
The NVIDIA H200 Tensor Core GPU is a data center-grade GPU designed for large-scale AI workloads. As the next version of the widely-used NVIDIA H100 GPU, the H200 offers more GPU memory while maintaining a similar compute profile. With our friends at Lambda, we tested Mistral Large, a 123-billion parameter model, on an 8xH200 GPU cluster.
Though the H200 GPUs are highly anticipated for tasks like training, fine-tuning, and long-duration AI processes, Baseten was curious about their potential for inference jobs.
In our testing, we found that H200 GPUs are a good choice for:
- Large models: run 100+ billion parameter models, even in 16-bit precision.
- Large batch sizes: increase throughput on latency-insensitive batch workloads.
- Long input sequences: process sequences with tens of thousands of tokens.
However, outside of these situations, we found that H200s offered minimal performance improvements over H100s. Given that H200s are expected to be more expensive than H100s per hour, many inference tasks will be more cost-efficient on H100 GPUs.
In this article, Baseten breaks down the H200 GPU’s specs, discusses our benchmarking methodology, and shows their benchmark results for high-throughput inference workloads on H200 GPUs.
NVIDIA H200 GPU specs
The H200 GPU has the same compute as an H100 GPU, but with 76% more GPU memory (VRAM) at a 43% higher memory bandwidth.
|
GPU |
NVIDIA H100 SXM |
NVIDIA H200 SXM |
|
GPU Memory (VRAM) |
80 GB HBM3 |
141 GB HBM3e |
|
VRAM Bandwidth |
3.35 TB/s |
4.8 TB/s |
|
Interconnect with NVIDIA NVLink and NVSwitch |
900 GB/s |
900 GB/s |
|
FP16 Compute (Dense) |
989.5 TFLOPS |
989.5 TFLOPS |
|
BLOAT16 Compute (Dense) |
989.5 TFLOPS |
989.5 TFLOPS |
|
FP8 Compute (Dense) |
1,979 TFLOPS |
1,979 TFLOPS |
|
INT8 Compute (Dense) |
1,979 TOPS |
1,979 TOPS |
Compute values are shown without sparsity, as most inference workloads don’t yet benefit from sparsity.
Do note that the H200 GPU is distinct from the GH200 Superchip, which we are in the process of evaluating for inference workloads. These GPUs have similar names, but different hardware, specs, and performance characteristics.
From these specs, we can make some educated guesses about how model performance will look on H200s relative to H100s:
- Time to first token (TTFT) is constrained on compute. We expect TTFT to be roughly equivalent between H200s and H100s, all else being equal.
- Tokens per second (TPS) is constrained on memory bandwidth. We expect TPS to be higher on H200s than H100s, all else being equal. This should decrease our latency and increase our throughput.
- Batch size is constrained on memory capacity. We expect to be able to run larger batch sizes on H200s than H100s, all else being equal. This should increase our throughput.
- KV cache size is constrained on memory capacity. With the increased memory, we expect to be able to perform more KV cache reuse to speed up inference. This should decrease latency and increase throughput.
In the benchmark results below, we’ll see if these assumptions are correct!
Benchmarking hardware specs
We performed our benchmarking on a Lambda On-Demand Instances equipped with eight H200 GPUs.
With 8xH200 GPUs, the cluster had a total of 1,128 GB of VRAM – more than a terabyte – with a 900 GB/s interconnect between the GPUs with NVIDIA NVLink and NVSwitch. Additionally, the server had excellent non-GPU specs:
|
vCPU Cores |
208 |
|
CPU Memory (RAM) |
2.267 TB |
|
RAM to VRAM bandwidth |
55 GB/s |
|
SSD Storage |
2 TB |
Our thanks to Lambda for supplying the cluster for our testing!

Benchmarking methodology
To properly test the H200 GPU, we knew we needed to run batch inference on a large model. We decided to test Mistral Large, a 123-billion parameter LLM. To ensure we were testing the GPUs at their most optimal performance, we used TensorRT-LLM to serve the Mistral Large model.
TensorRT-LLM, an open-source model optimization framework by NVIDIA, works by building dedicated serving engines based on the given model, GPU, quantization, sequence shapes, and batch sizes. Given that we wanted to test many different configurations, manually building and testing these engines would have been time-consuming.
Instead, we used trtllm-bench, a CLI tool for TensorRT-LLM’s built-in benchmarking utilities. trtllm-bench builds and tests engines with many different configurations automatically, saving substantial time and effort. Additionally, trtllm-bench has a set of useful features that make the performance benchmark more realistic:
- Rather than a fixed input and output sequence length, the input and output lengths are each randomized distribution around a target value.
- The inputs are generated from a large and varied dataset to simulate realistic queries.
- Requests are sent in batches to saturate the serving engine’s in-flight batching.
While trtllm-bench didn’t support Mistral Large out of the box at the time of testing, thanks to its open-source codebase we were able to add our own support.
Benchmarking results
We ran benchmarks for a dozen different combinations of batch size and sequence length for each a full 16-bit model and a quantized fp16 model. In the interest of clarity, we’ve selected three representative benchmarks that demonstrate where the H200 GPU is and is not a cost-efficient solution for inference.
Benchmark: Long context input
H200 GPUs perform extremely well with long input sequences thanks to their large VRAM allocation and high VRAM bandwidth. With long input sequences, TPS gets quadratically worse with input length as the GPU needs to process every previous token before generating new tokens, so the H200 is uniquely well-suited for this specific use case.
Examples of real-world applications of this benchmark include summarization (with >256-token output sequences), long-context retrieval, and retrieval-augmented generation.
Benchmark setup
|
Batch size |
64 requests |
|
Quantization |
BF16 |
|
Input sequence length |
32,784 tokens |
|
Output sequence length |
2,048 tokens |
Benchmark results
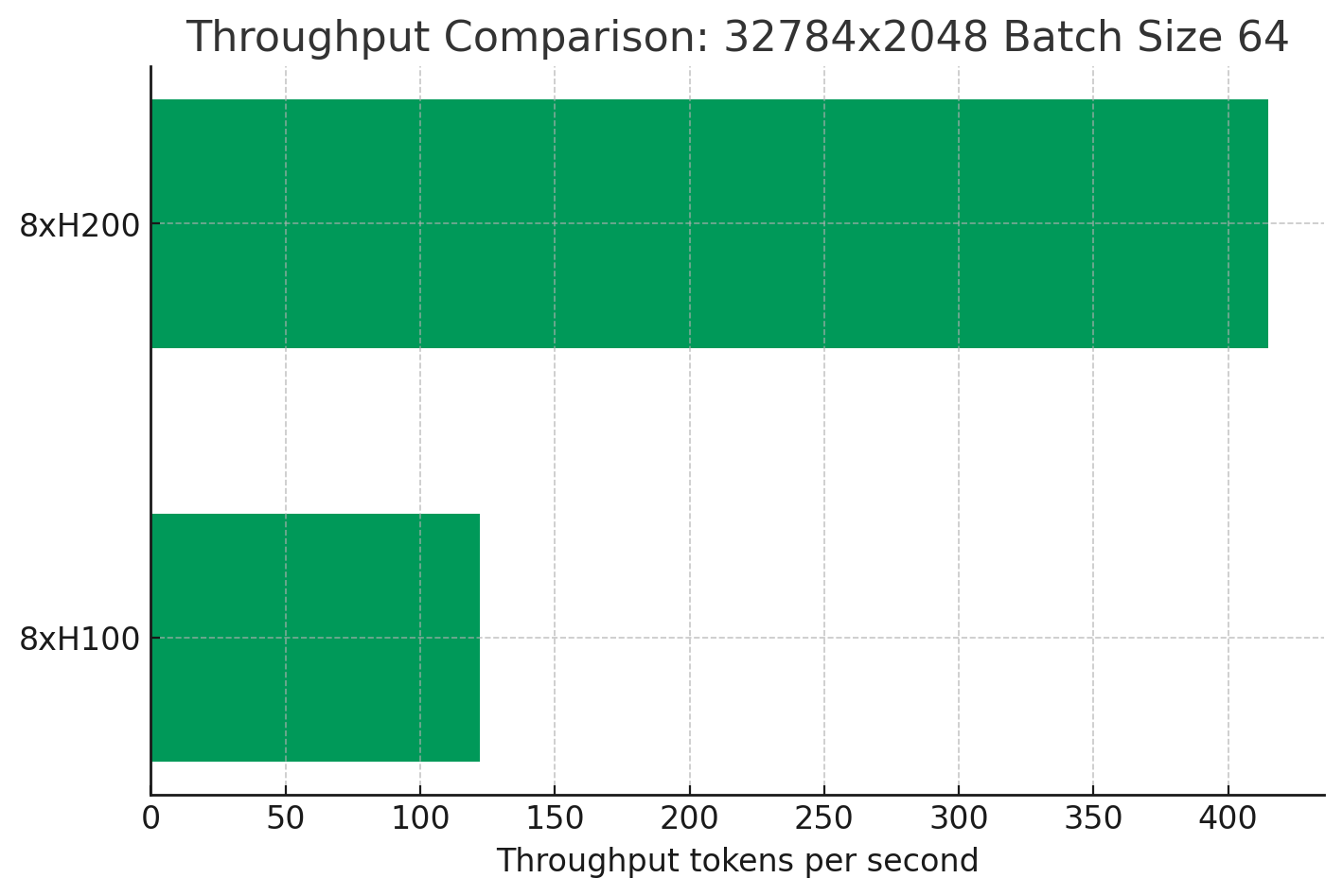
The 8xH200 cluster offers 3.4X higher performance than the 8xH100 cluster for this sequence length and batch size. This is certainly a cost-effective use for H200 GPUs.
Benchmark: High throughput batch inference
H200 GPUs are also good at large batch workloads. In this case, we’ll feed it a batch of over four thousand requests.
This batch performance is thanks to the large VRAM allocation – 141 GB per GPU, over a terabyte on the 8-GPU cluster. With this amount of GPU memory, we can allocate more memory to the KV cache, allowing for inference on large batches.
Real-world examples of this benchmark include any latency-insensitive task where cost per million tokens matters, like scheduled generation runs on a daily cadence.
Benchmark setup
|
Batch size |
4,096 requests |
|
Quantization |
BF16 and FP8 |
|
Input sequence length |
2,048 tokens |
|
Output sequence length |
2,048 tokens |
Benchmark results
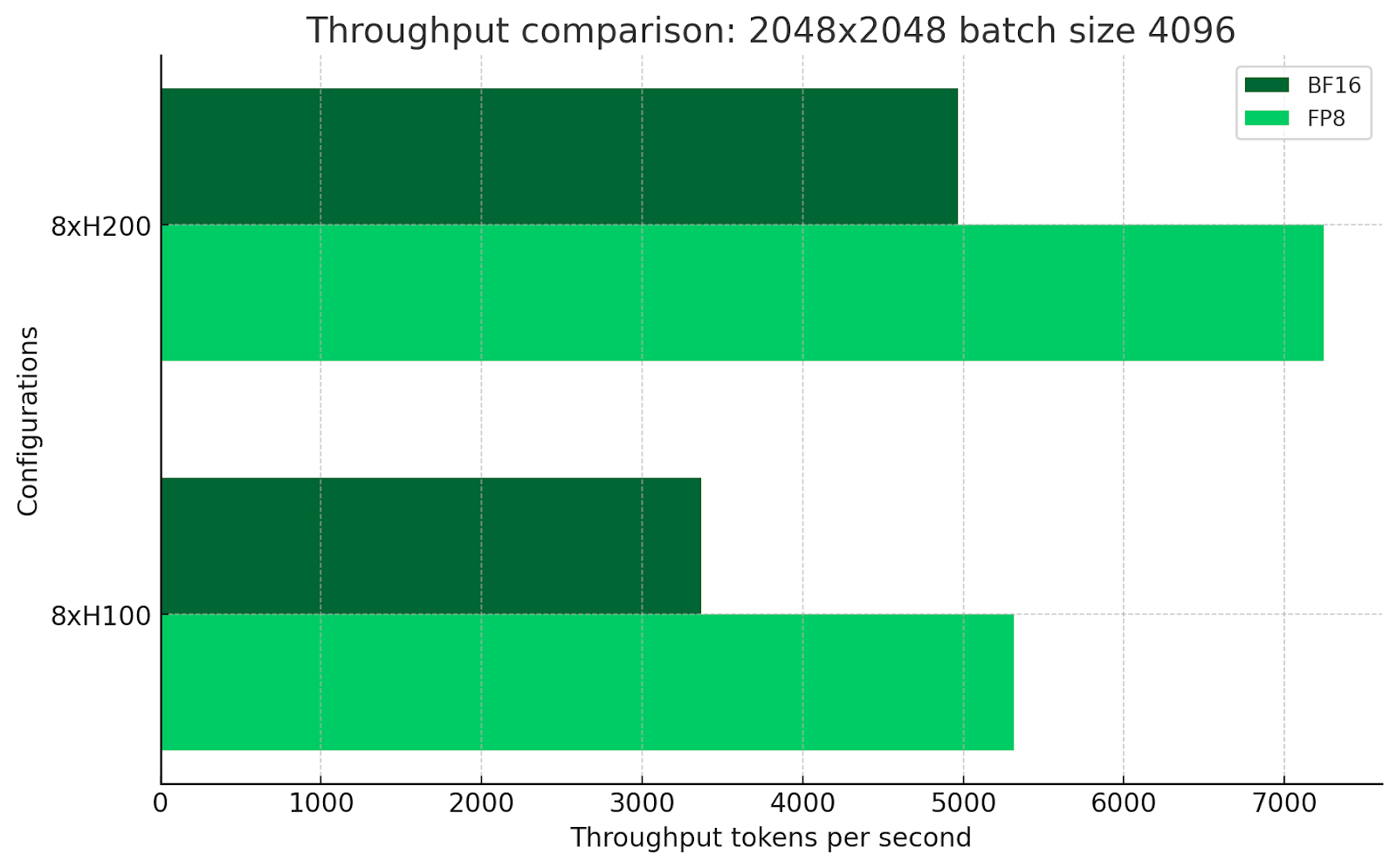
The 8xH200 cluster offers 47% higher performance in BF16 and 36% higher performance in FP8 for this sequence length and batch size. This is likely a cost-effective use of H200 GPUs.
Benchmark: Short context and output
For some workloads, H200 GPUs performed equivalently or better to H100 GPUs.
These benchmarks represent real-world examples like real-time chat applications, code completion tools, and other short-context low-latency inference workloads.
Benchmark setup
|
Batch size |
64 requests |
|
Quantization |
BF16 and FP8 |
|
Input sequence length |
128 tokens |
|
Output sequence length |
2,048 tokens |
Benchmark results
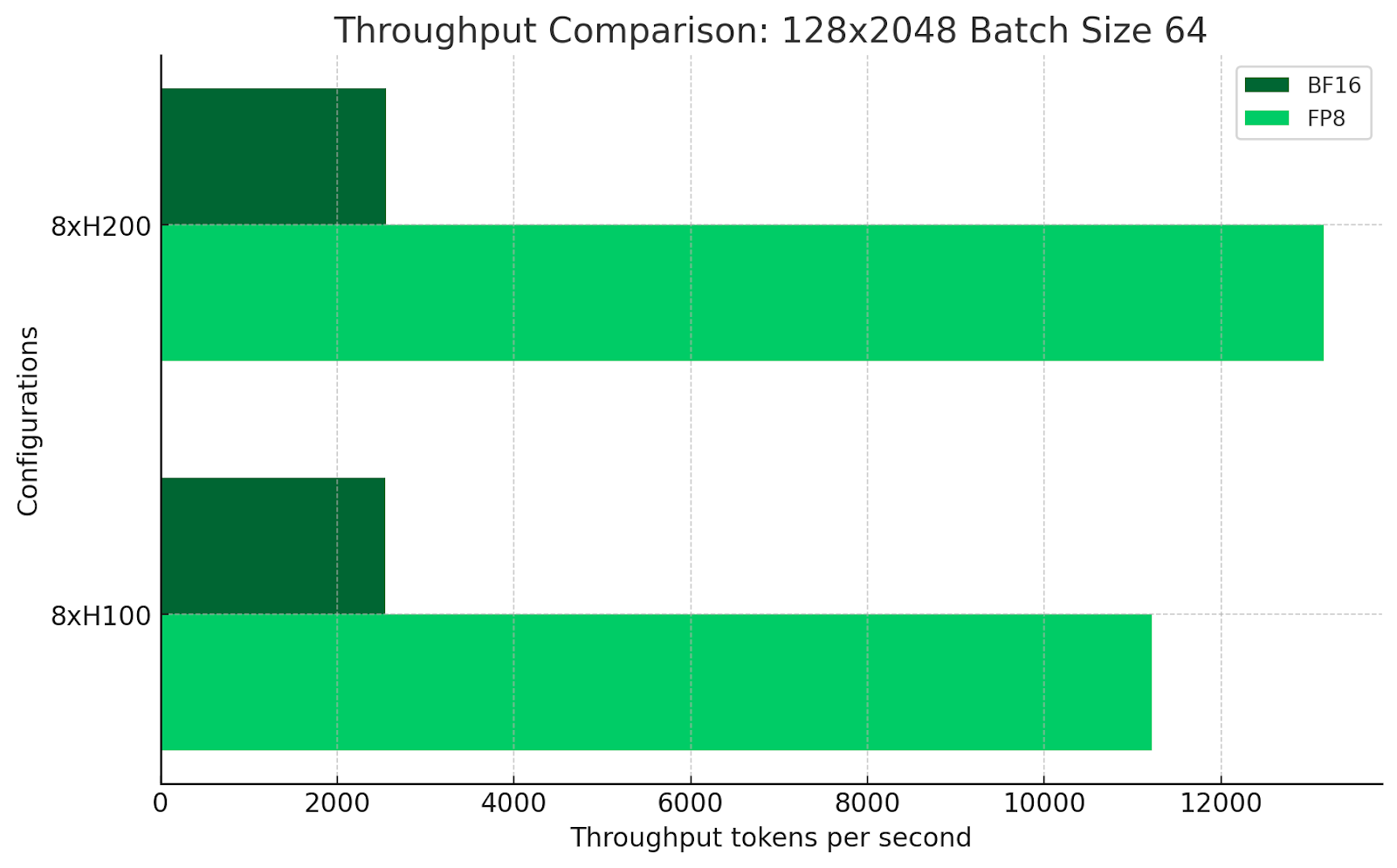
While the 8xH200 cluster offers approximately equal performance in BF16 and 11% higher performance in FP8 for this sequence length and batch size, the H200s do offer intriguing possibilities around greater KV cache reuse which is increasingly common for chat applications.
Conclusion: when to use H200 GPUs for inference
H200 GPUs are incredibly powerful and capable GPUs for a wide variety of AI/ML tasks, especially training and fine-tuning. For inference, H200 and H100 GPUs have their use cases. In conclusion, H200 GPUs are useful for:
- Large models: run LLMs with 100+ billion parameters in FP16 or FP8 precision.
- Large batch sizes: decrease cost per million tokens on batch processing jobs.
- Long input sequences: run inference performantly on long input sequences.
In some cases, it could make sense to split inference across both H100 and H200 GPUs, running the prefill step on less-expensive H100s then handing off token generation to H200s. Additionally, the GH200 GPU may offer strong inference performance in more circumstances – stay tuned for our upcoming benchmark results using a Lambda GH200 cluster.
If you’re interested in using H200 GPUs for long context or large batch LLM inference, let us know what you’re looking for and we’ll add you to our H200 waitlist. To access additional AI/ML inference and training solutions, create your own Lambda Cloud account and launch an instance with a few clicks.