I'm not a human. Or at least that's what Google thought when I failed to fill out the reCAPTCHA properly for the third time. What exactly qualifies as a storefront anyways? As my third round failed I noticed some noise that vaguely resembled the Deep Dreams that I spent so many sleepless nights staring at when developing Dreamscope.


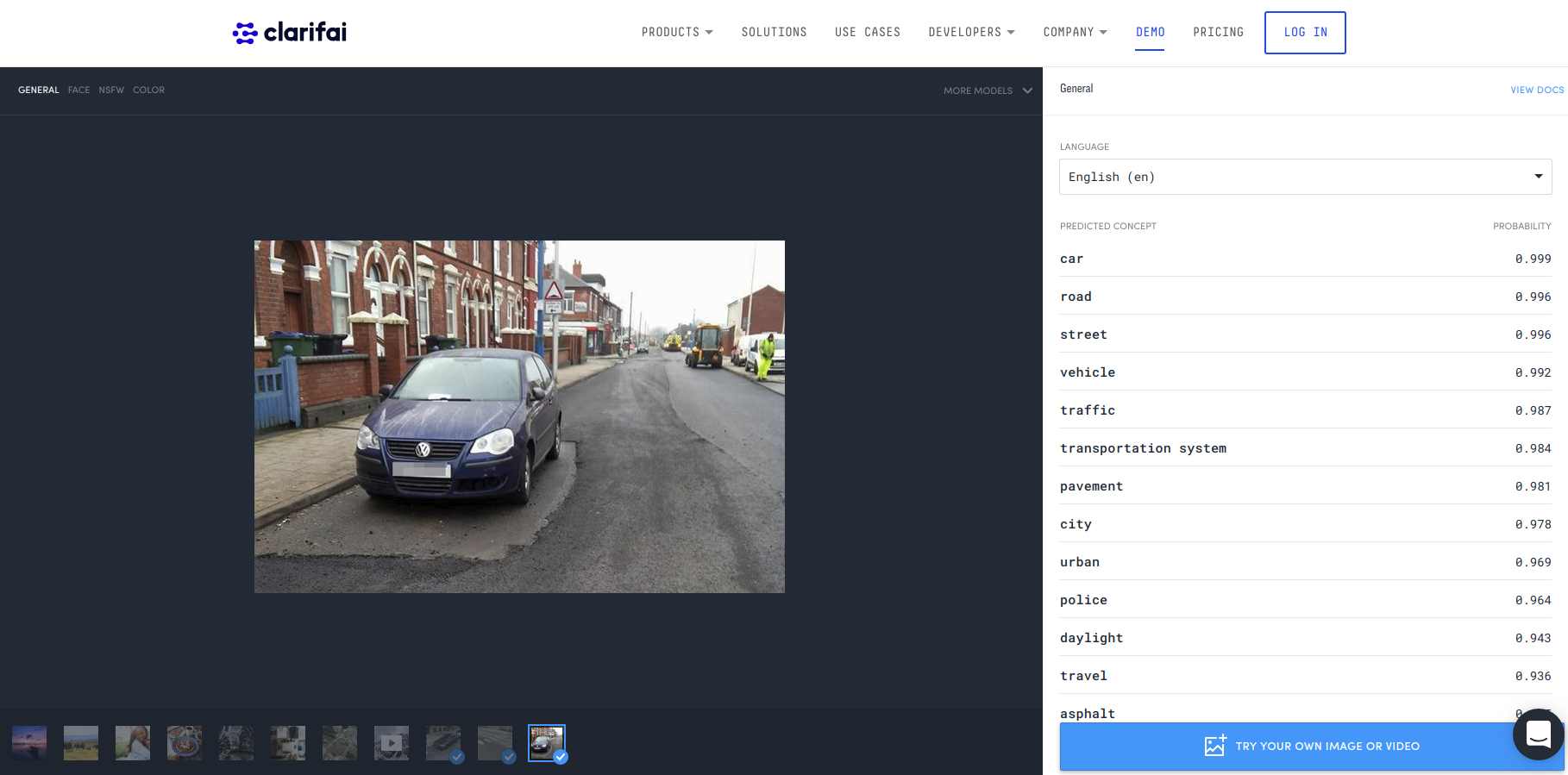
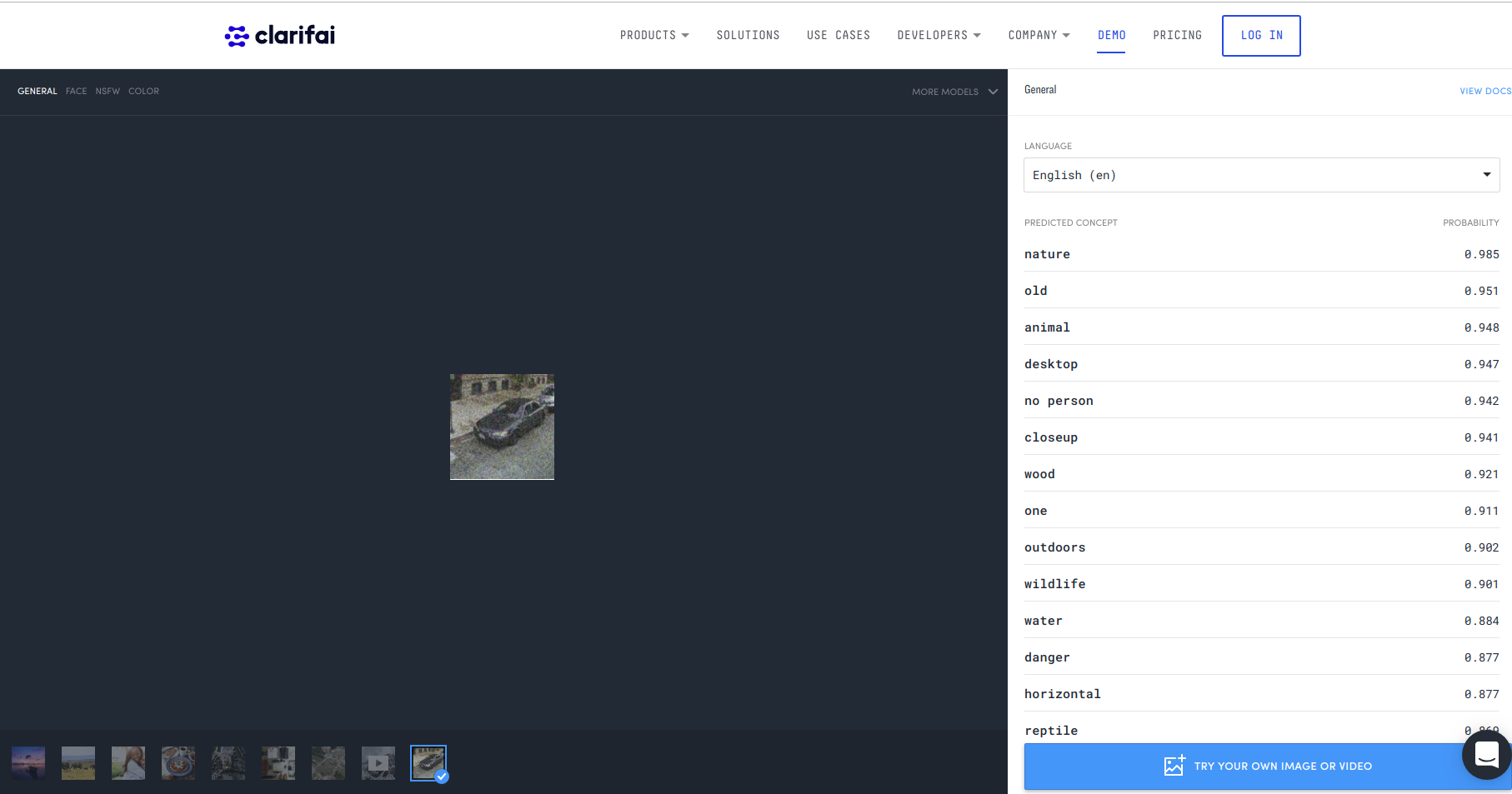
ReCAPTCHA with adversarial noise. The central car is recognized as "nature" by ClarifAI's online demo.
To feel more comfortable with this conclusion, we'd need to conduct an actual study with a few hundred examples taken from google's database and see if there's simultaneously a significant drop a network's ability to recognize the images as well as a corresponding increase in its confidence in the wrong answer. That would be the signature of an adversarial example. Initial tests with ClarifAI suggest that it could be adversarial. It's very confident that the car is "nature" or "old" whereas the clean example it's very very confident that it's a car.
Research Design
Hypothesis: The "mystery noise" in these images will elicit a highly confident but incorrect answer from common neural networks trained on ImageNet whereas the gaussian RGB noise will only result in a slight degradation in accuracy but also a decrease in confidence.
What is meant by "confidence" here is when the final softmax layer allocates most of the probability mass to only a few of the classes, i.e. it has a non-uniform distribution.
Experiment Design
- Gather 100 clean images from reCAPTCHA.
- Gather 100 "mystery noise" images from reCAPTCHA.
- Add Gaussian RGB noise to clean images from step 1.
- Train a ResNet-50, ResNet-152, and AlexNet on ImageNet.
- Use these three networks to classify the 300 images in the {clean, mystery-noise, gaussian-noise-control} sets.
- If you observe that the hypothesis is true, I would be comfortable concluding that the noise is adversarial.
Results Soon?
Maybe I'll conduct this study at some point in time or maybe you will. If you do, please tweet @LambdaAPI or @stephenbalaban and I'll share your results here.
As they said in the original CAPTCHA paper:
This approach, if it achieves widespread adoption, has the beneficial side effect of inducing security researchers, as well as otherwise malicious programmers, to advance the field of AI (much like computational number theory has been advanced since the advent of modern cryptography).[ 1]
CAPTCHA was broken, we had an advance in AI. Now that it's probably been un-broken, can we say that we've had another advance? I think so.
Now let's get to breaking adversarial examples!
Citations