In order to improve the performance of a neural network, it is often necessary to try different hyper-parameters (such as learning rate, optimizer, batch size etc.) during the training. Hand-tuning hyper-parameters can be expensive since a training job may take many hours, if not days, to finish. This leads to the demand of doing systematic search.
This tutorial covers the basic of hyper-parameter tuning in the context of image classification. We use ResNet32 and CIFAR10, and showcase how to find the optimal optimizer and learning rate using the tuner function in our demo suite.
| Search Stage | # Trails | # Epochs | Learning Rate boundaries | Optimizer | Total Time |
|---|---|---|---|---|---|
| Coarse search | 20 | 2 | [-3.0,1.0] | momentum,adam,rmsprop | 10 mins |
| Fine search | 10 | 100 | [-3.0,-2.0] | adam | 200 mins |
You can jump to the code and the instructions from here.
Good practice
Below are some good practices for hyper-parameter search:
Sample the hyper-parameters in scale space. For example, the learning rate can be sampled with:
learning_rate = 10 ** random.uniform(-3.0, 1.0)The reason of using scale space is because hyper-parameters have multiplicative impact on training. For example, adding 0.01 might have a big impact when learning_rate = 0.01, but it has no impact when learning_rate = 1.0. So sampling in scale space is more efficient.
Use random search instead of Grid search. Randomly chosen trials are more efficient for hyper-parameter optimization than trials on a grid, as studied in this research. The reason is some hyper-parameters are insignificant – tuning these parameters will not impact the training behavior. Hence grid search is inefficient because it may freeze the important parameters and waste efforts on the insignificant ones. In contrast, random search does not freeze parameters so is able to explore the important parameters more effectively.
Search from coarse to fine. Since a single trail can take a long time to finish, it is useful to conduct the search using a coarse to fine strategy: use a few epochs to quickly filter out the bad parameters; then use more epochs to search around the promising parameters.
Bayesian optimization. This is a family of methods for efficient parameter search using trade-off between exploration and exploitation. In practice, there is still debate whether Bayesian optimization works better than random search, partially due to the fact that Bayesian optimization has tune-able parameters of its own.
Demo
You can download the demo from this repo.
git clone https://github.com/lambdal/lambda-deep-learning-demo.git
You'll need a machine with at least one, but preferably multiple GPUs and you'll also want to install Lambda Stack which installs GPU-enabled TensorFlow in one line.
https://lambdalabs.com/lambda-stack-deep-learning-software
Once you have TensorFlow with GPU support, simply run the commands in this guide to tune the optimal hyper-parameter for ResNet32 on CIFAR10.
Additional Notes
Configuration: In our demo we set up a random hyper-parameter search task with a simple yaml configuration file:
num_trials: 20
train_meta: "~/demo/data/cifar10/train.csv"
eval_meta: "~/demo/data/cifar10/eval.csv"
fixedparams:
epochs: 10
hyperparams:
generate:
learning_rate: "-3.0,1.0"
select:
optimizer: "momentum,adam,rmsprop"
This file first defines the number of trails (20). Each trail has a training phase and a evaluation phase. The train/eval data splits are set by the corresponding csv files. Next, the yaml file sets up some fixed-parameters and hyper-parameters:
- Fixed parameters
- epochs: Number of epochs for a trail. Use a small number (like 10) for corase search, use a large number (like 100) for fine search.
- Hyper parameters
- generate: The numerical hyper-parameters.
- learning_rate: The boundaries for searching learning rate in scale space. Each trail randomly samples a learning rate within the boundaries.
- select: The nonnumerical hyper-parameters.
- optimizer: Each trail randomly selects an optimizer from the list.
- generate: The numerical hyper-parameters.
The fixedparameters control the granularity of the search. In this case each trail uses 10 epochs for a quick coarse search. The hyperparameters are different for each trail.
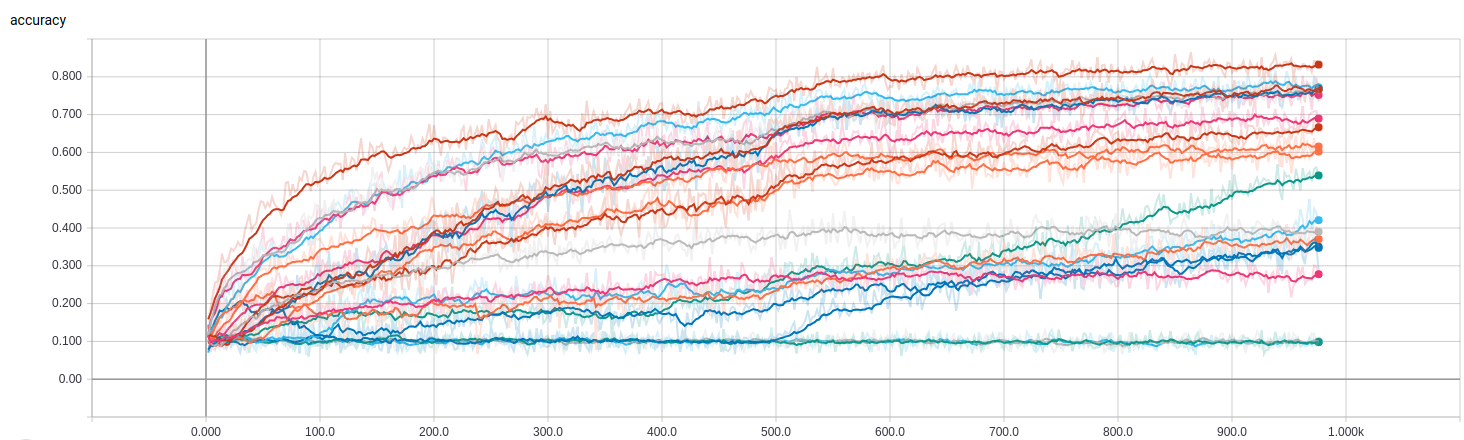
This is the Tensorboard visualization of the 20 trails produced from this yaml file:
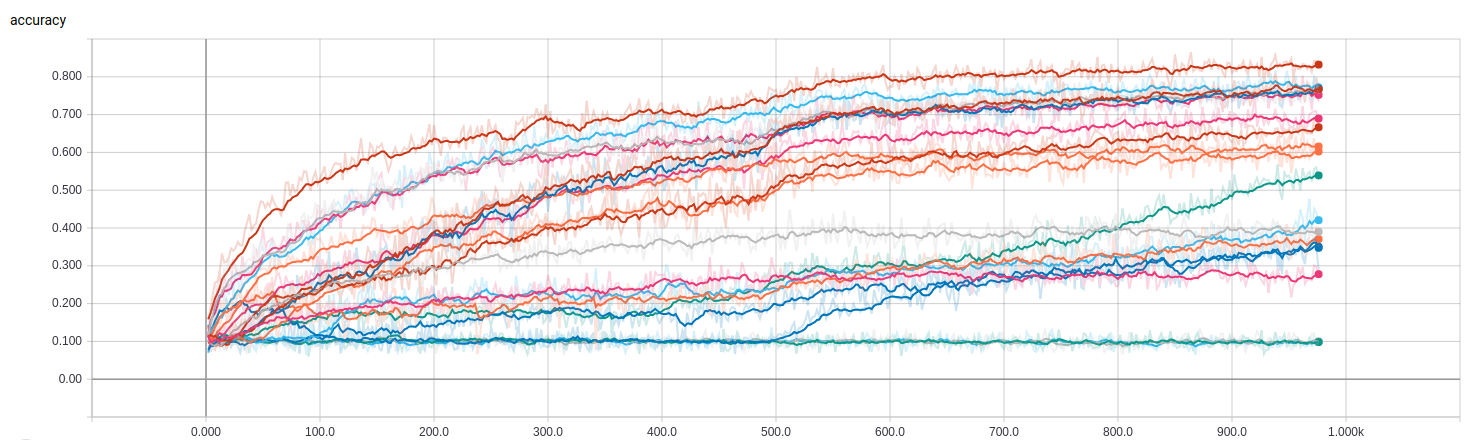
We can then select the best hyper-parameter setting from these trails (optimizer = adam and learning rate = 10^(-2.25)) for a fin-grained (epochs=100) local search:
num_trials: 10
train_meta: "~/demo/data/cifar10/train.csv"
eval_meta: "~/demo/data/cifar10/eval.csv"
fixedparams:
epochs: 100
hyperparams:
generate:
learning_rate: "-3.0,-2.0"
select:
optimizer: "adam"
The results can be something like this:
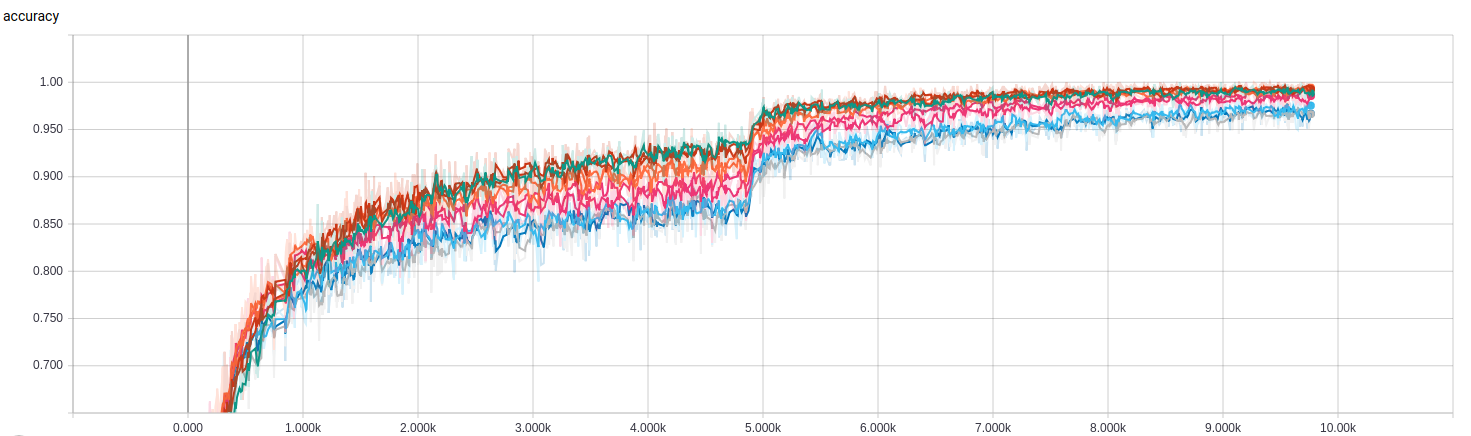
From which we can pick the best model for evaluation.