
Welcome to our Beginner's Demo! We will walk you through the steps of building an image classification application with TensorFlow. We will also introduce you to a few building blocks for creating your own deep learning demos.
The network architecture used in this demo is ResNet32, and the dataset is CIFAR10. The reference performance is:
- Training speed: 5,000 images/sec.
- Testing accuracy: 92% Top-1 accuracy in 100 epochs (~15 mins).
- Hardware: Lambda Quad i7-7820X CPU + 4x GeForce 1080 Ti
- OS: Ubuntu 18.04 LTS with Lambda Stack
You can jump to the code and the instructions from here.
Dataset
CIFAR10 is consists of 60,000 32 x 32 pixel color images. There are ten different classes: {airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck}. CIFAR10 is very popular among researchers because it is both small enough to offer a fast training turnaround time while challenging enough for conducting scientific studies and drawing meaningful conclusions.
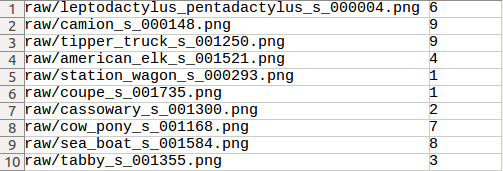
You can download CIFAR10 in different formats (for Python, Matlab or C) from its official website. However, as an example of managing data for machine learning applications, we re-organized the raw data with a CSV file. Below is a snippet of the CSV file: the first column is the path to the image, the second column is the class id:
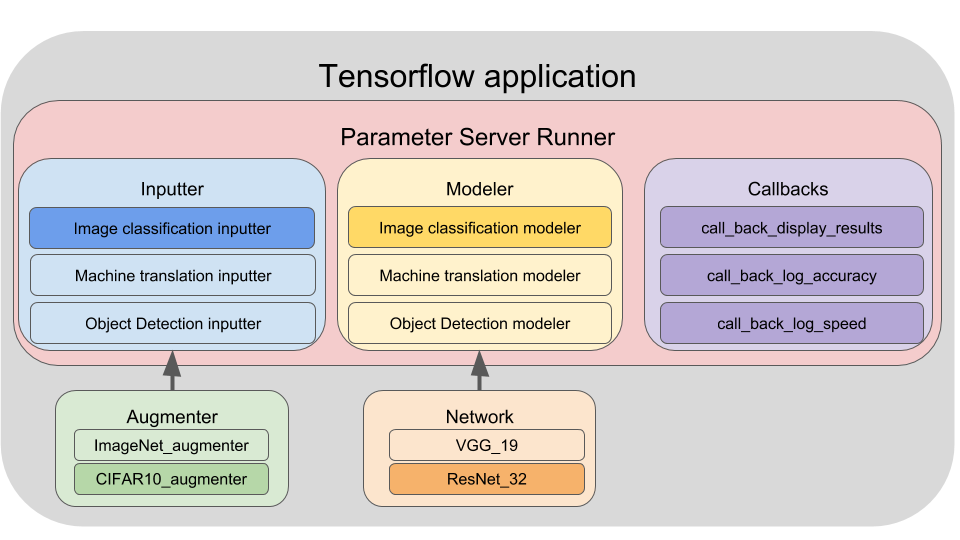
Application overview
Our TensorFlow demo is comprised of three main components:
-
Inputter: The data pipeline. It reads data from the disk, shuffles and preprocesses the data, creates batches, and does prefetching. An inputter is applicable to a specific problem. For example, we have image_classification_inputter, machine_translation_inputter, object_detection_inputter ... etc. An inputter can optionally own an augmenter for data augmentation.
-
Modeler: The model pipeline. The Modeler encapsulates the forward pass and the computation of loss, gradient, and accuracy. Like the inputter, a modeler is applicable to a specific problem such as image classification, object detection ... etc. A modeler must own a network member that implements the network architecture, for example, ResNet32, VGG19 or InceptionV4.
-
Runner: The executor. It owns an Inputter, a Modeler and a number of callbacks. A runner orchestrates the execution of an Inputter and a Modeler and distributes the workload across multiple hardware devices. It also uses callbacks to perform auxiliary tasks such as logging the statistics of the job and saving the trained model.
Below is an example of creating an training application for ResNet32 and CIFAR10 using the aforementioned components:
# (Optionally) Create a augmenter.
augmenter = importlib.import_module("source.augmenter.cifar_augmenter")
# Create a network object.
net = getattr(importlib.import_module("source.network.resnet32"), "net")
# Create callbacks
callback_names = ["source.callback.train_basic",
"source.callback.train_loss",
"source.callback.train_accuracy",
"source.callback.train_speed",
"source.callback.train_summary"]
for name in callback_names:
callback = importlib.import_module(name).build(args)
callbacks.append(callback)
# Create a Inputter.
inputter_name = "source.inputter.image_classification_csv_inputter"
inputter = importlib.import_module(inputter_name).build(args,
augmenter)
# Create a Modeler
modeler_name = "source.modeler.image_classification_modeler"
modeler = importlib.import_module(modeler_name).build(args,
net)
# Create a Runner
runner_name = "source.runner.parameter_server_runner"
runner = importlib.import_module(runner_name).build(args,
inputter,
modeler,
callbacks)
# Run application
demo = app.APP(args, runner)
demo.run()
Demo
You can download the demo from this repo.
git clone https://github.com/lambdal/lambda-deep-learning-demo.git
You'll need a machine with at least one, but preferably multiple GPUs and you'll also want to install Lambda Stack which installs GPU-enabled TensorFlow in one line.
https://lambdalabs.com/lambda-stack-deep-learning-software
Once you have TensorFlow with GPU support, simply run the commands in this guide to reproduce the results.
Additional Notes:
Below, we'll dive into the implementation details of each module:
Inputter: The first important component of our TensorFlow application is the Inputter. It encapsulates the entire data pipeline into the input_fn member function:
def input_fn(self):
batch_size = (self.args.batch_size_per_gpu * self.args.num_gpu)
# Fetching meta data from the CSV file (images path and class labels).
samples = self.get_samples_fn()
# Create a TensorFlow dataset object.
dataset = tf.data.Dataset.from_tensor_slices(samples)
# Shuffle the data for training.
if self.args.mode == "train":
dataset = dataset.shuffle(self.args.shuffle_buffer_size)
# Repeat the dataset for multi-epoch training.
dataset = dataset.repeat(self.args.epochs)
# Parse each sample (read images from path, preprocess and augmentation).
dataset = dataset.map(
lambda image, label: self.parse_fn(image, label),
num_parallel_calls=4)
# Batch the data.
dataset = dataset.apply(
tf.contrib.data.batch_and_drop_remainder(batch_size))
# Pre-fetch for efficiency
dataset = dataset.prefetch(2)
# Return data generator
iterator = dataset.make_one_shot_iterator()
return iterator.get_next()
Augmenter: An inputter can optionally have an augmenter. In this example, we use one to inflate the amount of training data by random image resizing and cropping.
resized_image = tf.image.resize_image_with_crop_or_pad(image,
output_width,
output_height)
The output of the input_fn will be fed to the modeler, which we will explain next.
Modeler: The second key component of our TensorFlow application is the Modeler. It consumes the input data and encapsulates the entire model computation into the model_fn method:
def model_fn(self, x):
# x is the output generator from input_fn.
images = x[0]
labels = x[1]
# Create the feed-forward computation.
logits, predictions = self.create_graph_fn(images)
if self.args.mode == "train":
# Additonal training related computations.
loss = self.create_loss_fn(logits, labels)
grads = self.create_grad_fn(loss)
accuracy = self.create_eval_metrics_fn(predictions, labels)
return {"loss": loss,
"grads": grads,
"accuracy": accuracy,
"learning_rate": self.learning_rate}
elif self.args.mode == "eval":
# Additonal evaluation related computations.
loss = self.create_loss_fn(logits, labels)
accuracy = self.create_eval_metrics_fn(predictions, labels)
return {"loss": loss, "accuracy": accuracy}
elif self.args.mode == "infer":
# Directly returns feed-forward result for inference.
return {"classes": predictions["classes"],
"probabilities": predictions["probabilities"]}
The output of the model_fn is a dictionary of TensorFlow operators. The composition of this dictionary depends on the mode of the model. The models are {train, eval, infer}. The Runner is responsible for calling these operators.
Network: A Modeler must own a network, which implements the feed-forward computation. In this example, we directly call TensorFlow slim's ResNet implementation:
from source.network.external.tf_slim import resnet_v2
# Feed-forward pass.
logits, _ = resnet_v2.resnet_v2_32(inputs,
num_classes,
is_training=is_training)
Runner: The last piece of our TensorFlow application is a Runner. A Runner owns an Inputter, a Modeler, and a bunch of callbacks. It orchestrates the execution of the Inputter and the Modeler, distributes the workload across multiple hardware devices, and uses callbacks to perform auxiliary tasks such as logging execution, saving the model and displaying the results. The main logic lives inside of Runner's run method:
def run(self):
# Combine the computational graphs of the inputter and the modeler.
# Also distribute the workload across multiple devices.
self.create_graph()
# Create a Tensorflow session.
with tf.Session(config=self.session_config) as self.sess:
# Do auxiliary tasks before the run.
self.before_run()
# Get the current step and the maximum step.
global_step = 0
if self.args.mode == "train":
global_step = self.sess.run(self.global_step_op)
max_step = self.sess.run(self.max_step_op)
# Run the application till reaching the maximum step.
while global_step < max_step:
# Do auxiliary tasks before each step.
self.before_step()
# Run the step.
self.outputs = self.sess.run(self.run_ops,
feed_dict=self.feed_dict)
# Do auxiliary tasks after each step.
self.after_step()
# Increase the current step by one.
global_step = global_step + 1
# Do auxiliary tasks after the job has finished.
self.after_run()
We can, for example, use a parameter server Runner to utilize multiple GPUs. A parameter server distributes data and computation across multiple GPU devices, and averages the results on a parameter server device (a CPU in the example below):
def replicate_graph(self):
# Get the data generator from input_fn.
batch = self.inputter.input_fn()
output = {}
for i in range(self.args.num_gpu):
with tf.device(self.assign_to_device("/gpu:{}".format(i),
ps_device="/cpu:0")):
# Split input data across multiple devices
x = self.batch_split(batch, i)
# Run graph on a single device.
y = self.modeler.model_fn(x)
# Gather the output.
if i == 0:
for key in y:
output[key] = [y[key]]
else:
for key in y:
output[key].append(y[key])
# Averaging the output from multiple devices.
reduced_ops = {}
for key in output:
reduced_ops[key] = self.reduce_op(output[key])
return reduced_ops
Callback: A Runner uses callbacks to perform auxiliary tasks. Each callback needs to implement a few functions for different stages of the execution. For example, checkout this callback for logging the training speed.