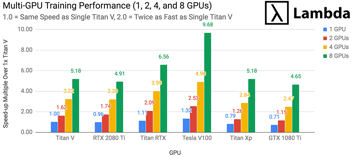
At Lambda, we're often asked "what's the best GPU for deep learning?" In this post and accompanying white paper, we evaluate the NVIDIA RTX 2080 Ti, RTX 2080, GTX 1080 Ti, Titan V, and Tesla V100.
TLDR;
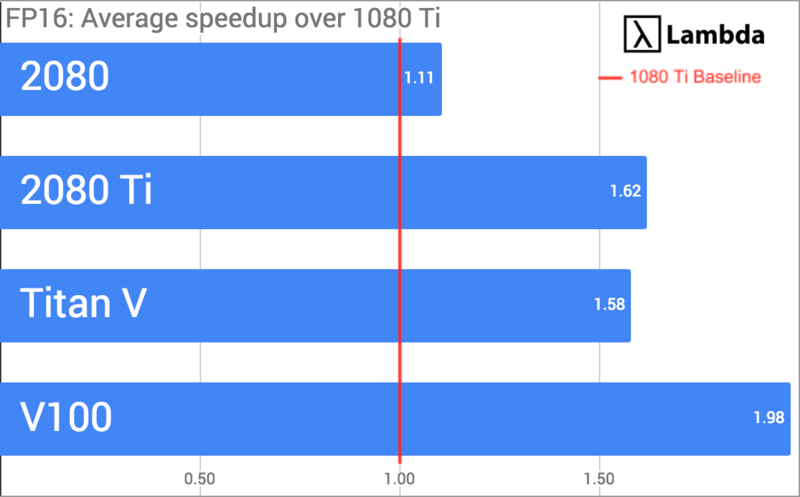
As of February 8, 2019, the NVIDIA RTX 2080 Ti is the best GPU for deep learning. For single-GPU training, the RTX 2080 Ti will be...
- 37% faster than the 1080 Ti with FP32, 62% faster with FP16, and 25% more costly.
- 35% faster than the 2080 with FP32, 47% faster with FP16, and 25% more costly.
- 96% as fast as the Titan V with FP32, 3% faster with FP16, and ~1/2 of the cost.
- 80% as fast as the Tesla V100 with FP32, 82% as fast with FP16, and ~1/5 of the cost.
All experiments utilized Tensor Cores when available and relative cost calculations can be found here. You can view the benchmark data spreadsheet here.
Hardware
A Lambda deep learning workstation was used to conduct benchmarks of the RTX 2080 Ti, RTX 2080, GTX 1080 Ti, and Titan V. Tesla V100 benchmarks were conducted on an AWS P3 instance with an E5-2686 v4 (16 core) and 244 GB DDR4 RAM.
Results in-depth
Performance of each GPU was evaluated by measuring FP32 and FP16 throughput (# of training samples processed per second) while training common models on synthetic data. We divided the GPU's throughput on each model by the 1080 Ti's throughput on the same model; this normalized the data and provided the GPU's per-model speedup over the 1080 Ti. Speedup is a measure of the relative performance of two systems processing the same job.
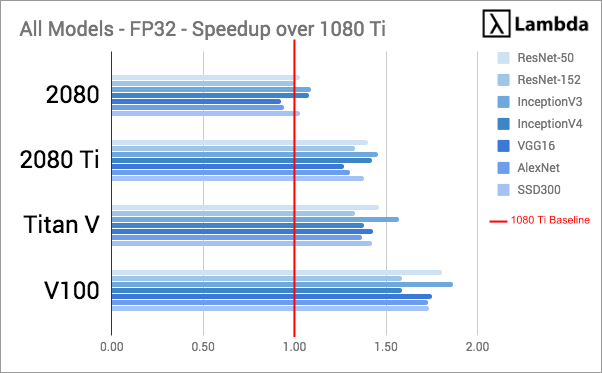
We then averaged the GPU's speedup over the 1080 Ti across all models:
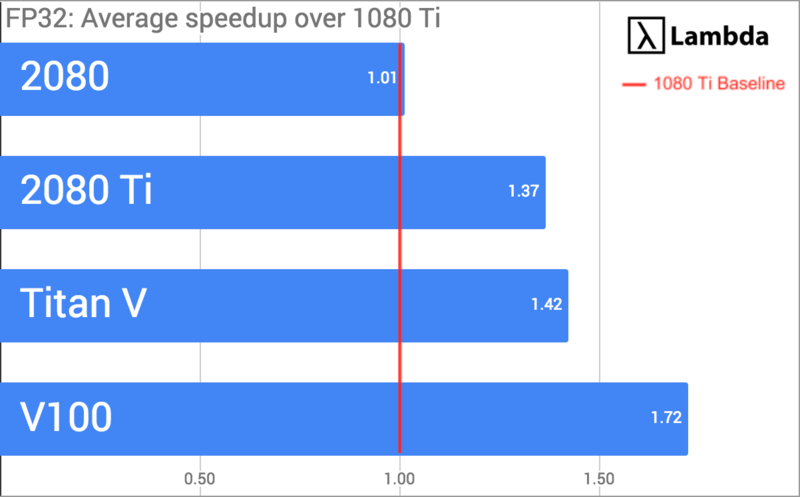
Finally, we divided each GPU's average speedup by the total system cost to calculate our winner:
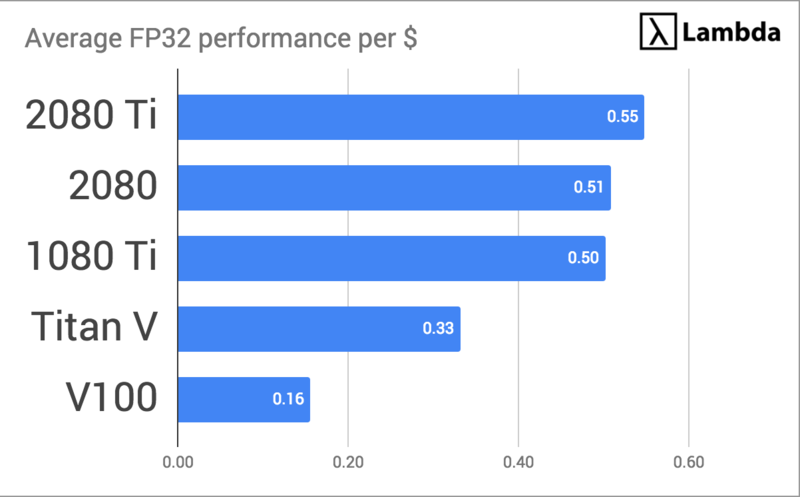
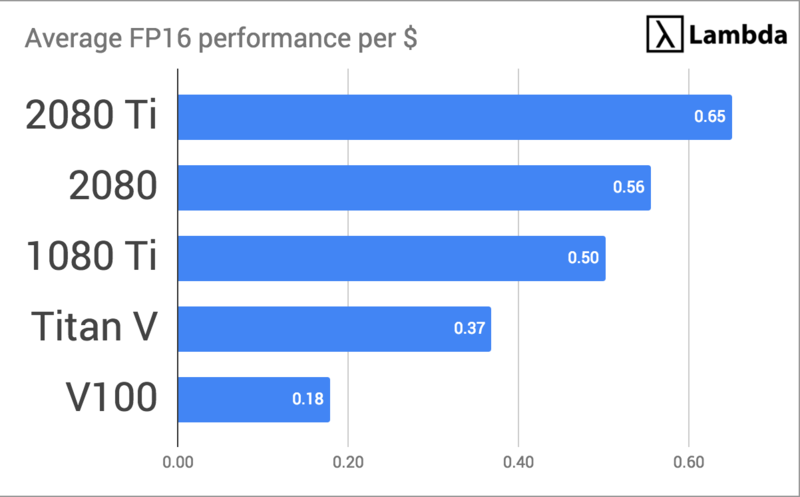
Under this evaluation metric, the RTX 2080 Ti wins our contest for best GPU for Deep Learning training.
2080 Ti vs V100 - is the 2080 Ti really that fast?
How can the 2080 Ti be 80% as fast as the Tesla V100, but only 1/8th of the price? The answer is simple: NVIDIA wants to segment the market so that those with high willingness to pay (hyper scalers) only buy their TESLA line of cards which retail for ~$9,800. The RTX and GTX series of cards still offers the best performance per dollar.
If you're not AWS, Azure, or Google Cloud then you're probably much better off buying the 2080 Ti. There are, however, a few key use cases where the V100s can come in handy:
- If you need FP64 compute. If you're doing Computational Fluid Dynamics, n-body simulation, or other work that requires high numerical precision (FP64), then you'll need to buy the Titan V or V100s. If you're not sure if you need FP64, you don't. You would know.
- If you absolutely need 32 GB of memory because your model size won't fit into 11 GB of memory with a batch size of 1. If you are creating your own model architecture and it simply can't fit even when you bring the batch size lower, the V100 could make sense. However, this is a pretty rare edge case. Fewer than 5% of our customers are using custom models. Most use something like ResNet, VGG, Inception, SSD, or Yolo.
So. You're still wondering. Why would anybody buy the V100? It comes down to marketing.
2080 Ti is a Porsche 911, the V100 is a Bugatti Veyron
The V100 is a bit like a Bugatti Veyron. It's one of the fastest street legal cars in the world, ridiculously expensive, and, if you have to ask how much the insurance and maintenance is, you can't afford it. The RTX 2080 Ti, on the other hand, is like a Porsche 911. It's very fast, handles well, expensive but not ostentatious, and with the same amount of money you'd pay for the Bugatti, you can buy the Porsche, a home, a BMW 7-series, send three kids to college, and have money left over for retirement.
And if you think I'm going overboard with the Porsche analogy, you can buy a DGX-1 8x V100 for $120,000 or a Lambda Blade 8x 2080 Ti for $28,000 and have enough left over for a real Porsche 911. Your pick.
Raw performance data
FP32 throughput
FP32 (single-precision) arithmetic is the most commonly used precision when training CNNs. FP32 data comes from code in the Lambda TensorFlow benchmarking repository.
| Model / GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| ResNet-50 | 209.89 | 286.05 | 298.28 | 368.63 | 203.99 |
| ResNet-152 | 82.78 | 110.24 | 110.13 | 131.69 | 82.83 |
| InceptionV3 | 141.9 | 189.31 | 204.35 | 242.7 | 130.2 |
| InceptionV4 | 61.6 | 81 | 78.64 | 90.6 | 56.98 |
| VGG16 | 123.01 | 169.28 | 190.38 | 233 | 133.16 |
| AlexNet | 2567.38 | 3550.11 | 3729.64 | 4707.67 | 2720.59 |
| SSD300 | 111.04 | 148.51 | 153.55 | 186.8 | 107.71 |
FP16 throughput (Sako)
- FP16 (half-precision) arithmetic is sufficient for training many networks. We use Yusaku Sako benchmark scripts. The Sako benchmark scripts have both FP16 and FP32 results. From here you can clearly see the 2080 Ti beating out the 1080 Ti's FP16 performance.
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 181.2 | 238.45 | 270.27 | 333.33 | 149.39 |
| ResNet-152 | 62.67 | 103.29 | 84.92 | 108.54 | 62.74 |
FP32 (Sako)
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 120.39 | 163.26 | 168.59 | 222.22 | 130.8 |
| ResNet-152 | 43.43 | 75.18 | 61.82 | 80.08 | 53.45 |
FP16 Training Speedup over 1080 ti
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 1.21 | 1.60 | 1.81 | 2.23 | 1.00 |
| ResNet-152 | 1.00 | 1.65 | 1.35 | 1.73 | 1.00 |
FP32 Training Speedup
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 0.92 | 1.25 | 1.29 | 1.70 | 1.00 |
| ResNet-152 | 0.81 | 1.41 | 1.16 | 1.50 | 1.00 |
Price Performance Data (Speedup / $1,000 USD) FP32
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| Price Per GPU (k$) | 0.7 | 1.2 | 3 | 9.8 | 0.7 |
| Price Per 1 GPU System (k$) | 1.99 | 2.49 | 4.29 | 11.09 | 1.99 |
| AVG | 0.51 | 0.55 | 0.33 | 0.16 | 0.50 |
| ResNet-50 | 0.52 | 0.56 | 0.34 | 0.16 | 0.50 |
| ResNet-152 | 0.50 | 0.53 | 0.31 | 0.14 | 0.50 |
| InceptionV3 | 0.55 | 0.58 | 0.37 | 0.17 | 0.50 |
| InceptionV4 | 0.54 | 0.57 | 0.32 | 0.14 | 0.50 |
| VGG16 | 0.46 | 0.51 | 0.33 | 0.16 | 0.50 |
| AlexNet | 0.47 | 0.52 | 0.32 | 0.16 | 0.50 |
| SSD300 | 0.52 | 0.55 | 0.33 | 0.16 | 0.50 |
Price Performance Data (Speedup / $1,000 USD) FP16
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| AVG | 0.56 | 0.65 | 0.37 | 0.18 | 0.50 |
| VGG16 | 0.61 | 0.64 | 0.42 | 0.20 | 0.50 |
| ResNet-152 | 0.50 | 0.66 | 0.32 | 0.16 | 0.50 |
Methods
- All models were trained on a synthetic dataset. This isolates GPU performance from CPU pre-processing performance.
- For each GPU, 10 training experiments were conducted on each model. The number of images processed per second was measured and then averaged over the 10 experiments.
- The speedup benchmark is calculated by taking the images / sec score and dividing it by the minimum image / sec score for that particular model. This essentially shows you the percentage improvement over the baseline (in this case the 1080 Ti).
- The 2080 Ti, 2080, Titan V, and V100 benchmarks utilized Tensor Cores.
Batch sizes used
| Model | Batch Size |
|---|---|
| ResNet-50 | 64 |
| ResNet-152 | 32 |
| InceptionV3 | 64 |
| InceptionV4 | 16 |
| VGG16 | 64 |
| AlexNet | 512 |
| SSD | 32 |
Hardware
All benchmarks, except for those of the V100, were conducted using a Lambda Vector with swapped GPUs. The exact specifications are:
- RAM: 64 GB DDR4 2400 MHz
- Processor: Intel Xeon E5-1650 v4
- Motherboard: ASUS X99-E WS/USB 3.1
- GPUs: EVGA XC RTX 2080 Ti GPU TU102, ASUS 1080 Ti Turbo GP102, NVIDIA Titan V, and Gigabyte RTX 2080.
Software
All benchmarks, except for those of the V100, were conducted with:
- Ubuntu 18.04 (Bionic)
- CUDA 10.0
- TensorFlow 1.11.0-rc1
- cuDNN 7.3
The V100 benchmark was conducted with an AWS P3 instance with:
- Ubuntu 16.04 (Xenial)
- CUDA 9.0
- TensorFlow 1.12.0.dev20181004
- cuDNN 7.1
How we calculate system cost
The cost we use in our calculations is based on the estimated price of the minimal system that avoids CPU, memory, and storage bottlenecking for Deep Learning training. Note that this won't be upgradable to anything more than 1 GPU.
- CPU: i7-8700K or equivalent (6 cores, 16 PCI-e lanes). ~$380.00 on Amazon.
- CPU Cooler: Noctua L-Type Premium. ~$50 on Amazon.
- Memory: 32 GB DDR4. ~$280.00 on Amazon.
- Motherboard: ASUS Prime B360-Plus (16x pci-e lanes for GPU). ~$105.00 on Amazon.
- Power supply: EVGA SuperNOVA 750 G2 (750W). ~$100.00 on Amazon.
- Case:NZXT H500 ATX case ~$70.00 on Amazon
- Labor: About $200 in labor if you want somebody else to build it for you.
Cost (excluding GPU): $1,291.65 after 9% sales tax.
Reproduce the benchmarks yourself
All benchmarking code is available on Lambda Lab's GitHub repo. Share your results by emailing s@lambdalabs.com or tweeting @LambdaAPI. Be sure to include the hardware specifications of the machine you used.
Step One: Clone benchmark repo
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
Step Two: Run benchmark
- Input a proper gpu_index (default 0) and num_iterations (default 10)
cd lambda-tensorflow-benchmark
./benchmark.sh gpu_index num_iterations
Step Three: Report results
- Check the repo directory for folder <cpu>-<gpu>.logs (generated by benchmark.sh)
- Use the same num_iterations in benchmarking and reporting.
./report.sh <cpu>-<gpu>.logs num_iterations
We are now taking orders for the Lambda Blade 2080 Ti Server and the Lambda Quad 2080 Ti workstation. Email enterprise@lambdalabs.com for more info.
You can download this blog post as a whitepaper using this link: Download Full 2080 Ti Performance Whitepaper.