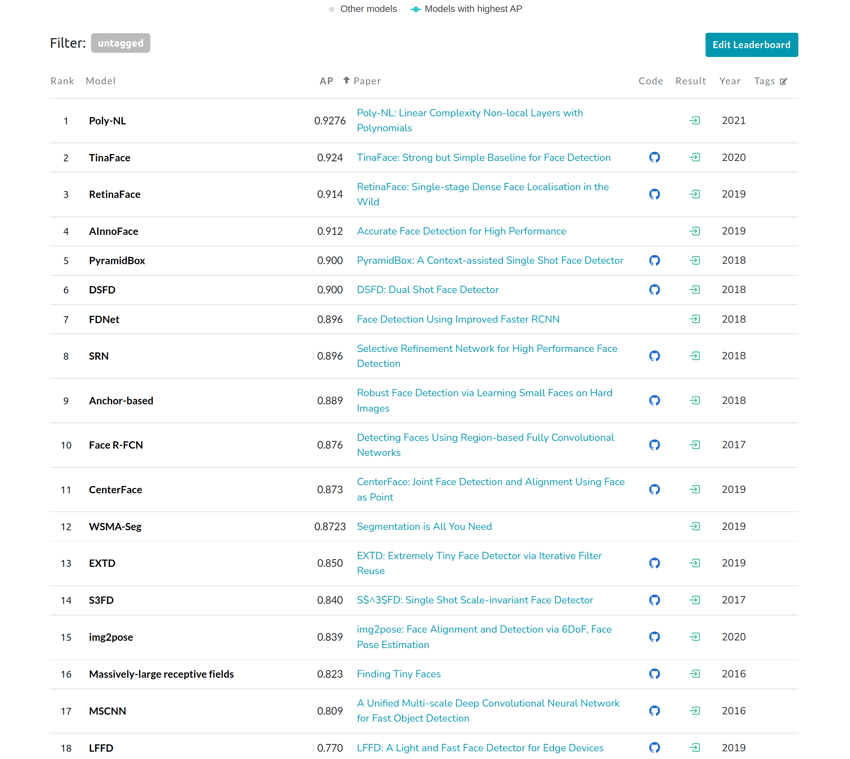
For understanding how our model is performing at this particular face recognition task, PapersWithCode offers a ranking of model performance on the WiderFace dataset test sets. While it isn't the case that we can easily test YoloV5 performance on this set (as the test set ground truth labels are retained by the dataset creators to ensure fairness), we can at least compare performance of our model on the WiderFace validation set. The mAP we achieved with YoloV5-large of 81.5, while high, is still a bit off from the leaders, though comparable to 2017 state-of-the-art:
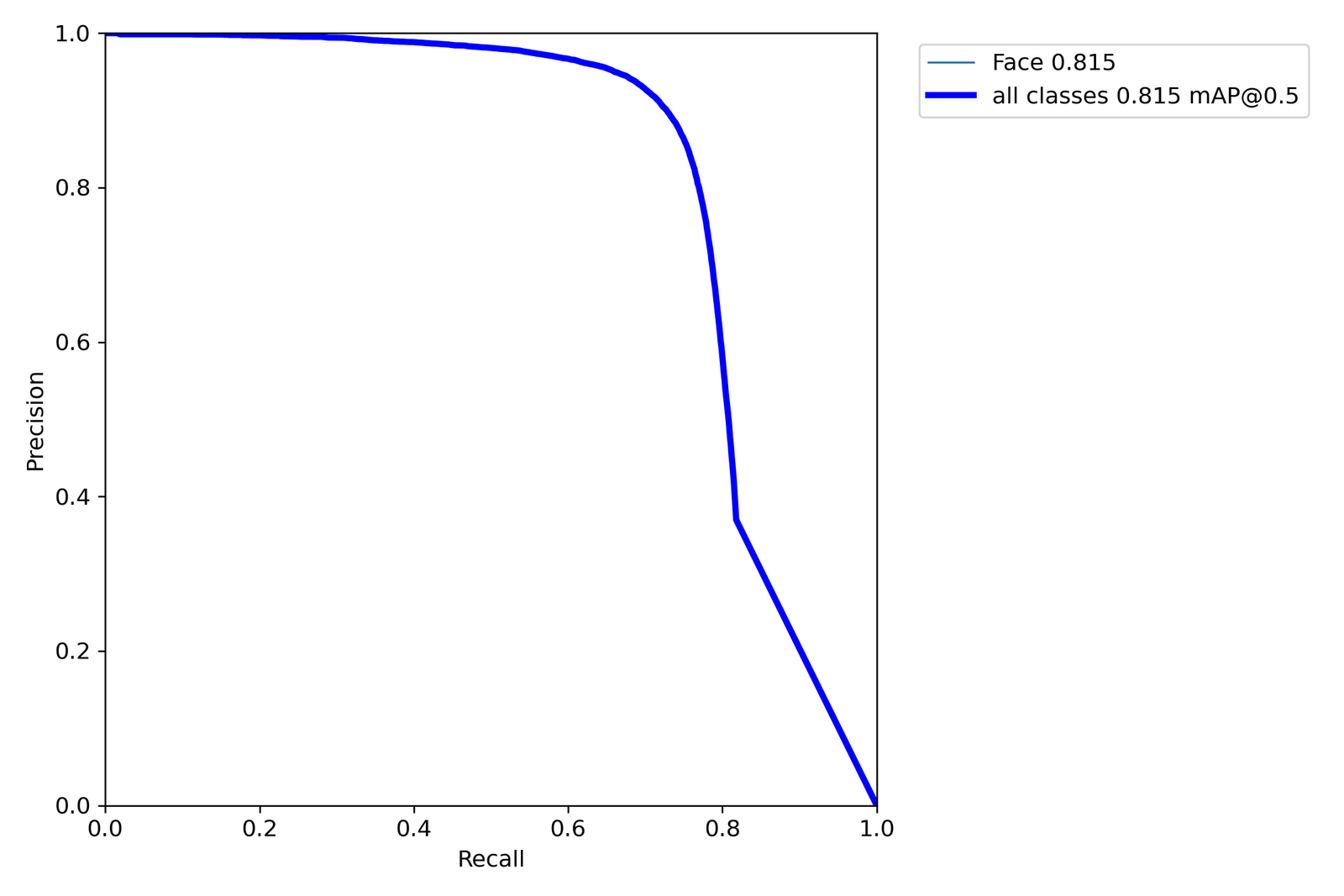
We also found it helpful that YoloV5 produced plots such as PR curves, F1 curves, as well as a .csv of all of the metrics logged to W&B.
In summary, Lambda Cloud + YoloV5 offers some of the cheapest and easiest object detection training available to ML practitioners currently. Depending on the problem and your error tolerance, you may need to opt for a more custom solution (as evidenced by the distance of YoloV5 from state-of-the-art on WiderFace), but for obtaining quick, accurate results with a lot of the tedious aspects of piecing together an ML pipeline figured out for you already, Ultralytics offers a very compelling package in YoloV5.