
With most (if not all) machine learning and deep learning researchers and engineers now working from home due to COVID-19, we’ve seen a massive increase in the number of users needing access to large amounts of affordable GPU compute power.
Today, we’re releasing a new 8 NVIDIA® Tensor Core V100 GPU instance type for Lambda Cloud users. Priced at $4.40 / hr, our new instance provides over 2x more compute per dollar than comparable on-demand 8 GPU instances from other cloud providers.
What’s inside our new 8 GPU instance?
We’ve built the cloud instances with the hardware you need to get started training even some of the largest data sets:
- GPUs: 8x (16 GB) NVIDIA Tensor Core V100 SXM2 GPUs (with NVLink™)
- CPU: 92 vCPUs
- System RAM: 448 GB
- Temporary Local Storage: 6 TB NVMe
- Network Interface: 10 Gbps (peak)
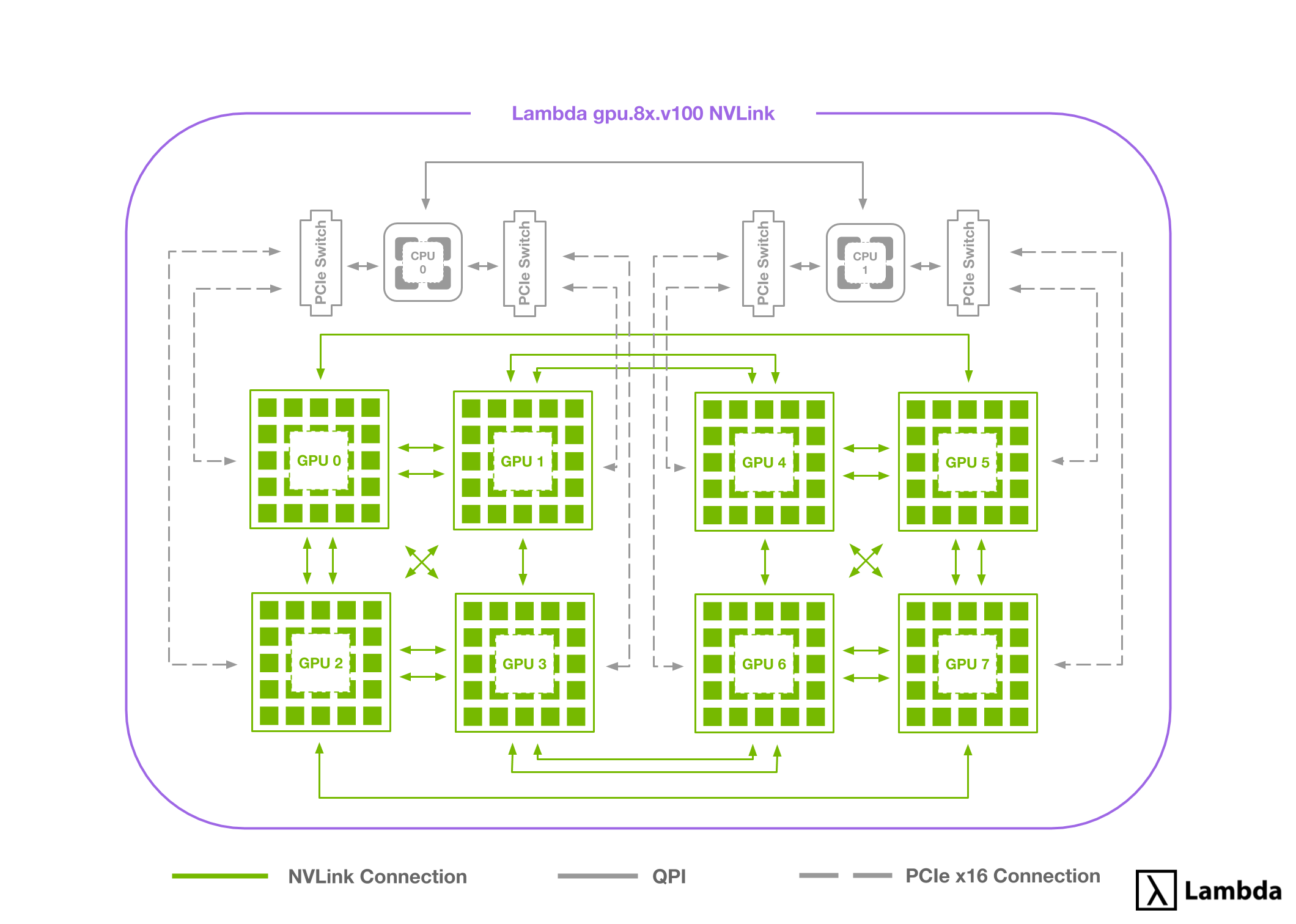
A brief primer on NVLink™
We get a lot of questions about the capabilities of NVLink from customers, so let me take a brief moment to explain the misconception and show how NVLink works on our new instance type.
The biggest misconception is that NVLink turns all of your GPUs into one “super GPU.” While NVLink does improve the interconnect speeds between GPUs over PCIe 3.0 (supporting up to 300 GB/s), they do not suddenly appear as one GPU to your system. You’ll still need to run your training workloads in a distributed fashion, but they’ll be much quicker at consolidating results among the GPUs.
If you’re curious as to how they do communicate, the NVLink connections form three concentric rings with which they can communicate this allows each GPU to communicate with its two closest neighbors over 100 GB/s of NVLink each, it’s next two closest with 50 GB/s each, and its four most distant neighbors over over ~15 GB/s PCIe Gen 3.0.
While it might seem unideal, this schema is actually well-suited for ring-style algorithms used by many multi-GPU training tasks.
Calculating the cost of compute
We could tell you that our cloud instance costs 51% less than the comparable on-demand 8 GPU instance from many major cloud providers. However, we’re pretty sure you wouldn’t be satisfied with that answer and neither were we. So, we set out to make sure this was an apples to apples comparison.
To do this we ran a full suite of benchmarks testing image models, language models, machine translation, speech synthesis, and recommendation systems. The models were run using full precision (FP32), half precision (FP16), and, when applicable, automatic mixed precision (AMP).
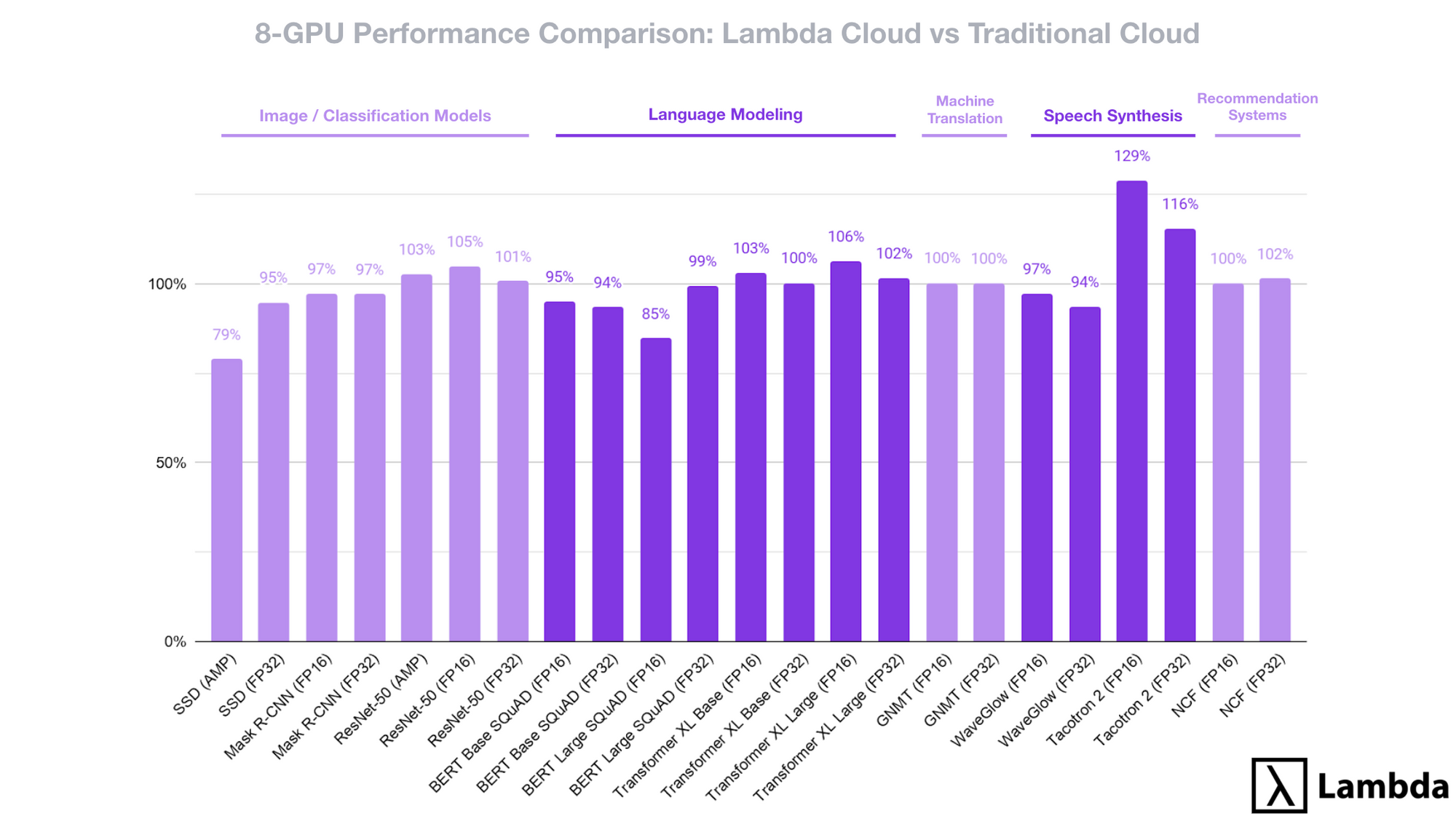
2x better than comparable on-demand
While there was some variance among the individual model performance, when averaged across all use cases the Lambda Cloud 8-GPU V100 instance provides 99.9% the performance of the comparable 8 GPU instance from a traditional cloud provider.[1]
When we combine this with the Lambda Cloud on-demand price of $4.40 per hr (vs $24.48 per hr) the 8-GPU system provides just over 2x the compute power per dollar with an included 6 TB of temporary local NVMe storage.
Additionally, we do not require any extended 1 or 3 year contract for you to see these savings, and we’re still 30% less expensive than equivalent 1 year contract pricing.
Not a spot instance
A common method to provide discounts by many cloud providers (not just the major ones) is to provide access to “spot” or ephemeral instances that can be shut off by the cloud provider at a moment's notice.
This is not how we provide discounts. When you spin up an instance it’s yours until you terminate it. No need to modify your code to deal with unexpected disruptions.
All the tools to get started
All of our instances come pre-installed with the latest versions of CUDA, Jupyter, Pytorch, Tensorflow, and Keras as well as more frameworks, tools, and languages you can find in our FAQ.
To get started with Lambda Cloud you can sign up here or, if you’re already a customer, sign in and launch a new 8-GPU instance at $4.40 / hr from the dashboard.
1. All models are benchmarked with the max batch size under the assumption that the throughput will increase linearly with the batch size. However in practice we found sometimes smaller batch size actually gives higher throughput. For example, reduce batch size = from 88 images / GPU to 32 images / GPU, the training throughput for SSD_AMP increased from 1330 images / sec to 1600 images / sec, which matches our standard bare metal hardware reference.