
Titan RTX vs. 2080 Ti vs. 1080 Ti vs. Titan Xp vs. Titan V vs. Tesla V100.
For this post, Lambda engineers benchmarked the Titan RTX's deep learning performance vs. other common GPUs. We measured the Titan RTX's single-GPU training performance on ResNet50, ResNet152, Inception3, Inception4, VGG16, AlexNet, and SSD. Multi-GPU training speeds are not covered.
View our deep learning workstation
TLDR;
Benchmarks were conducted on Lambda's deep learning workstation with 2x Titan RTX GPUs.
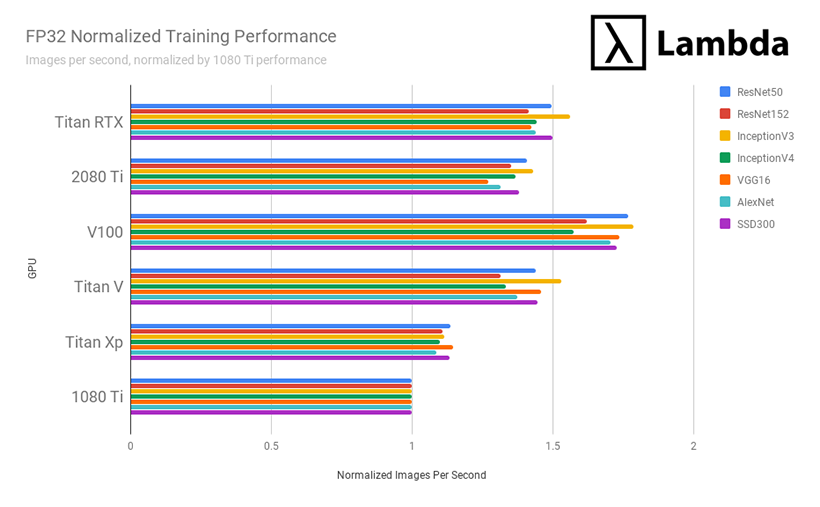
Titan RTX's FP32 performance is...
- ~8% faster than the RTX 2080 Ti
- ~47% faster than the GTX 1080 Ti
- ~31% faster than the Titan Xp
- ~4% faster than the Titan V
- ~14% slower that the Tesla V100 (32 GB)
when comparing # images processed per second while training.
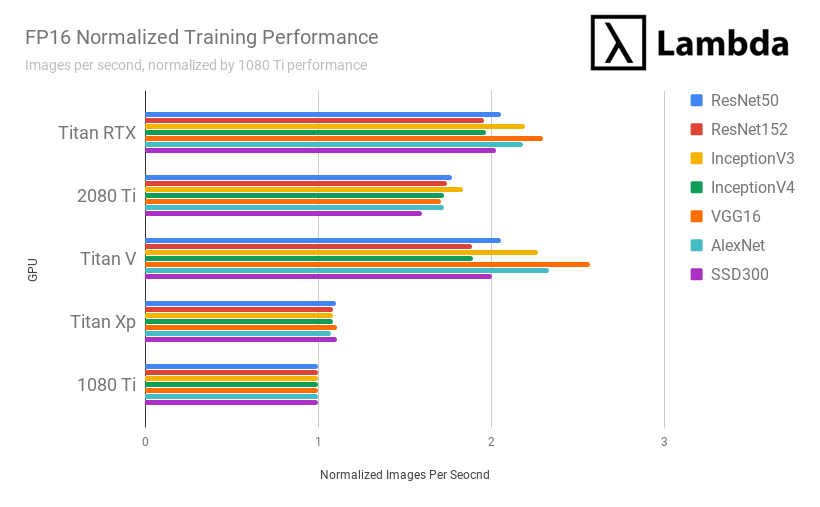
Titan RTX's FP16 performance is...
- 21% faster than the RTX 2080 Ti
- 110% faster than the GTX 1080 Ti
- 92% faster than the Titan Xp
- 2% slower than the Titan V
- Stay tuned for comparison to the V100 (32 GB)
when comparing # images processed per second while training.
Pricing
- Titan RTX: $2,499.00 (source: NVIDIA's website)
- RTX 2080 Ti: ~$1,300.00 (source: Amazon)
Conclusion
- RTX 2080 Ti is the best GPU for Machine Learning / Deep Learning if... 11 GB of GPU memory is sufficient for your training needs (for many people, it is). The 2080 Ti offers the best price/performance among the Titan RTX, Tesla V100, Titan V, GTX 1080 Ti, and Titan Xp.
- Titan RTX is the best GPU for Machine Learning / Deep Learning if... 11 GB of memory isn't sufficient for your training needs. However, before concluding this, try training at half-precision (16-bit). This effectively doubles your GPU memory at the cost of training accuracy. If you're already successfully training at FP16 and 11 GB still isn't enough, then choose the Titan RTX -- otherwise, go with the RTX 2080 Ti. At half-precision, the Titan RTX offers effectively 48 GB of GPU memory.
- Tesla V100 is the best GPU for Machine Learning / Deep Learning if... price isn't important, you need every bit of GPU memory available, or time to market of your product is of utmost important.
Methods
- All models were trained on a synthetic dataset to isolate GPU performance from CPU pre-processing performance and reduce spurious I/O bottlenecks.
- For each GPU/model pair, 10 training experiments were conducted and then averaged.
- The "Normalized Training Performance" of a GPU is calculated by dividing its images / sec performance on a specific model by the images / sec performance of the 1080 Ti on that same model.
- The Titan RTX, 2080 Ti, Titan V, and V100 benchmarks utilized Tensor Cores.
Batch-sizes
| Model | Batch Size |
|---|---|
| ResNet-50 | 64 |
| ResNet-152 | 32 |
| InceptionV3 | 64 |
| InceptionV4 | 16 |
| VGG16 | 64 |
| AlexNet | 512 |
| SSD | 32 |
Software
- Ubuntu 18.04
- TensorFlow: v1.11.0
- CUDA: 10.0.130
- cuDNN: 7.4.1
- NVIDIA Driver: 415.25
Raw Results
The tables below display the raw performance of each GPU while training in FP32 mode (single precision) and FP16 mode (half-precision), respectively. Note that the unit measured is # of images processed per second and we rounded results to the nearest integer.
FP32 - Number of images processed per second
| Model / GPU | Titan RTX | 1080 Ti | Titan Xp | Titan V | 2080 Ti | V100 |
|---|---|---|---|---|---|---|
| ResNet50 | 312 | 208 | 237 | 300 | 294 | 369 |
| ResNet152 | 115 | 81 | 90 | 107 | 110 | 132 |
| InceptionV3 | 212 | 136 | 151 | 208 | 194 | 243 |
| InceptionV4 | 83 | 58 | 63 | 77 | 79 | 91 |
| VGG16 | 191 | 134 | 154 | 195 | 170 | 233 |
| AlexNet | 3980 | 2762 | 3004 | 3796 | 3627 | 4708 |
| SSD300 | 162 | 108 | 123 | 156 | 149 | 187 |
FP16 - Number of images processed per second
| Model / GPU | Titan RTX | 1080 Ti | Titan Xp | Titan V | 2080 Ti |
|---|---|---|---|---|---|
| ResNet50 | 540 | 263 | 289 | 539 | 466 |
| ResNet152 | 188 | 96 | 104 | 181 | 167 |
| InceptionV3 | 342 | 156 | 169 | 352 | 286 |
| InceptionV4 | 121 | 61 | 67 | 116 | 106 |
| VGG16 | 343 | 149 | 166 | 383 | 255 |
| AlexNet | 6312 | 2891 | 3104 | 6746 | 4988 |
| SSD300 | 248 | 122.49 | 136 | 245 | 195 |
Reproduce the benchmarks yourself
All benchmarking code is available on Lambda's GitHub repo. Share your results by emailing s@lambdalabs.com or tweeting @LambdaAPI. Be sure to include the hardware specifications of the machine you used.
Step One: Clone benchmark repo
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
Step Two: Run benchmark
- Input a proper gpu_index (default 0) and num_iterations (default 10)
cd lambda-tensorflow-benchmark
./benchmark.sh gpu_index num_iterations
Step Three: Report results
- Check the repo directory for folder <cpu>-<gpu>.logs (generated by benchmark.sh)
- Use the same num_iterations in benchmarking and reporting.
./report.sh <cpu>-<gpu>.logs num_iterations