
by Lambda and Scale
Visualizing your training data is the foundation of every successful deep learning project. It’s important to both identify potential flaws in the ground truth labels, and to look for insights that will guide your choice of model architecture. Deeply understanding your data can help ensure that time spent training your model is optimally spent.
Nucleus is a tool from Scale that allows you to do just that. It provides an intuitive web interface to visualize and explore a wealth of different types of training data and labels. It also gives you the tools to explore and understand the relationship between your data and the model predictions that you generate.
In this post, we'll show you how you can get started with Nucleus, use it to visualize an object detection dataset, and compare your ground truth to the predictions from a trained neural network. This loop of inspecting your training data and looking for failure modes in a network's predictions is a crucial process in refining both your training dataset and your neural network.
Getting Started
The example in this post was run on a Lambda Vector workstation running Lambda Stack, if you want to follow along see the example notebook here.
As a first step we're going to grab the publicly available Penn-Fudan Dataset of pedestrian data. To load this into Nucleus we need to do two things: First get a free Scale account and corresponding API key and then install the nucleus client on our Lambda workstation:
pip install scale-nucleus
Training data
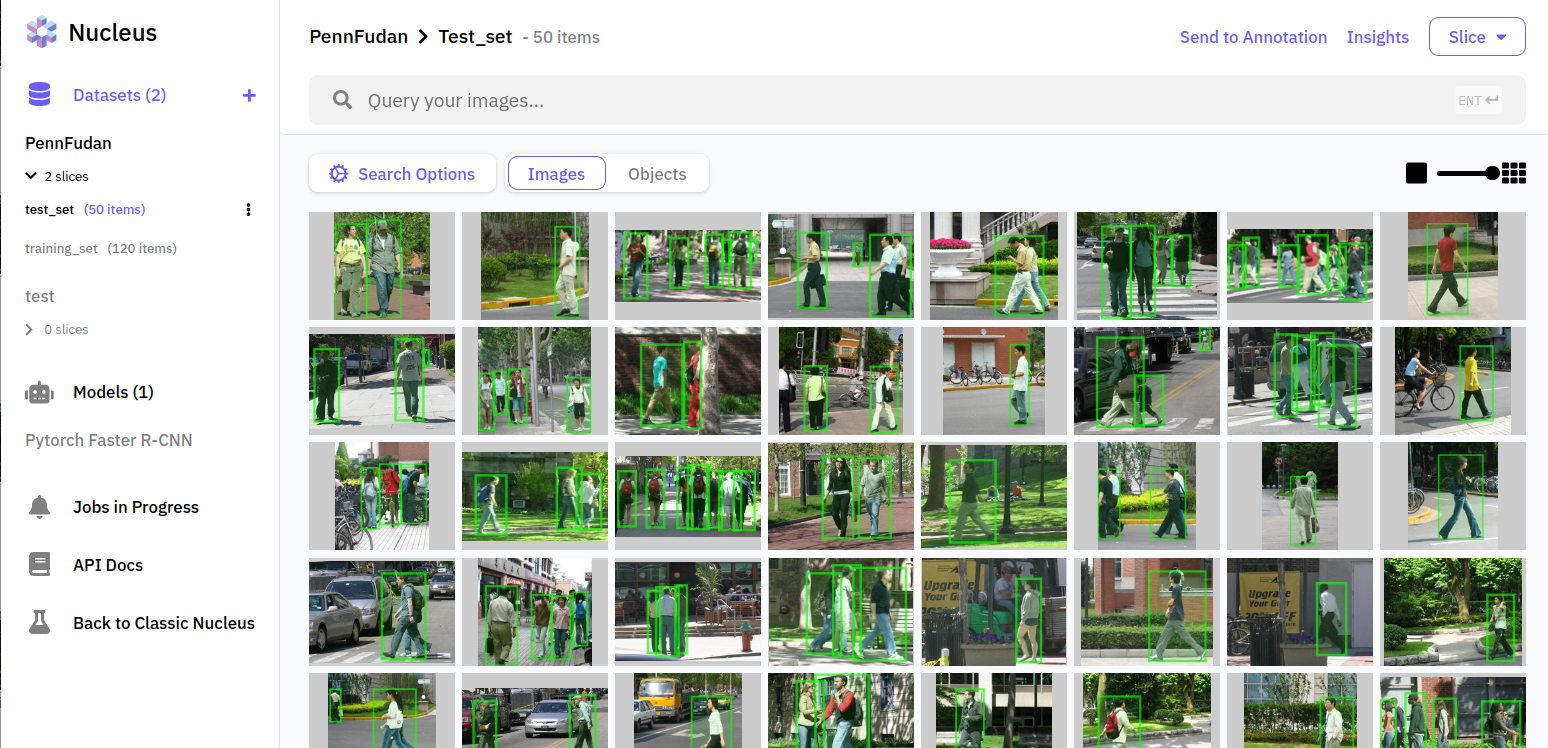
Once we've installed the Nucleus client and downloaded the dataset, we can upload the images and ground truth labels to a new Dataset we created in Nucleus. (For the full details of how to do this, see this section of the notebook.) Now that we’ve uploaded the data, we can visualize the ground truth labels in the Nucleus web dashboard without writing any code.
Model predictions
Now that we've "become one with our data," we can start thinking about training a neural network for object detection. For this little example we fine tuned a Faster R-CNN model pre-trained on the COCO dataset. Training it for 10 epochs only takes a few minutes on a NVIDIA RTX A6000 in a Lambda Vector Workstation.
After training is finished we can see that our model has reached an Average Precision (AP@IoU=0.50:0.95) of 0.83. This sounds OK, it's not too far from 1, but what does it mean? Do we have a good pedestrian detector yet? The AP metric of object detection is notoriously hard to get your head around, and there are endless blog posts that aim to provide an intuition for it, but you’ll ultimately need to look at our results to see how we're doing.
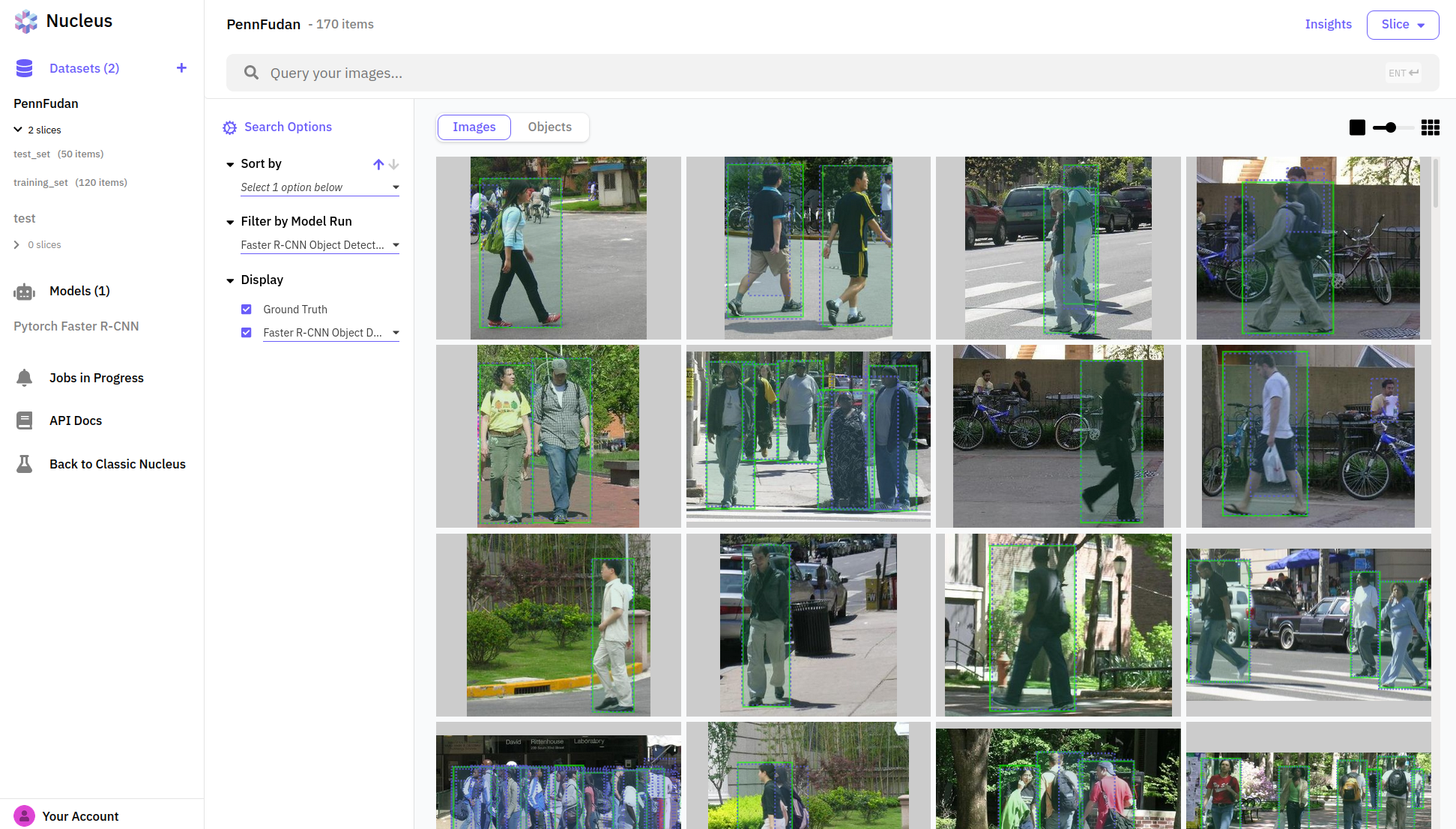
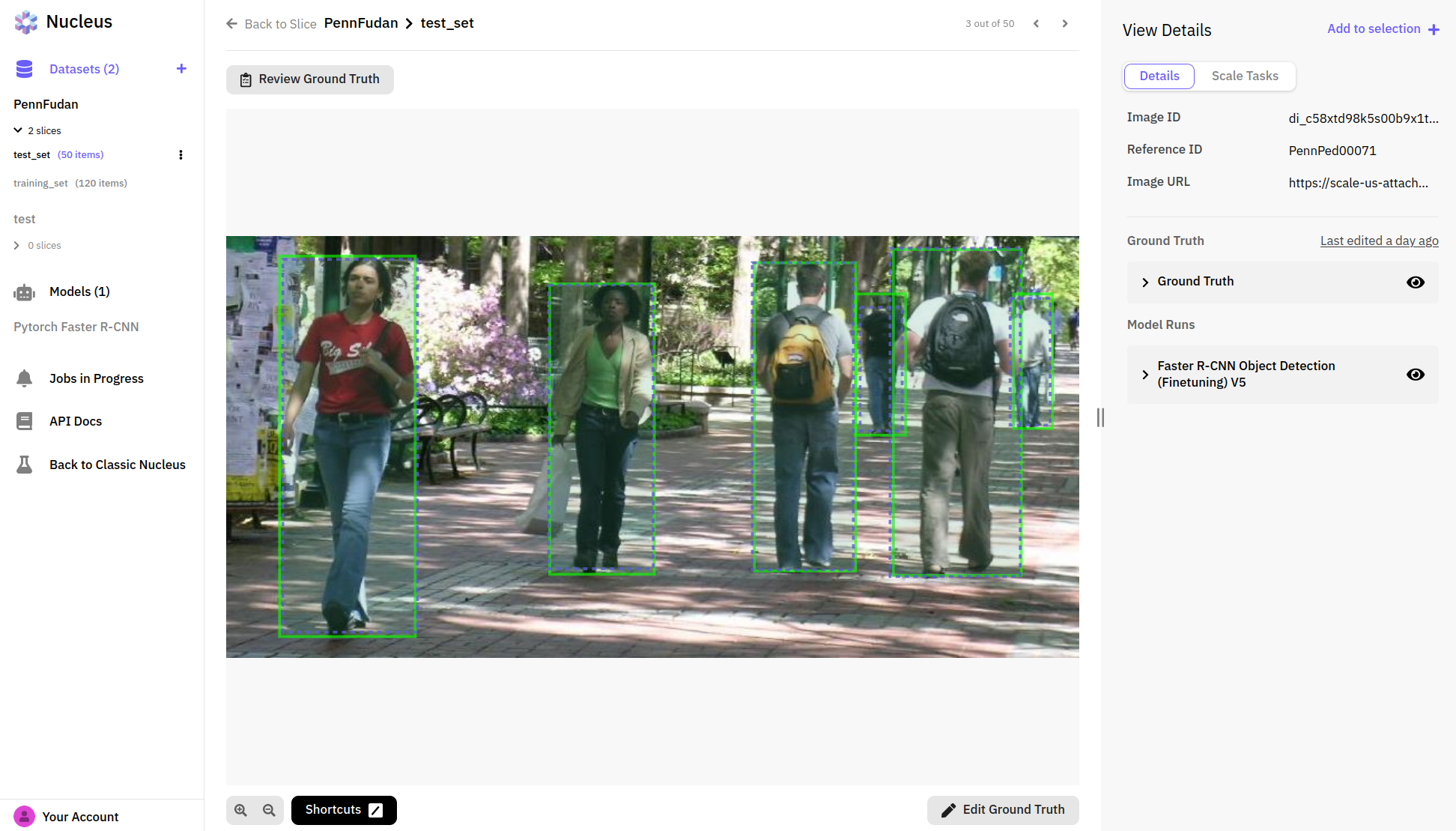
Nucleus allows us to upload our model predictions and compare them to the ground truth. Here we can see that blue boxes predicted by our model match pretty well with the green ground truths from the dataset:
What to try next?
Nucleus also gives some nice tools to help us figure out what else we should try to improve our accuracy results. First we filter our results by false positives/negatives to get a feel for where our model is going off the rails.
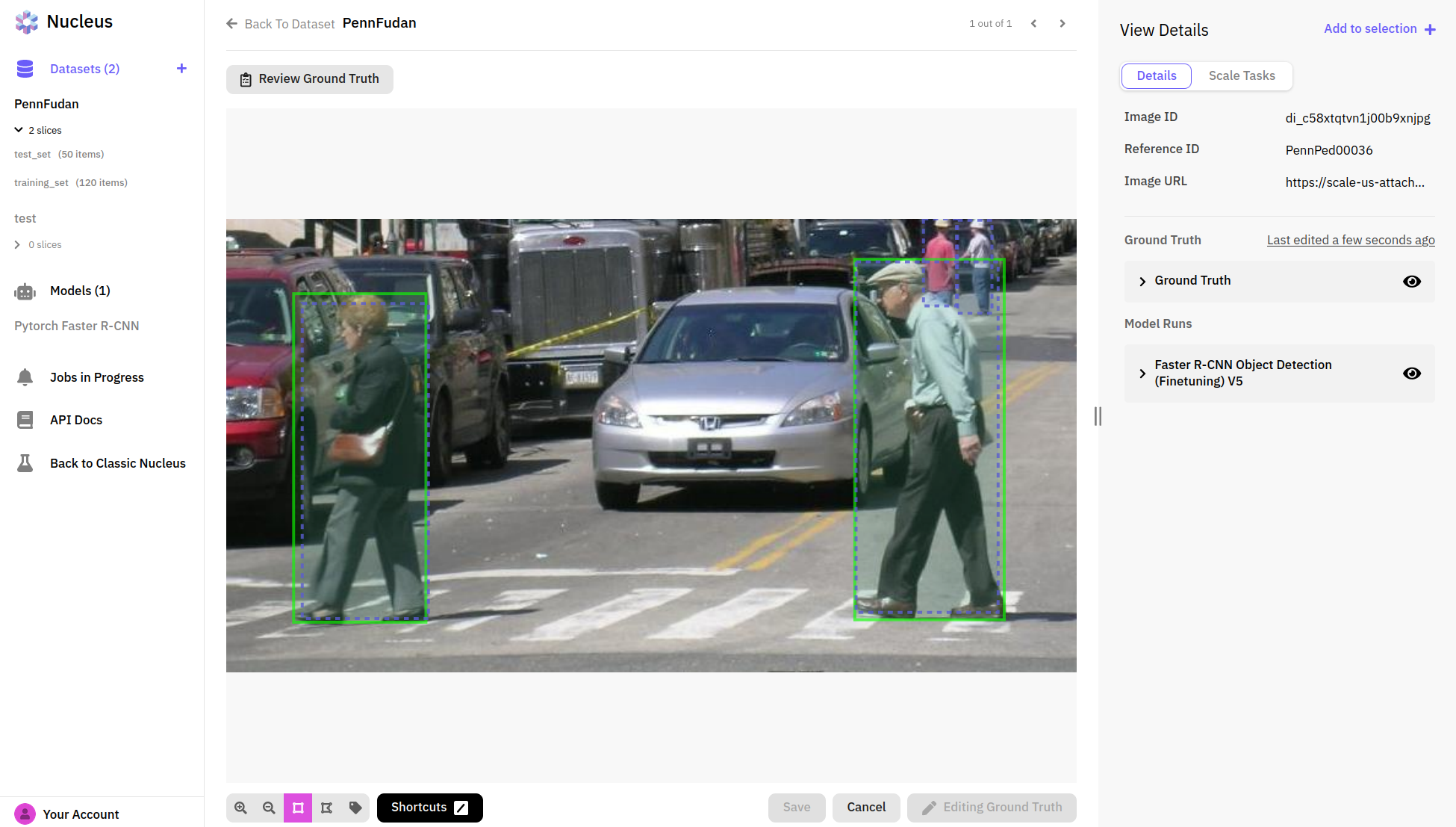
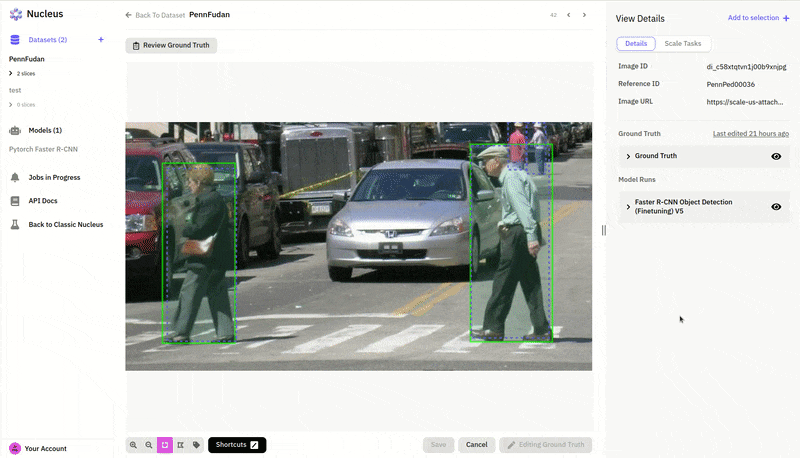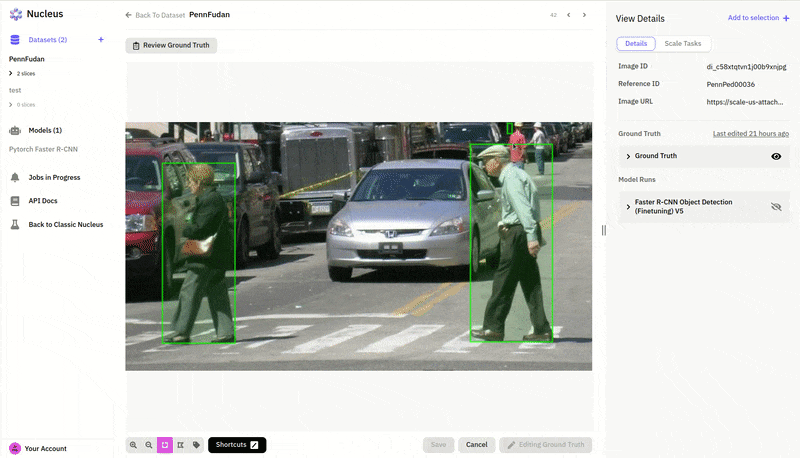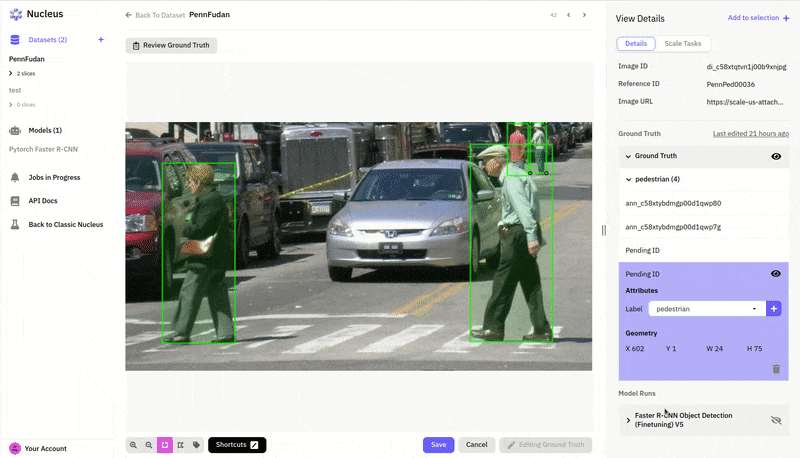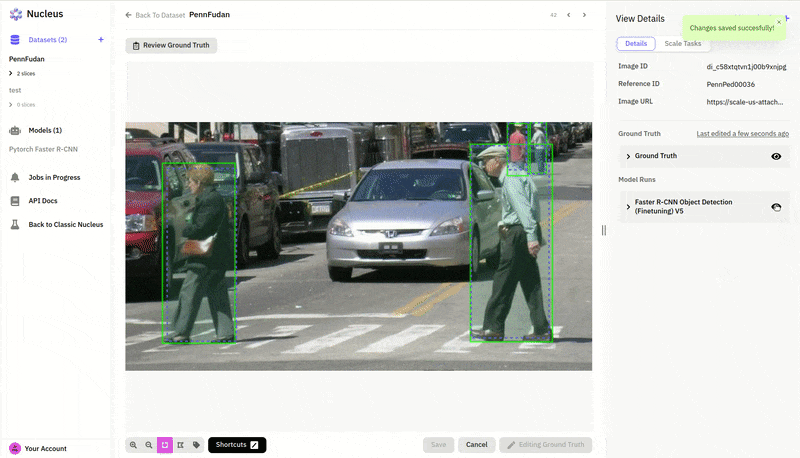
In many cases, it looks like our model is already doing a pretty good job, and it's the ground truth labels that have actually missed some pedestrians! For anyone who has worked on a practical machine learning project, this is probably a familiar story—finding and fixing errors and problems in your dataset is just as much part of deep learning as designing and training models. In this case, we’ll need to go back to our data labels and fix the ground truth errors in order to get a more accurate evaluation of our model. This is also something we can do directly in Nucleus with its convenient annotation tools.
Conclusion
Nucleus is a convenient way to visualize and organize your training data for a machine learning project, as we showed in our object detection example. Most importantly, it makes it easy to inspect and track the predictions from your trained models, and helps you establish the virtuous cycle of training networks, evaluating predictions, identifying failure cases, and improving both data and models: all of these steps prove to be crucial in developing an effective deep learning project.
To learn more about Lambda workstations, check out Lambda’s website, or to get started managing and improving your dataset, sign up for Scale Nucleus here. If you want to try this workflow out on your own Lambda workstation or Lambda GPU Cloud instance, you can explore the example notebook here.


