
This tutorial is about making a character-based text generator using a simple two-layer LSTM. It will walk you through the data preparation and the network architecture. TensorFlow implementation is available at this repo.
Here is a snippet of Shakespeare generated from the network:
ORLANDO:
The days are flunch and sure.
OLIVIA:
And we will be well beloved, once well carer.
When thou hast kill'd his life?
First Lord:
You speak and never need me not.
DIANIA:
I great him, some little dreadful eye is bleed?
I should not fight in the hunger hence on his elements,
Get on his scarce I elwardly: if we come to all my royal parentage;
We hold that plain pond in honour would have known
Data Preparation
Our training data has 167204 lines of sentences sampled from works of Shakespeare. Here is a snippet of it:
First Citizen:
Before we proceed any further, hear me speak.
All:
Speak, speak.
First Citizen:
You are all resolved rather to die than to famish?
All:
Resolved. resolved.
The first thing is to process this txt file so it can be useful for training text generator.
Step One: Read the tinyshakespare into a list of characters. This should be straight forward – just use your favorite text processing function to read the txt file into an array of characters. The entire training set has 4573338 characters. Here are the first 100:
['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n', 'B', 'e', 'f', 'o', 'r', 'e', ' ', 'w', 'e', ' ', 'p', 'r', 'o', 'c', 'e', 'e', 'd', ' ', 'a', 'n', 'y', ' ', 'f', 'u', 'r', 't', 'h', 'e', 'r', ',', ' ', 'h', 'e', 'a', 'r', ' ', 'm', 'e', ' ', 's', 'p', 'e', 'a', 'k', '.', '\n', '\n', 'A', 'l', 'l', ':', '\n', 'S', 'p', 'e', 'a', 'k', ',', ' ', 's', 'p', 'e', 'a', 'k', '.', '\n', '\n', 'F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':', '\n', 'Y', 'o', 'u']
Step Two: Build numerical representation for the characters. We need numerical representation to run computation. To do so we build a vocabulary and encode each character by a number (index in the vocabulary). There are in total 67 different characters in the training data, so the indices will be 0 - 66. In order to decide with index goes to which character, we sort these characters by how frequently they appear in Shakespeare's works :
{' ': 696192, 'e': 386358, 't': 272682, 'o': 268966, 'a': 230600, 'h': 208379, 's': 204735, 'n': 200680, 'r': 197473, 'i': 187325, '\n': 167204, 'l': 139513, 'd': 126926, 'u': 108803, 'm': 91597, 'y': 82288, ',': 79977, 'w': 70463, 'f': 65373, 'c': 63789, 'g': 54195, 'I': 45100, ':': 44576, 'b': 44554, 'p': 44428, 'A': 36185, '.': 33850, 'v': 32787, 'T': 29514, 'k': 28776, "'": 24028, 'S': 23489, 'E': 23256, 'O': 23084, 'N': 20081, 'R': 18655, 'L': 17683, ';': 15364, 'C': 14359, 'H': 13520, 'W': 13088, 'M': 11775, 'U': 11568, 'B': 10895, 'D': 10545, '?': 10167, 'F': 9210, '!': 8765, '-': 8405, 'G': 8377, 'P': 7807, 'Y': 6641, 'K': 4517, 'V': 2759, 'j': 2650, 'q': 2591, 'x': 2436, 'J': 1619, 'z': 1213, 'Q': 836, 'Z': 347, 'X': 268, '3': 27, '&': 18, '[': 3, ']': 3, '$': 1}
The top-3 frequently appearing characters are space, e and t. The least frequent character is $ – which is, sadly, a mistake in the txt file. We index each character based on this order: space is 0, e is 1 and so on. Now we have the numerical encoding of the entire training data. Here are first 100 characters:
[46 9 8 6 2 0 38 9 2 9 58 1 7 22 10 43 1 18 3 8 1 0 17 1
0 24 8 3 19 1 1 12 0 4 7 15 0 18 13 8 2 5 1 8 16 0 5 1
4 8 0 14 1 0 6 24 1 4 29 26 10 10 25 11 11 22 10 31 24 1 4 29
16 0 6 24 1 4 29 26 10 10 46 9 8 6 2 0 38 9 2 9 58 1 7 22
10 51 3 13]
Step Three: Prepare training examples. Now we have the numerical representation of the data. Next, we need to prepare examples that are useful for training. As far as a character-based text generator's concern, the examples are sentence pairs: the source are sentences randomly selected from the training data, the target are offset-by-one versions of the source:
Source [46 9 8 6 2 0 38 9 2 9 58 1 7 22]
Target [9 8 6 2 0 38 9 2 9 58 1 7 22 10]
Or in characeters:
Source: ['F', 'i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n']
Target: ['i', 'r', 's', 't', ' ', 'C', 'i', 't', 'i', 'z', 'e', 'n', ':']
In such way, the network learns to predict the next character in the target sentence based on all the characters it has seen so far in the source sentence. For example,
[46 9 8 ] --> [6]
[46 9 8 6 ] --> [2]
[46 9 8 6 2 ] --> [0]
Or in characters:
['F', 'i', 'r'] --> ['s']
['F', 'i', 'r', 's'] --> ['t']
['F', 'i', 'r', 's', 't'] --> [' ']
Notice the examples don't have to be complete sentences. In fact, we should use a fixed length and batch the sentences for fast training. In this blog we use sentences of 50 characters and find the results quite satisfactory.
The Model
Now, it is time to design the network. In this tutorial we will use a simple 2-layer LSTM. It looks like this:
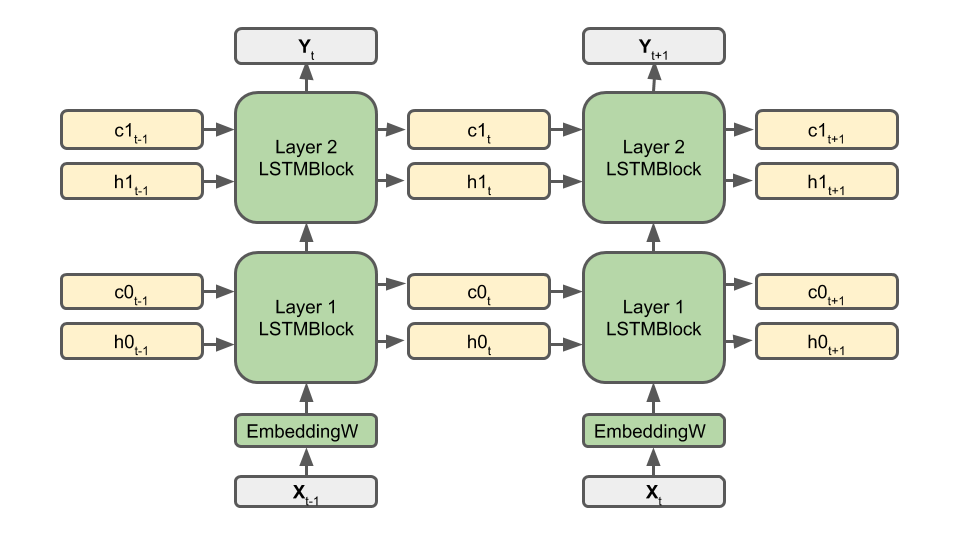
The input character (encoded as a number between 0 - 66) is first embedded as a 256 dimensional vector: it is first converted into a 67 dimensional one-hot vector, then mapped into the 256 dimensional feature space by the projection matrix EmbeddingW. EmbeddingW is randomly initialized and trained jointly with the rest of the network.
Then come the LSTM layers. Layer 1 takes the embedded input character X and its memory cells (h0 and c0) from the previous steps t-1, then computes the input for Layer 2 and updates its memory cells (h0 and c0) for step t. Similarly, Layer 2 produces the output prediction Y and update its own memory cells ( h1 and c1) for the next step.
During training, the input X is a character in the source sentence, while the ground truth for prediction Y is the paired character in the target sentence. During testing, the networks takes an random character in the first step, and uses the predicted character as the input for the next step. All memory cells (h0 , c0, h1 and c1) are initialized to zero at the beginning of the training and testing.
We use cross entropy as the loss to train the network. In essence the network looks at each time step and penalize the prediction what does not match the ground truth character in the target sentence.
During testing, The output prediction Y goes through a softmax function, which generates a probability distribution over all 67 characters. The final prediction will be sampled from this probability distribution. One can use a "temperature" hyper-parameter to control the behavior of the generation: low temperature will concentrate the probability around the likely characters, so the generated phrases might be restricted to a limited context or even self-repeat; high temperature, in contrast, will soften the probability distribution so the results are more diverse but prone to artifacts such as misspelling.
Here are some snippets of the generated text:
Temperature = 1.0
QUEEN ELIZABETH:
We did content it.
TRINCULO:
It is Mary wealth of things from hence: for the noble
That makest us here's one Sux Or on thy barge shall to
They stand. Who hath given him this stiff,
To do the quarrel and mothers; and when I do know this last,
nor certains and note your request may get a Tyrus see't and honestess that in his likeness. LADY MACBETH: No. Temperature = 0.1
KING HENRY VI:
What is the matter?
CLAUDIO:
I will not be so much to be so much as a man
That shall be so much as a base and such a stranger than the streets,
And the sun of the world the seas of the streets of the world
That the sun of the world of the world, the sun of the world
That the sea of the world of the streets, and the state
Of the state of the country of the world,
The sea of the world is not the sun of the world.
Temperature = 2.0
KENT:
Escape! nyet and you? Losen, who kep doormy,
Shooved ipfess drzilt tyrann'bhooms. Blawful outfusteiches. Nuncle, half that, to Ajax oul gods, I'll yen,-upon sea-bluence cowards twice.
ARTEMDRHAMI:
Quum-mea'! your teeth articltation.' On tim!' But, long'st.
Upon-diar: is telleged-seede,
With ovizo-emidius fex eftabline opleaf Bglace:
What younl youthful!
Old Grew, if thou mushleed, farefal, nothing from all.
Demo
You can download the demo from this repo.
git clone https://github.com/lambdal/lambda-deep-learning-demo.git