
Available October 2022, the NVIDIA® GeForce RTX 4090 is the newest GPU for gamers, creators, students, and researchers. In this post, we benchmark RTX 4090 to assess its deep learning training performance. We also compare its performance against the NVIDIA GeForce RTX 3090 – the flagship consumer GPU of the previous Ampere generation.
NVIDIA RTX 4090 Highlights
- 24 GB memory, priced at $1599.
- RTX 4090's Training throughput and Training throughput/$ are significantly higher than RTX 3090 across the deep learning models we tested, including use cases in vision, language, speech, and recommendation system.
- RTX 4090's Training throughput/Watt is close to RTX 3090, despite its high 450W power consumption.
- Multi-GPU training scales decently in our 2x GPU tests.
Note: The GPUs were tested using the latest NVIDIA® PyTorch NGC containers (pytorch:22.09-py3). NVIDIA® used to support their Deep Learning examples inside their PyTorch NGC containers. However, this has no longer been the case since pytorch:21.08-py3. We made an effort to install and streamline the process of benchmarking Deep Learning examples inside of pytorch:22.09-py3. You can find more details about how to reproduce the benchmark in this repo.
PyTorch Training Throughput
The links that connect our Cloud to the Internet underwent a major overhaul, increasing our bandwidth to 10 Gbps—10x what our bandwidth used to be.
|
GPU/Model |
ResNet50 |
SSD |
Bert Base Finetune |
TransformerXL Large |
Tacotron2 |
NCF |
|
GeForce RTX 3090 TF32 |
144 |
513 |
85 |
12101 |
25350 |
14714953 |
|
GeForce RTX 3090 FP16 |
236 |
905 |
172 |
22863 |
25018 |
25118176 |
|
GeForce RTX 4090 TF32 |
224 |
721 |
137 |
22750 |
32910 |
17476573 |
|
GeForce RTX 4090 FP16 |
379 |
1301 |
297 |
40427 |
32661 |
32192491 |
Training Throughput Comparison

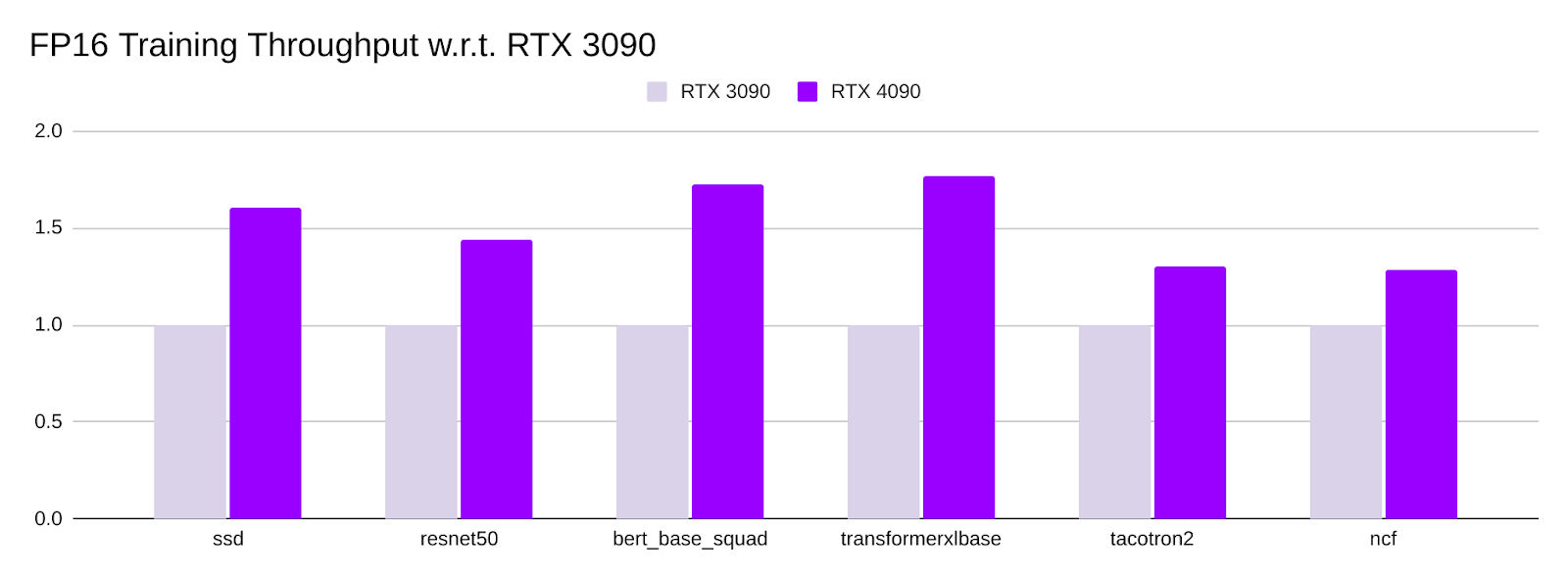
- All numbers are normalized using the training throughput of a single RTX 3090.
- RTX 4090 has significantly higher training throughput. Depending on the model, its TF32 training throughput is between 1.3x to 1.9x higher than RTX 3090.
- Similarly, RTX 4090's FP16 training throughput is between 1.3x to 1.8x higher than RTX 3090.
Training Throughput/$ Comparison

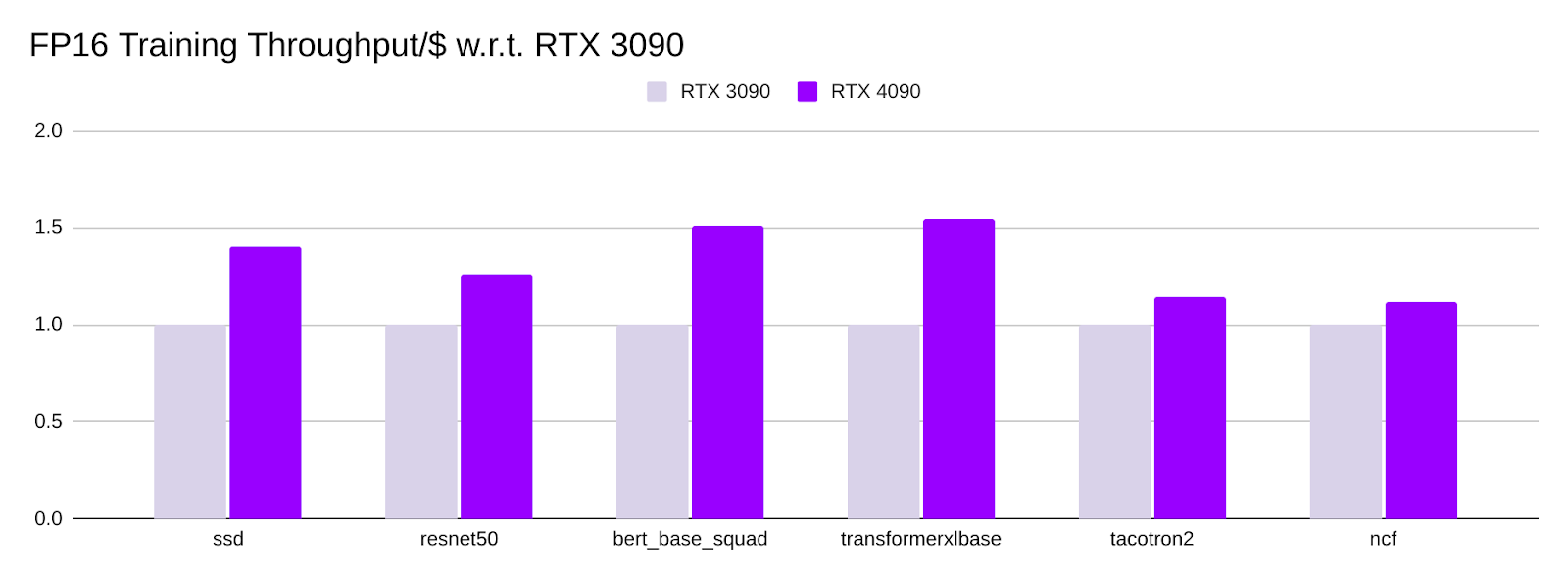
- All numbers are normalized using the training throughput/$ of a single RTX 3090.
- The reference prices for RTX 3090 and RTX 4090 are $1400 and $1599, respectively.
- RTX 4090 also has an outstanding training throughput/$ – ranging between 1.2x to 1.6x for different models and precisions over RTX 3090.
Training Throughput/Watt Comparison
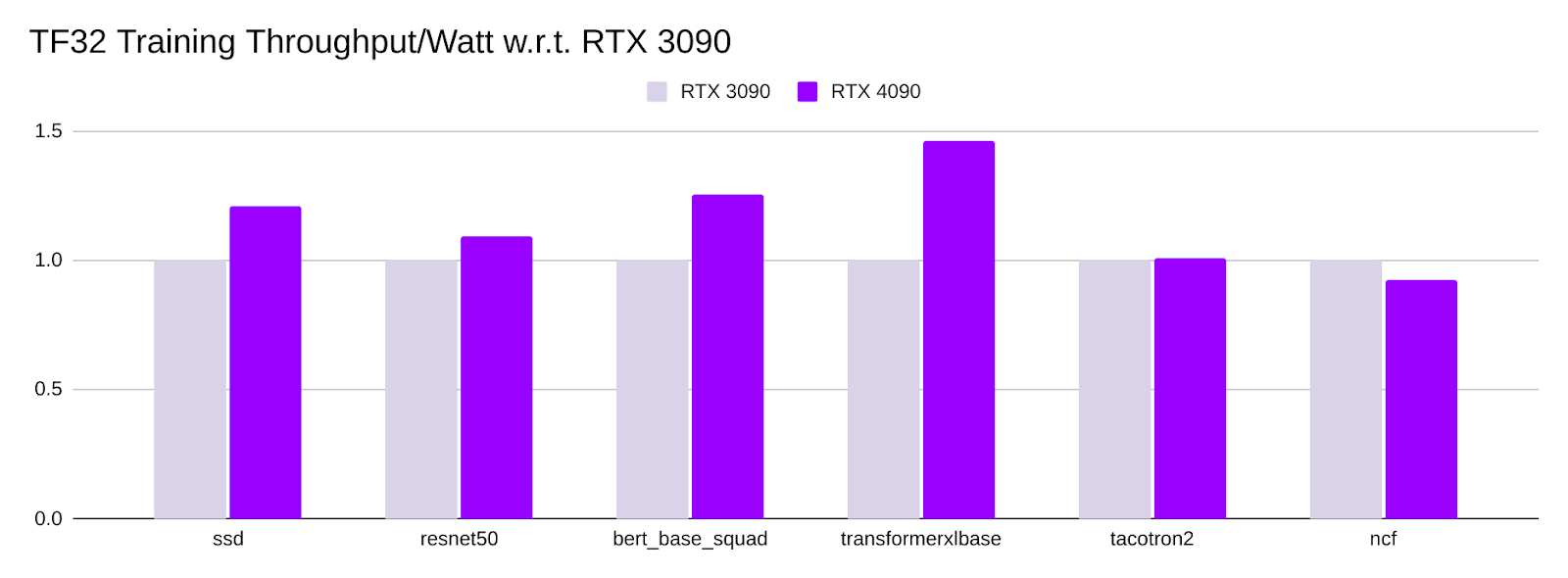
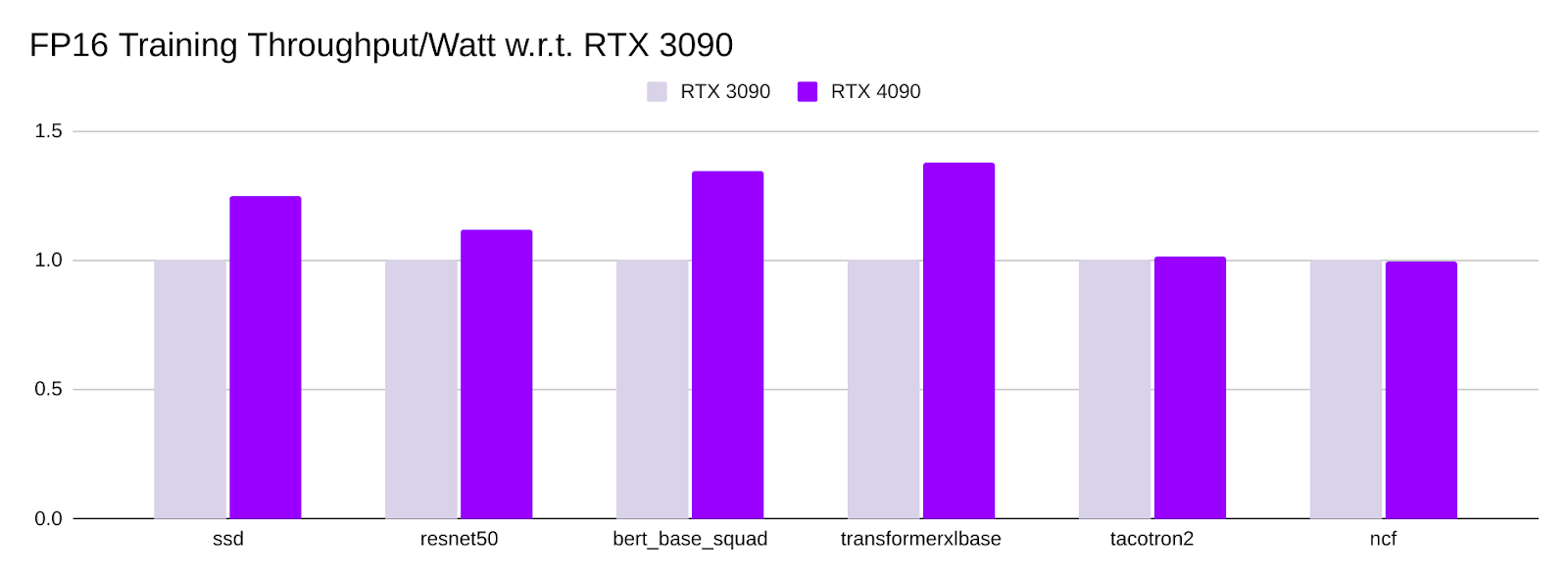
- All numbers are normalized using the training throughput/Watt of a single RTX 3090.
- The power consumptions for RTX 3090 and RTX 4090 are 350W and 450W, respectively.
- The training throughput/Watt of RTX 4090 is comparable to RTX 3090 ranges between 0.92x to 1.5x of RTX 3090.
Multi-GPU Scaling
Since NVLink is no longer supported on the Ada Lovelace GPU architecture, we would like to know how well multi-GPU training works for RTX 4090. We plugged 2x RTX 4090 onto a PCIe Gen 4 motherboard (see image below), and compared the training throughput of 2x RTX 4090 against a single RTX 4090.

2x RTX 4090 inside a Lambda Vector. Notice a single RTX 4090 will take 3.5 PCIe slots.
Our tests showed RTX 4090 scaled reasonably well for 2x GPU deep learning training:
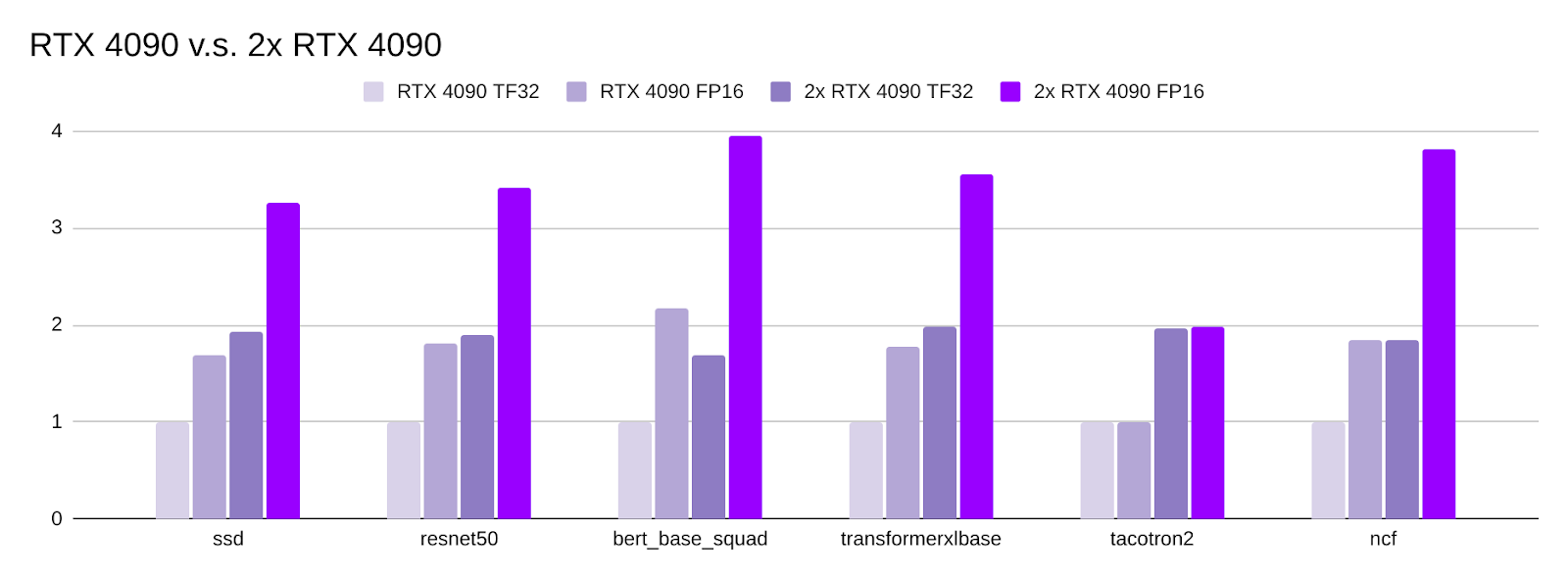
- Most of the models get close to 2x training throughput with two GPUs.
- However, we did observe some sub-optimal scaling. For example, 2xGPU only resulted ~1.7x throughput for fine turning the BERT_base model.
- As a side note, Tacotron2 FP16 isn't faster than TF32 across all tested GPUs. This is inline with the report from NVIDIA's Tacotron2 benchmark.
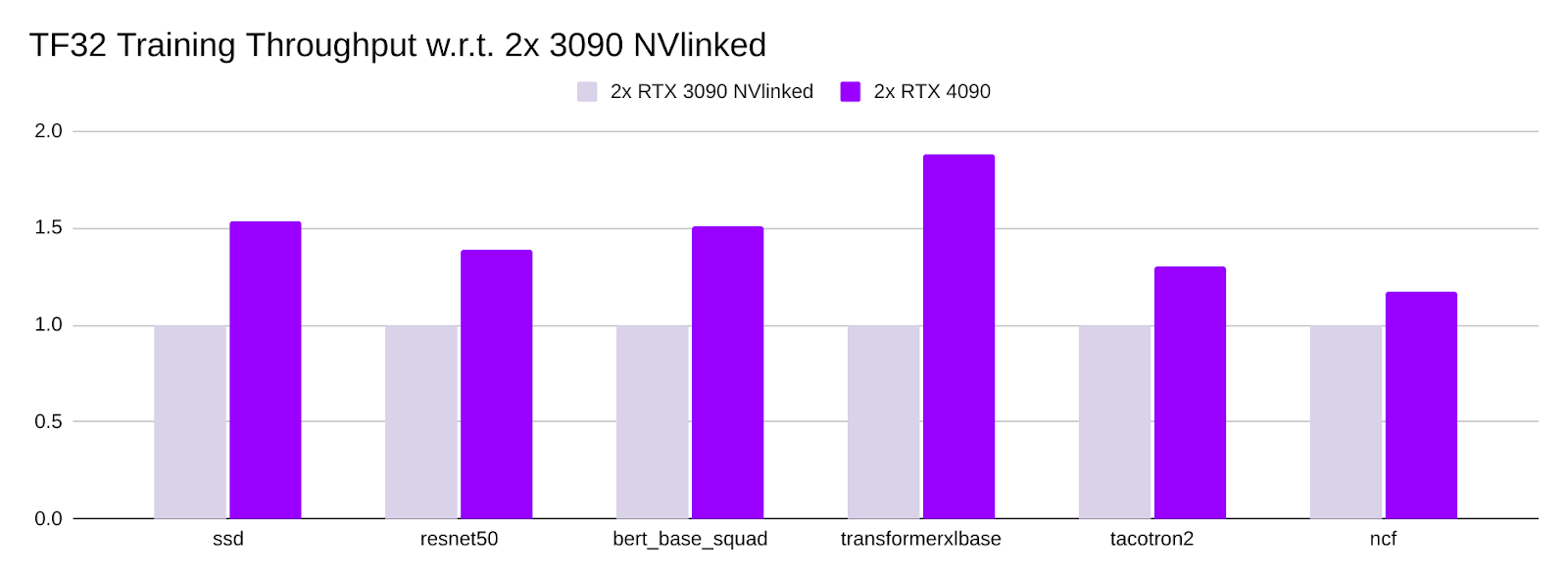
Last but not least, we compared 2x RTX 4090 with 2x RTX 3090 (with NVLink), and found 2x RTX 4090 consistently outperformed 2x RTX 3090:

Conclusion
In summary, the GeForce RTX 4090 is a great card for deep learning, particularly for budget-conscious creators, students, and researchers. It is not only significantly faster than the previous generation flagship consumer GPU, the GeForce RTX 3090, but also more cost-effective in terms of training throughput/$. For larger training workloads, NVIDIA RTX professional GPUs offer larger GPU memory for processing larger training datasets and models.
In the meantime, there are a couple of considerations for those who want to get an RTX 4090: first, it is not a small card. Its 61 mm (2.4 inches) width requires 3.5 PCIe slots. So make sure your motherboard and computer chassis have enough space to accommodate this beast. Second, its 450W high power consumption requires a beefy power supplier. In fact, NVIDIA® recommends a Minimum System Power of 850W for an RTX 4090 system.
We look forward to running more benchmarks for not only RTX 4090 but also other Ada Lovelace/Hopper GPUs. Especially with more comprehensive scaling tests for training with more GPUs across a wider range of deep learning models, as well as running inference benchmarks with the new FP8 datatype that is only available on the new generation Tensor Cores.
Footnotes
1. RTX 4090 features a PCI-Express 4.0 x16 host interface, even though its power architecture meets PCIe Gen 5 standards.