Private Large-Scale GPU Clusters
One, two, or three-year contracts for 64-10k+ GPUs and 3.2Tb/s networking
Get the most coveted and highest performing NVIDIA GPUs
Lambda Private Cloud leverages only the latest and greatest infrastructure, built for the next generation of LLMs and other large-scale models.
NVIDIA H100 SXM

NVIDIA H200 SXM

NVIDIA GH200 SXM

Finally, cloud computing designed for large scale model training and inference
Thousands of the most powerful GPUs
Train large-scale models across thousands of NVIDIA H100s, NVIDIA H200s, or NVIDIA GH200s, with no delays or bottlenecks. Access the latest infrastructure, built for your most demanding AI projects.
Absolute fastest GPU compute fabric
Each GPU is paired 1:1 with a dedicated 400 Gbps link to the Lambda Private Cloud compute fabric. The optimal networking topology for GPU computing scaling to multi-Petabit per second throughput.
Non-blocking InfiniBand networking
The absolute fastest network available delivering full bandwidth to all GPUs in the cluster simultaneously. Leveraging NVIDIA Quantum-2 InfiniBand with support for GPUDirect RDMA and optimized for massive scale full-cluster distributed training.
The fastest network for distributed training of LLMs, foundation models & generative AI
This design is purpose built for NVIDIA GPUDirect RDMA with maximum inter-node bandwidth and minimum latency across the entire cluster.
The Lambda compute network uses a non-blocking multi-layer topology with zero oversubscription. This provides full networking bandwidth to every NVIDIA GPU in the cluster simultaneously, the optimal design for full-cluster distributed training.
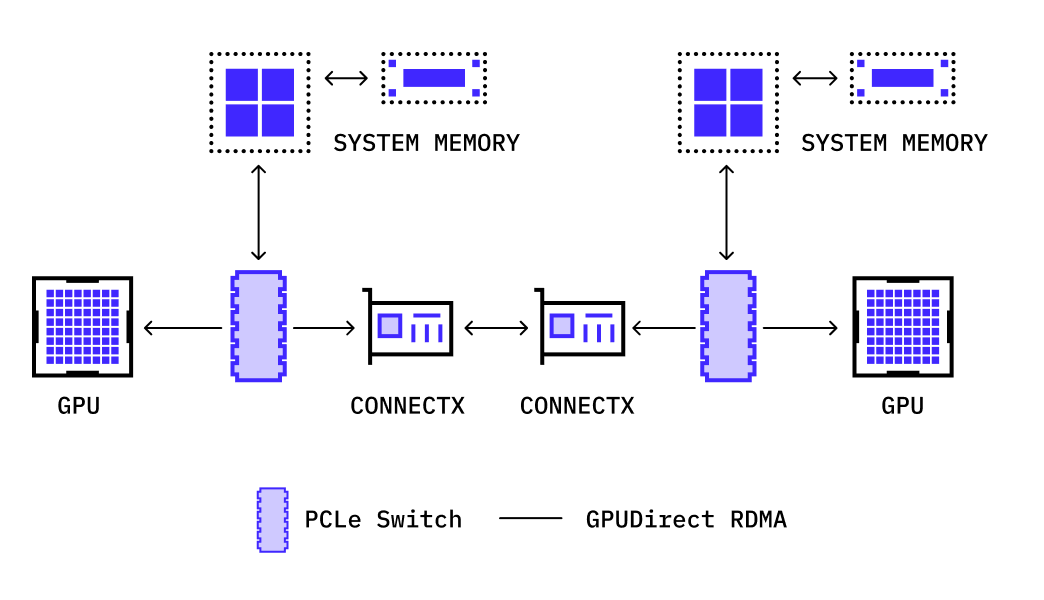
Skip the CPU and take advantage of GPUDirect RDMA for the fastest distributed training
A direct communication path between NVIDIA GPUs across all nodes in your cluster using NVIDIA Quantum-2 InfiniBand.
GPUDirect RDMA provides a significant decrease in GPU-GPU communication latency and completely offloads the CPU, removing it from all GPU-GPU communications across the network.
Pre-configured for machine learning
Start training your models immediately with pre-configured software, shared storage, and networking for deep learning. All you have to do is choose your NVIDIA GPU nodes and CPU nodes.
Lambda Premium Support for Lambda Private Cloud includes PyTorch, TensorFlow, NVIDIA CUDA, NVIDIA cudNN, Keras and Jupyter. Kubernetes is not included.