
TLDR
While waiting for NVIDIA's next-generation consumer and professional GPUs, we decided to write a blog about the best GPU for Deep Learning currently available as of March 2022. For readers who use pre-Ampere generation GPUs and are considering an upgrade, these are what you need to know:
- Ampere GPUs have significant improvement over pre-Ampere GPUs based on the
throughputandthroughput-per-dollarmetrics. This is especially true for language models, where Ampere Tensor Cores can leverage structured sparsity. - Ampere GPUs do not offer a significant upgrade on memory. For example, if you have a
Quadro RTX 8000from the Turing generation, upgrading it to its Ampere successor theA6000would not enable you to train a larger model. - Three Ampere GPU models are good upgrades:
A100 SXM4for multi-node distributed training.A6000for single-node, multi-GPU training.3090is the most cost-effective choice, as long as your training jobs fit within their memory. - Other members of the Ampere family may also be your best choice when combining performance with budget, form factor, power consumption, thermal, and availability.
The above claims are based on our benchmark for a wide range of GPUs across different Deep Learning applications. Without further ado, let's dive into the numbers.
Ampere or not Ampere
First, we compare Ampere and pre-Ampere GPUs in the context of single GPU training. We hand picked a few image and language models and focus on three metrics:
- Maximum Batch Size: This is the largest number of samples that can be fit into the GPU memory. We usually prefer GPUs that can accommodate larger batch size, because they lead to more accurate gradients for each optimization step and are more future-proved for larger models.
- Throughput: This is the number of samples that can be processed per second by a GPU. We measure the throughput for each GPU with its own maximum batch size to avoid GPU starving (GPU cores stay idle due to lack of data to be processed).
- Throughput-per-dollar: This is the throughput of a GPU normalized by the market price of the GPU. It reflects how "cost-effective" the GPU is regarding the computation/purchase price ratio.
We give detailed numbers for some GPUs that are popular choices we've seen from the Deep Learning community. We include both the current Ampere generation ( A100, A6000, and 3090) and the previous Turing/Volta generation (Quadro RTX 8000, Titan RTX, RTX 2080Ti, V100) for readers who are interested in comparing their performance and considering an upgrade in the near future. We also include the 3080 Max-Q since it is one of the most powerful mobile GPUs currently available.
Maximum batch size
| Model / GPU | A100 80GB SXM4 | RTX A6000 | RTX 3090 | V100 32GB | RTX 8000 | Titan RTX | RTX 2080Ti | 3080 Max-Q |
|---|---|---|---|---|---|---|---|---|
| ResNet50 | 720 | 496 | 224 | 296 | 496 | 224 | 100 | 152 |
| ResNet50 FP16 | 1536 | 912 | 448 | 596 | 912 | 448 | 184 | 256 |
| SSD | 256 | 144 | 80 | 108 | 144 | 80 | 32 | 48 |
| SSD FP16 | 448 | 288 | 140 | 192 | 288 | 140 | 56 | 88 |
| Bert Large Finetune | 32 | 18 | 8 | 12 | 18 | 8 | 2 | 4 |
| Bert Large Finetune FP16 | 64 | 36 | 16 | 24 | 36 | 16 | 4 | 8 |
| TransformerXL Large | 24 | 16 | 4 | 8 | 16 | 4 | 0 | 2 |
| TransformerXL Large FP16 | 48 | 32 | 8 | 16 | 32 | 8 | 0 | 4 |
No surprise, the maximum batch size is closely correlated with GPU memory size. A100 80GB has the largest GPU memory on the current market, while A6000 (48GB) and 3090 (24GB) match their Turing generation predecessor RTX 8000 and Titan RTX. The 3080 Max-Q has a massive 16GB of ram, making it a safe choice of running inference for most mainstream DL models. Released three and half years ago, RTX 2080Ti (11GB) could cope with the state-of-the-art image models at the time but is now falling behind. This is especially the case for someone who works on large image models or language models (can't fit a single training example for TransformerXL Large in either FP32 or FP16 precision).
We also see a roughly 2x of maximum batch size when switching the training precision from FP32/TF32 to FP16.
Throughput
| Model / GPU | A100 80GB SXM4 | RTX A6000 | RTX 3090 | V100 32GB | RTX 8000 | Titan RTX | RTX 2080Ti | 3080 Max-Q |
|---|---|---|---|---|---|---|---|---|
| ResNet50 | 925 | 437 | 471 | 368 | 300 | 306 | 275 | 193 |
| ResNet50 FP16 | 1386 | 775 | 801 | 828 | 646 | 644 | 526 | 351 |
| SSD | 272 | 135 | 137 | 136 | 116 | 119 | 106 | 55 |
| SSD FP16 | 420 | 230 | 214 | 224 | 180 | 181 | 139 | 90 |
| Bert Large Finetune | 60 | 25 | 17 | 12 | 11 | 11 | 6 | 7 |
| Bert Large Finetune FP16 | 123 | 63 | 47 | 49 | 41 | 40 | 23 | 20 |
| TransformerXL Large | 12847 | 6114 | 4062 | 2329 | 2158 | 1878 | 0 | 967 |
| TransformerXL Large FP16 | 18289 | 11140 | 7582 | 4372 | 4109 | 3579 | 0 | 1138 |
Throughput is impacted by both GPU cores, GPU memory, and memory bandwidth. Imagine you are in a restaurant: memory bandwidth decides how fast food is brought to your table, memory size is your table size, GPU cores decide how fast you can eat. The amount of food consumed in a fixed amount of time (training/inference throughput) could be blocked by any one of or multiple of these three factors. But most likely, how fast you can eat (the cores).
Overall, we see Ampere GPUs deliver a significant boost of throughput compared to their Turing/Volta predecessors. For example, lets examine the current flag ship GPU A100 80GB SXM4.
For image models (ResNet50 and SSD):
2.25xfaster thanV100 32GBin 32-bit (TF32forA100andFP32forV100)1.77xfaster thanV100 32GBinFP16
For language models (Bert Large and TransformerXL Large):
5.26xfaster thanV100 32GBin32-bit(TF32forA100andFP32forV100)3.35xfaster thanV100 32GBinFP16
While a performance boost is guaranteed by switching to Ampere, the most significant improvement comes from training language models in TF32 v.s. FP32 where the latest Ampere Tensor Cores leverage structured sparsity. So if you are training language models on Turing/Volta or even an older generation of GPUs, definitely consider upgrading to Ampere generation GPUs.
Throughput per Dollar
| Model / GPU | A100 80GB SXM4 | RTX A6000 | RTX 3090 | V100 32GB | RTX 8000 | Titan RTX | RTX 2080Ti | 3080 Max-Q |
|---|---|---|---|---|---|---|---|---|
| ResNet50 TF32/FP32 | 0.05 | 0.075 | 0.15 | 0.03 | 0.04 | 0.09 | 0.14 | 0.12 |
| ResNet50 FP16 | 0.075 | 0.134 | 0.255 | 0.073 | 0.094 | 0.184 | 0.273 | 0.219 |
| SSD TF32/FP32 | 0.015 | 0.023 | 0.044 | 0.012 | 0.017 | 0.034 | 0.055 | 0.034 |
| SSD FP16 | 0.027 | 0.04 | 0.068 | 0.02 | 0.026 | 0.052 | 0.072 | 0.056 |
| Bert Large Finetune TF32/FP32 | 0.0032 | 0.0043 | 0.0054 | 0.001 | 0.0016 | 0.0031 | 0.0031 | 0.0043 |
| Bert Large Finetune FP16 | 0.0066 | 0.0109 | 0.0150 | 0.0043 | 0.0059 | 0.01143 | 0.01193 | 0.0125 |
| TransformerXL Large TF32/FP32 | 0.69 | 1.06 | 1.29 | 0.21 | 0.31 | 0.54 | 0 | 0.60 |
| TransformerXL Large FP16 | 0.98 | 1.93 | 2.41 | 0.38 | 0.60 | 1.02 | 0 | 0.71 |
Throughput per dollar is somewhat an over-simplified estimation of how cost-effective a GPU is since it does not include the cost of operating (time and electricity) the GPU. Frankly speaking, we didn't know what to expect, but when we tested, we found two interesting trends:
- Ampere GPUs have an overall increase of Throughput per dollar over Turing/Volta. For example,
A100 80GB SXM4has higher Throughput per dollar thanV100 32GBfor ALL the models above. The same toA6000and3090when compared withRTX 8000andTitan RTX. This suggests that upgrading your old GPUs to the newest generation is a wise move. - Among the latest generation, lower-end GPUs usually have higher throughput per dollar than higher-end GPUs. For example,
3090>A6000>A100 80GB SXM4. This means, if you are budget limited, buying lower-end GPUs in quantity might be a better choice than chasing the pricey flagship GPU.
You can find "Throughput per Watt" from our benchmark website. Take these metrics as a grain of salt since the value of time/watt can be entirely subjective (how complicated is your problem? how tolerant are you to time/electricity bills). Nonetheless, for users who demand fast R&D iterations, upgrading to Ampere GPUs seems to be a very worthwhile investment, as you will save lots of time in the long term.
Scalability
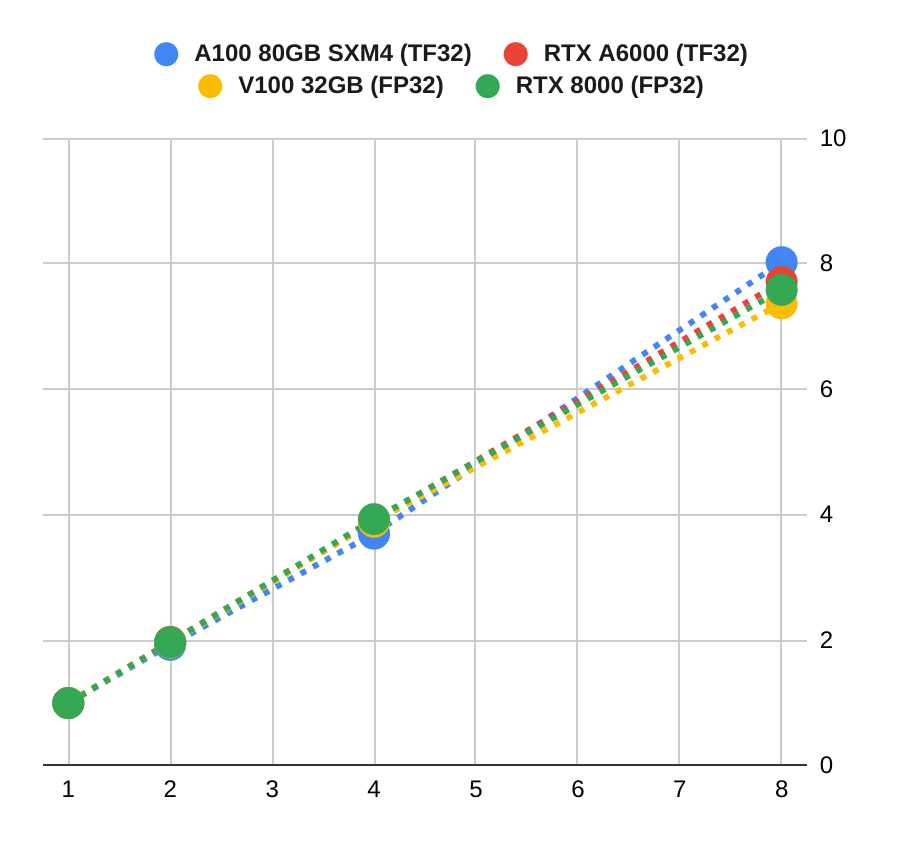
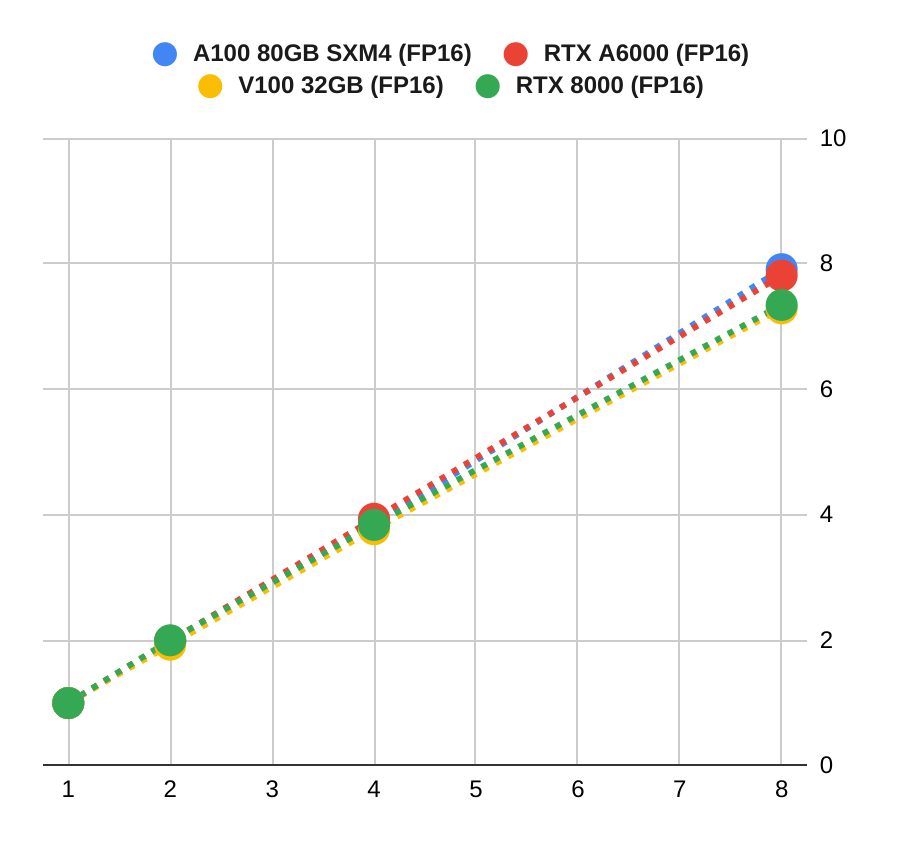
We also tested the scalability of these GPUs with multi-GPU training jobs. We observed nearly perfect linear scale for A100 80GB SXM4 (blue line), thanks to the fast device-to-device communication of NVSwitch. Other server-grade GPUs, including A6000, V100, and RTX 8000, all scored high scaling factors. For example, A6000 delivered 7.7x and 7.8x performance with 8x GPUs in TF32 and FP16, respectively.
We didn't include them in this graph, but the scaling factors for Geforce cards are significantly worse. For example, 3090 delivered only about 5x more throughput with 8x GPUs. This is mainly due to the fact that GPUDirect Peering is disabled on the latest generations of Geforce cards so communication between GPUs (to gather the gradients) must go through CPUs, which leads to severe bottlenecks as the number of GPUs increases.
We observed that4x Geforce GPUs could give a 2.5x-3x speed up, depending on the hardware setting and the problem at hand. And it appears to be inefficient to go beyond 4x GPUs with Geforce cards.
More GPUs
The above analysis used a few hand-picked image & language models to compare popular choices of GPUs for Deep Learning. You can find more comprehensive comparisons from our benchmark website. The following two figures give a high-level summary of our studies on the relative performance of a wider range of GPUs across a more extensive set of models:
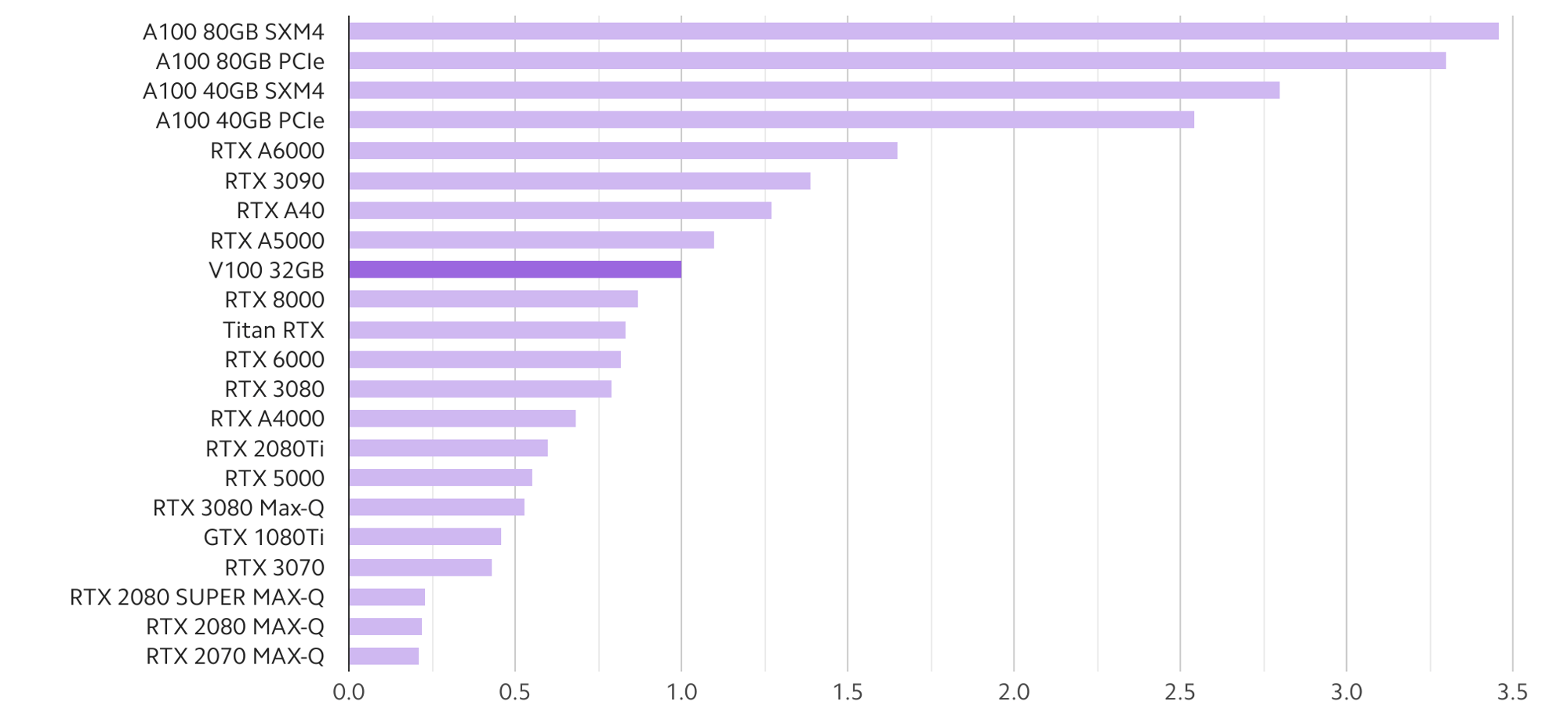
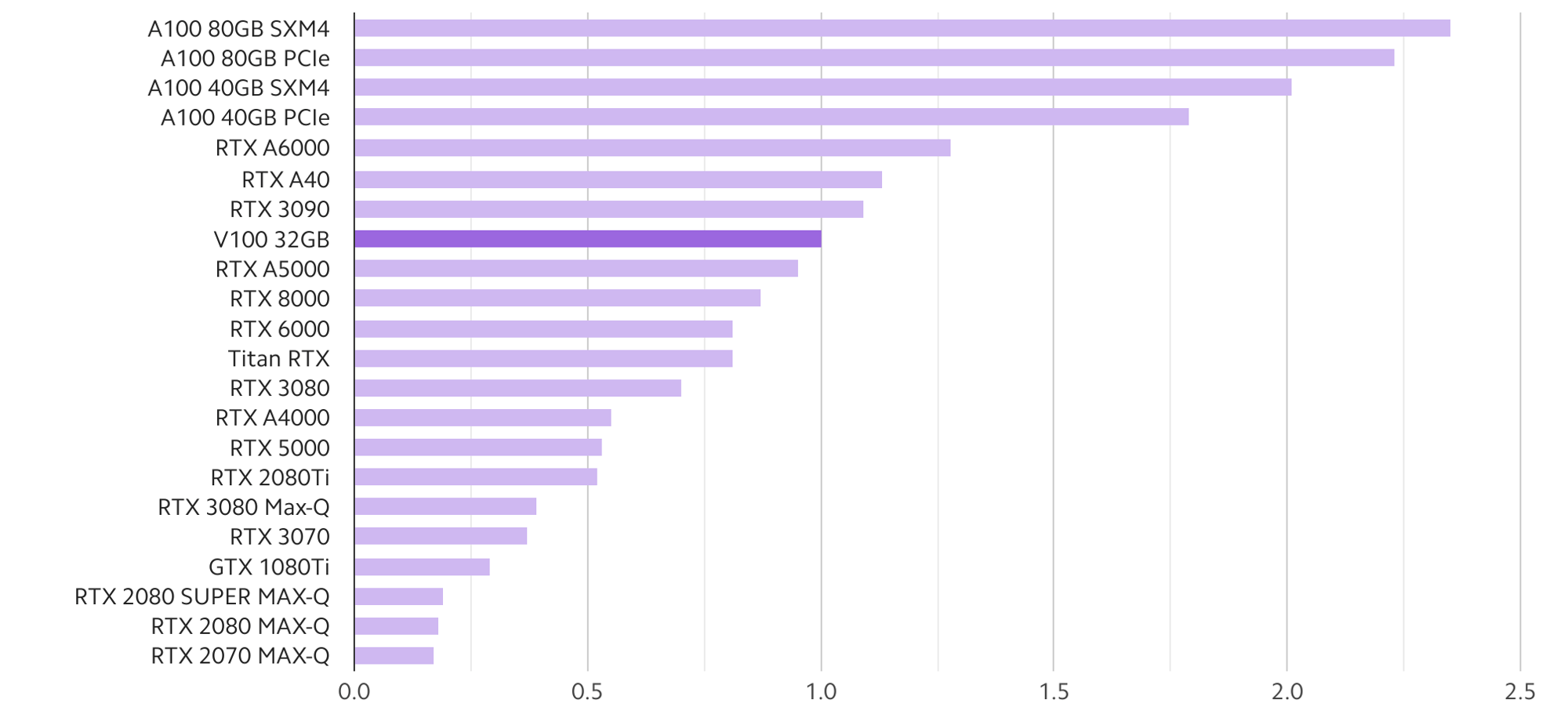
The models used in the above studies include:
- Computer Vision: ResNet50, SSD, Mask-RCNN
- Language: GNMT, TransformXL-base, TransformXL-large, BERT-base, BERT-large
- Speech Synthesis: Tacotron2, Waveglow
- Recommendation System: NCF
The A100 family (80GB/40GB with PCIe/SMX4 form factors) has a clear lead over the rest of the Ampere Cards. A6000 comes second, followed closely by 3090, A40, and A5000. There is a large gap between them and the lower tier 3080 and A4000, but their prices are more affordable.
GPU recommendation
So, which GPUs to choose if you need an upgrade in early 2022 for Deep Learning? We feel there are two yes/no questions that help you choose between A100, A6000, and 3090. These three together probably cover most of the use cases in training Deep Learning models:
- Do you need multi-node distributed training? If the answer is yes, go for
A100 80GB/40GBSXM4because they are the only GPUs that supportInfiniband. WithoutInfiniband, your distributed training simply would not scale. If the answer is no, see the next question. - How big is your model? That helps you to choose between
A100 PCIe(80GB),A6000(48GB), and3090(24GB). A couple of3090s are adequate for mainstream academic research. ChooseA6000if you work with a large image/language model and need multi-GPU training to scale efficiently. AnA6000system should cover most of the use cases in the context of a single node. Only chooseA100 PCIe 80GBwhen working on extremely large models
Of course, options such as A40, A5000, 3080, and A4000 may be your best choice when combining performance with other factors such as budget, form factor, power consumption, thermal, and availability.
For example, power consumption and thermals can be an issue when you use multiple of 3090s (360 watts) or 3080s (350 watts) in a workstation chassis, and we recommend no more than three of these cards for workstations. In contrast, although A5000 (also 24GB) is up to 20% slower than 3090, it consumes much less power (only 230 watts) and offers better thermal performance, which allows you to create a higher performance system with four cards.
Still having problem identifying the best GPU for your needs? Feel free to start a conversation with our engineers for recommendations.
PyTorch benchmark software stack
Note: The GPUs were tested using NVIDIA PyTorch containers. Pre-ampere GPUs were tested with pytorch:20.01-py3. Ampere GPUs were benchmarked using pytorch:20.10-py3 or newer. While the performance impact of testing with different container versions is likely minimal, for completeness we are working on re-testing a wider range of GPUs using the latest containers and software. Stay tuned for an update.
Lambda's PyTorch benchmark code is available at the GitHub repo here.


